Design Uber Backend
Design Uber Backend
Let’s design the backend for a ride-sharing service like Uber. The goal of this system is to connect passengers who need rides with drivers who have a car.
What is a ride-sharing service?
Let’s use a real world example, like Uber, as most ride-sharing services are pretty similar. Uber allows customers to book taxi rides from their phone, the thing is all the taxi drivers own their own vehicles which they use to ferry passengers around for a fee. Uber’s system allows both the passenger and driver to communicate with each other.
System Requirements
As previously mentioned, ride-sharing systems must have interfaces to accommodate passengers and drivers, let’s design our system around these 2 types of users.
Passenger -
- A passenger must have the ability to see all nearby drivers.
- Passenger must be able to request a ride.
- Passenger payment information must be stored safely and accessed for paying fare.
Driver -
- Driver’s availability is key and a method must be devised to notify service of driver’s availability regularly.
- A driver must be notified when a nearby passenger is ready to be picked up.
- After reaching the final destination, the driver should be able to mark the journey complete to become available once again.
With a system as complex as a ride-sharing app there are also many design goals we must meet to ensure we have a robust system:
- Latency is key for this app, since tracking driver location in realtime is such a crucial feature we must ensure latency is always good.
- Consistency is also a huge concern, great care must be taken to ensure that data is the same for all users. A simple example would be for different users to all see the number of cabs in a certain area.
- How do we handle server failures or loss of data?
- Availability is also a huge concern, but we may need to tradeoff latency or consistency to ensure availability is high.
- What technologies can we use to establish horizontal scalability.
These are some of the main considerations to take into account for this system.
Estimation & Constraints
Estimation is just a guesstimate at best, try to have realistic numbers for the system you’re designing for.
- Let’s assume our system has 100M customers and 500k drivers with 1M daily customers and 250k daily drivers.
- Let’s assume 500k rides take place daily.
Constraints are an important consideration in any large system, here are a few to consider with the ride-sharing service:
- What happens when multiple customers book the same driver?
- How many bookings can our system handle per second?
- When a customer books a cab, they should have realtime access to their driver on the app’s map.
- How often will driver be notifying system of their availability?
System Design & Algorithm Overview
One of the first problems we can tackle is how to query location data quickly and accurately, we need to think about how we can narrow down on a specific location on a map. By dividing a world map into smaller grids we can store all the places within a specific range of longitude and latitude. The advantage of this approach is that we can look into one specific grid to query a driver’s location, this significantly reduces overhead.
So with the visual aid hopefully you can understand how we plan on splitting the data up to be queried faster, this helps segue into the next issue.
The second problem we can tackle is the issue of tracking the drivers location, we need a data structure that can put up with being updated every few seconds with new driver location data. An intuitive data structure we can use is called a quad tree. A quad tree is a tree structure in which all of its nodes have four children. The advantage we get from this is we can store a grid(s) in one node and then dig deeper to narrow down on a specific location within the node’s children.

A problem that can quickly arise is if frequent updates made to our quad tree it would prove very expensive memory-wise, but at the same time, keeping up-to-date information is key to accurately displaying the drivers location. We need a way to store driver location but also not overload the servers with update requests from potentially thousands of drivers at a given time.
Luckily there is a way, we can utilize a hash table to store the drivers current location initially, then after a certain amount of time has passed (15-20 seconds) we can then commit the new location data directly to the quad tree. We can call this DriverPositionHT .
Let’s look at what kind of data our hash table will store, and how much memory it will take to do so:
DriverPositionHT:
- DriverId (4 bytes)
- Old Latitude (10 bytes)
- Old Longitude (10 bytes)
- New Latitude (10 bytes)
- New Longitude (10 bytes)
44 bytes = 4 + 10 + 10 + 10 + 10
Let’s assume we have 1 million users for our ride-sharing app, so the total overhead would be:
1 million * 44 bytes = 44 MB
So now we have a better idea of how much data a full entry for a driver holds, now we must consider how much bandwidth we need to update the drivers entry every 3 seconds.
All we need for the updates are the DriverId, new latitude and longitude, let’s do the math:
4 + 10 + 10 = 24 bytes
1 million * 24 bytes = 24 MB
We will need at least 24 MB every 3 seconds to handle all the driver location updates.
Should the DriverPositionHT be distributed on multiple servers? Ideally, yes. Distribution allows us to remove single points of failure, improves performance and allows the system to scale better.
The driver location server will have 2 responsibilities:
- The server needs to communicate with the quad tree server to update the drivers location. As previously mentioned, this can happen every 15 seconds.
- After receiving the updated drivers location the server will alert the customer.
Great, so now we have a distributed driver location server but we need to take the broadcasted driver location data and efficiently return it to the customers.
What is the best way to deliver the updated driver location to customers? We will need to have a notification service of sorts that will take location data and return it to customers. This server will need to follow the publisher/subscriber model, which means we need to subscribe customers to location updates from a specific driver(s). A list of customers may subscribe to a drivers location and whenever we have to update the DriverLocationHT for that driver, we then notify all subscribed customers to that drivers location.
One of the most efficient methods of implementing the notification service is to use long polling or push notifications to notify subscribed users, this holds the server request open until new data comes through. If you wanted to rely on some sort of service to help with this issue, Kafka could be a good alternative as it is a publisher/subscriber message based system that is very scaleable.
How much memory do we need to deal with all the customer/driver subscriptions? Since we estimate 1 million customers and 250k drivers daily we can use this information to calculate the necessary memory we need to handle the subscriptions. Let’s assume that on average a driver will have up to five customers subscribing to them. We can store this information in a hash table. Let’s say that the DriverID and ClientID are both 4 bytes, and for every driver we have five clients, and there are 500k daily active drivers, lets do the math:
(500k * 4) + (500k * 5 * 4) = 12 MB
How much bandwidth is needed to notify subscribed customers of the drivers location? Since we have, on average, five subscribers per driver, the total will be:
(500k * 5) = 2.5 MB
The subscribers need to get the driver’s location so the data sent back will be the DriverID (4 bytes) and their location (20 bytes), so this will be our estimated bandwidth:
2.5 MB * 24 bytes = 60 MB/s
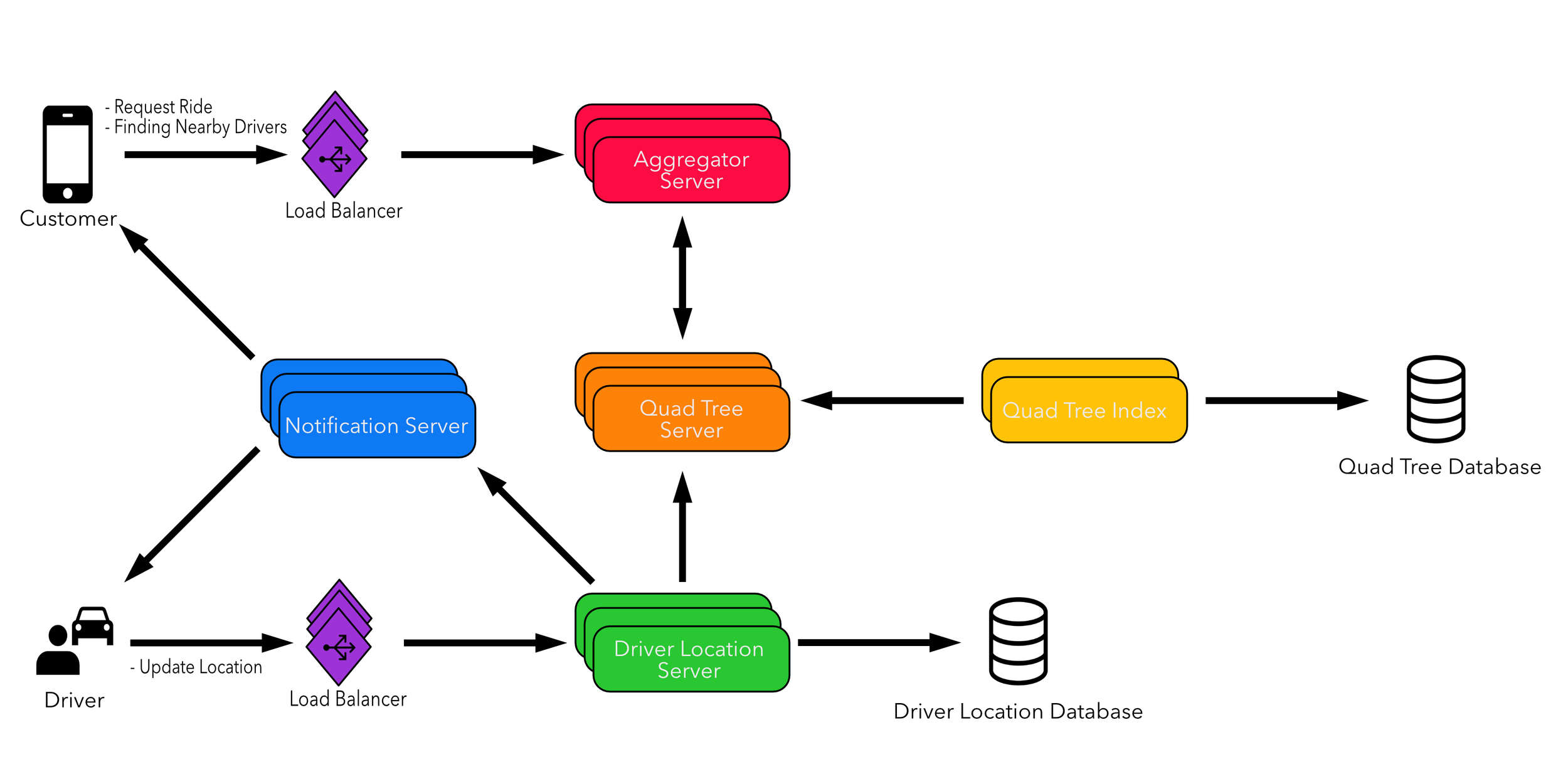
Now for the most crucial feature:
How does the “request a ride” feature work? Here is a step by step walkthrough on how the feature might work:
- The customer will request a ride through the app.
- The aggregator server takes the request to the quad tree servers and returns nearby drivers.
- The aggregator server will send notifications to the batch of nearby drivers, whichever driver accepts the customers request will be assigned the ride. After a ride has been assigned then the rest of the drivers will receive a cancellation request.
- After a driver accepts a request, the customer is notified.
Load Balancing
This is a go-to tactic for big systems and will be helpful in handling the abundance of traffic we can expect with our ride-sharing app. We can maintain two load balancers for this system, both placed after the customer and driver, but before their request hits the aggregation and driver location servers, respectively.
Our server needs a method to route all incoming requests, the simplest would be to use round robin approach. This method, however, can have its downsides as well. While a simple round robin approach would initially work, ideally, we would want to use a more intelligent variation of the round robin in which it can perform health checks on non-functioning servers, to avoid server overload.
Replication & Fault Tolerance
When designing distributed systems we need to take into consideration if one, or many servers fail. The most straightforward way of accomplishing this is to replicate servers, so they act as backups incase the first one fails. Another option is we can make use of SSD’s to store data from our servers, the benefit of this is if all of our servers fail we can just recover the data from the SSD.
Other Concerns
- How do we handle bad network connections while using the app?
- How do we handle billing if the client or driver disconnects (by poor connection or otherwise) after a ride request has been accepted?
Design Auto Suggestion Feature
Design an Auto Suggestion feature
Our goal is to build a feature that will recommend search terms to the user in real-time while they’re typing. Think about Google’s search bar when you type a search query, that is what we’re going for.
What is Auto suggestion?
As the name indicates, auto suggestion will recommend search terms that are relevant or frequently searched while the user types. This is done by trying to predict the rest of the search query in the search bar based on the existing text. Auto suggestion is a powerful tool that helps users articulate their searches better so that they can find what they are looking for faster.
System Requirements
For this design, let’s start with a couple requirements, both functional and non-functional.
Functional Requirement - While typing, the user should be presented with at least 10 search query suggestions based off their current search in real-time.
Non-functional Requirement - We need the suggestions to appear in real-time, so we need to be able to see suggestion after 250ms at most.
Initial Design
As you’ve probably already been thinking, the main chokepoint for this feature is the amount of possible string combinations we can deal with when searching. Since this feature will be used in the context of a general search engine, there are billions of potential combinations the user could face.
We need to design a solution that can help us narrow down our results based on the prefix, which are the words currently in our search bar. For instance, imagine we have a database with the search terms: can, car, cart, cat, cater, if the user searches ‘car’ we can expect the results ‘car’ and ‘cart’ to appear.
The example mentioned a database, but that would not be the ideal route, we have an abundance of potential combinations but we also need to fetch the suggestions as quick as possible. We need a way to store our word data but also have have quick access to it. This feature requires the use of a highly efficient, specialized data structure to help fulfill our needs.
Luckily, there is a data structure that will work quite well for our implementation. A Trie (pronounced “try”) is a tree-like data structure that is best used for storing strings, this is accomplished by storing one character at each node. The strength of the trie shines through when dealing with a lot of related words, since the path of characters will be shared until one of the phrases diverge. For example, the words “cat” and “car” will both share “c” and “a” but then will diverge into a “t” and “r” node for each word, respectively. This feature of the trie gives us a lot of possibilities, and will beneficial in efficiently storing similar words, which is why it is the perfect data structure for our use case.
Below is a visual representation of our example in a trie data structure:
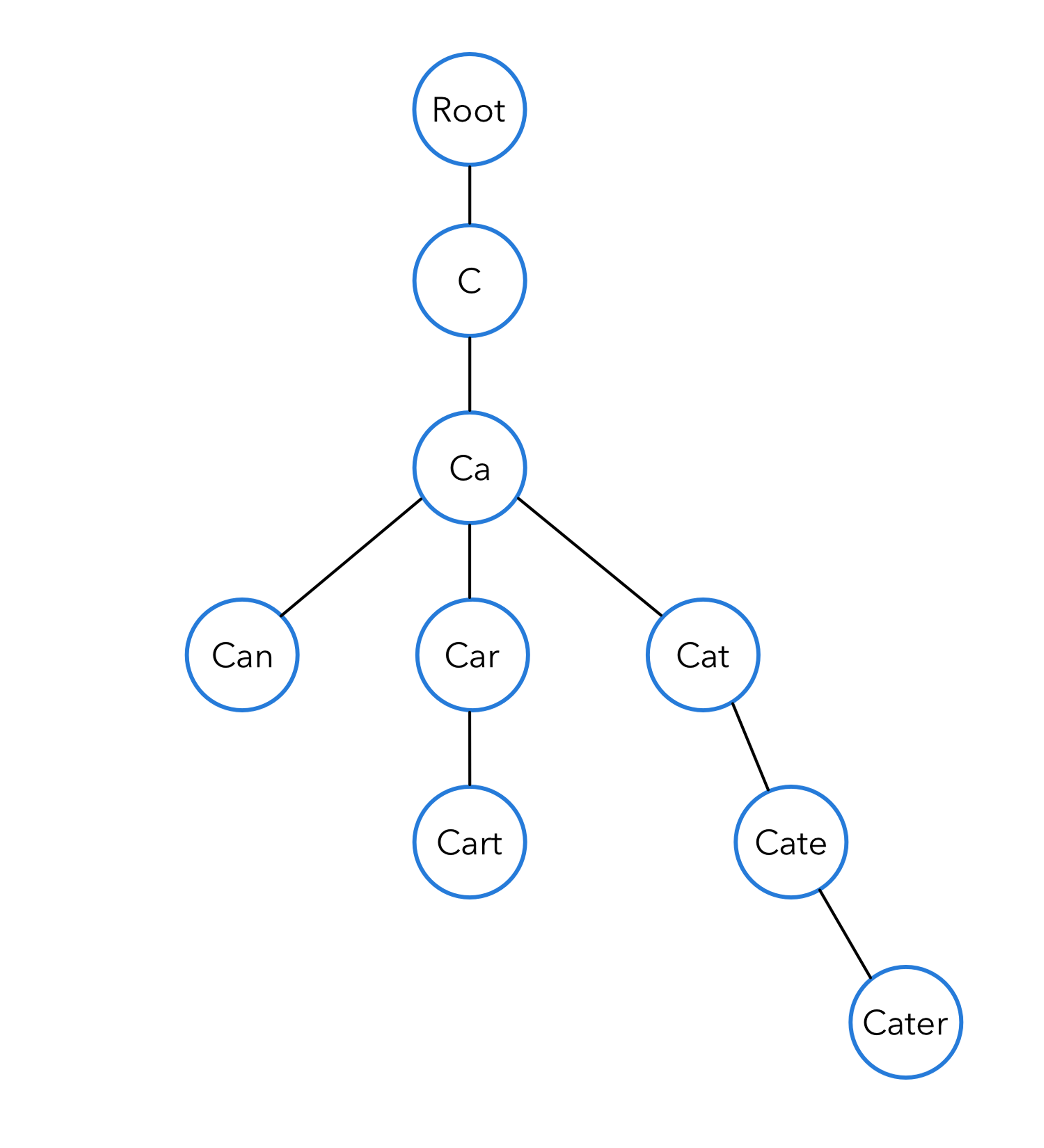
As a small improvement, we may merge nodes together into one node after diverging, this will save on memory. Imagine the tree above but the phrase “cater” stored as “c”, “a” and finally the suffix “ter” as one node.
Trie In-depth
So now that we’ve settled on a trie for our feature we need to understand and clarify how the trie will fit into our overall system, here are some questions we might have:
Is our trie case sensitive? - We can assume our data will be case insensitive.
How can we store the top searched queries? - Every time a phrase is searched for we can store a counter indicating how many times that specific query has been searched for, this count will be stored at the end of each node.
What is the time complexity of traversing our trie(s)? - Given the amount of characters we need to index and then search through when typing, not too great. Imagine a user typing long tail phrase, a query over 25 characters long, we would have to traverse 25 levels of our trie. The runtime for traversing our trie is: O(l) + O(n) + k(log k) . This can be broken down like so: O(l) represents the length of the prefix, O(n) represents the number of prefixes searched for that query and k(log k) is for the time it took to sort the trie, as well as the top k suggestion we show to the user. The downside of this approach however is that we need an increased amount of space in our tries to not only store suggestions but also top searches. That being said, we can still improve the runtime.
How do we build our trie with suggestions? - We build the nodes from the bottom up, as we recurse upwards at each node computing all the valid prefixes that are the children of the current node, we can this the data and apply it to a prefix hash table, the idea is to store prefixes as a key and an array of suggestions for that key, that way when the user is typing we can quickly return all appropriate suggestions with the current text in search bar. The advantage of using the hash table is it will allow quick lookups as the user is typing as we can just query the values for a specific prefix, thus improving runtime.
Where can we put our tries? - Initially we can put our tries in a server that will keep track of them. The tries now have a place to be stored and we can search this server with a given prefix from the user.
How can we keep our trie(s) updated? - Since our tries will be in a custom server we may wish to employ the a special service alongside our trie servers. We can use an ‘applier’ service which will periodically take the suggestions and phrases and reconstruct the tries with the newest data (the top k search terms) and then re-apply them to the trie servers. This is beneficial since updates will ensure our search results are up-to-date.
What do we do if we have to remove a phrase? - Phrases can be removed when our update happens, but it would be more effective if we had a filtering layer of sorts to not allow certain phrases through, this could be due to profanity, hate speech etc…
Detailed System Overview
The auto suggestion feature has more to it than meets the eye, our system will need to make use of things like load balancers, caches and special api servers.
First let’s discuss the api servers. The api servers will be responsible for taking the users request - which holds our prefix data - and checking our cache. Upon a successful hit, the appropriate suggestion data will then be returned to the user.
After the api servers we will need to add a caching mechanism to our system. The choice of cache technology is entirely up to you but some notable suggestions are Cassandra, Memcache or Redis. The crucial factor here is that our cache needs to be distributed, or in other words have multiple nodes. We need to have our cache distributed because it removes single points of failure and ensures that even if one server goes down we can still have the ability to query suggestions from our cache.
Our caches will be updated from our trie servers if a prefix isn’t found in the cache, this will update the suggestions values in our cache as well.
As an extra measure to decrease latency for users around the world, our auto suggestion feature could utilize a content delivery network (CDN). Essentially this will deliver the suggestion data a lot quicker by hitting based servers based on geographic location. This is a common technique used to reduce latency and can be found in many large systems today, for instance, a popular service like Netflix would use something like this to deliver videos to users quicker who are based around the globe.
These features cover some of the basic elements of our system, let’s run through how this will all work.
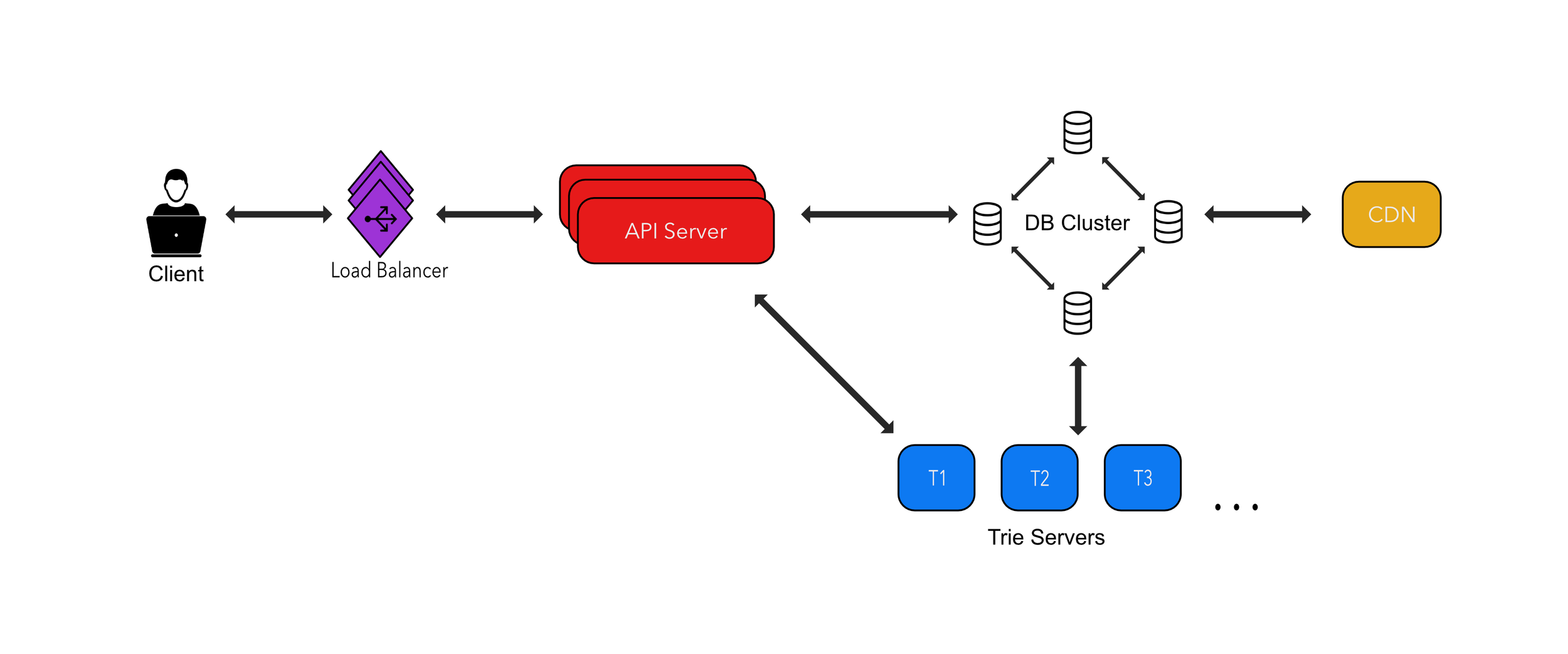
Here is a run down of how the system works:
- The client sends a request with a prefix.
- The prefix is routed to an API server via a load balancer.
- The prefix is checked against a database cluster/distributed cache which returns suggestions to the client when a key exists.
- In the event a key doesn’t exist we look into the appropriate trie server to see which server is responsible for holding the appropriate prefix data from our request.
- At this point the trie server will return some suggestions, which we can use to populate our distributed cache, to ensure faster lookups in the future for this prefix.
- Finally, the response is returned to the client.
Here is a visual detailing how this system might look:
Scale Estimation
Let’s assume our feature will be at similar scale to Google, which gets about 5 billion searches every day, or roughly 60,000 searches a second.
One edge case we need account for is the abundance of duplicate searches. Let’s assume that 20% of the 5 billion searches are unique, of those 20% let’s say we only want to index the top 10% of search queries, this leaves us 100 million unique terms to work with.
For the sake of simplicity, let’s assume that the average search query is 15 characters long and that on average we need 2 bytes to store a character. With these estimates we can calculate that we need 30 bytes on average per search query. Let’s apply this estimate to our daily unique search queries:
100 million * 30 bytes = 3 GB
On a daily basis we will need at least 3 GB. As time goes on our system will remove and update queries as needed, but lets assume a conservative 3% growth rate every day, so for a whole year we can expect to use:
3 GB (0.03 * 3 GB * 365) = 98.55 GB => ~100GB
We can round up to 100 GB to store our search queries for a year.
Data Partitioning
One way we can improve the availability of our suggestion data is to break up our trie servers by character ranges. More specifically, we can break up data based on the amount of memory available on a given server, so we can fill a server with prefixes ranging from, for instance, ‘a’ to ‘aabc’ and then on another server do ‘aadb’ to ‘baa’. The amount of combinations will vary depending on the memory limits of our servers. In order to route our prefix data to the appropriate server we can use a hash table that specifies which servers contain data for a specific character range.
For example, our hash table could look like this:
Trie Server 1: A -> AABC
Trie Server 2: AABD -> BAA
Trie Server 3: BAC -> CAA
Load Balancer
Since we can have upwards of billions of requests a day for search term suggestions we need to have a load balancer situated between the client and any servers handling our search queries. The load balancer will help distribute the load across our servers and will ensure our system can stay up to keep serving search suggestions. Ideally, we need the load balancer to redirect traffic based on the given prefix, this is because our trie servers will be split up by character ranges.
Fault Tolerance
We can make use of a master/slave architecture with our trie servers. Essentially, we can backup our trie data and in the event one, or all, of our servers go down, we can have the master update all the other servers.
Caching
We store the number of valid search terms at the leaf nodes in our tries, we can take that data and store it in a prefix hash table for quick access. It would function by taking a character(s) prefix as a key and the value would be an array of search term suggestions. The trie servers will be responsible for updating our cache if a certain prefix isn’t found when hitting the cache.
Advanced Features
Your interviewer might ask you to elaborate further on some specific cases. Here are a few likely examples related to our auto suggestion that we can expand further upon.
Search personalization - This would entail storing the search history of the user in a table, similar to the prefix table. We will take the data from the personal history table and apply it on top of the results taken from our caches.
Trending search terms - Similar to search personalization, we will also need to maintain a trending searches hash table. The main difference with this case is that we will need a service of some sort that will constantly calculate the top trending searches and then update a table with that data. This table will be queried alongside the personal history table and the caches.
Design What’s App
Design What’s App
We need to design a service that will allow users to chat with each other in real-time on web or mobile. Some notable instant messaging app examples are What’s App, Viber, WeChat, KakaoTalk and Line.
What is What’s App?
Instant messaging allows users to chat in real-time on their phones or computers. Common features include: sending text or media based messages, one-to-one or group chats and push notifications.
System Requirements
Functional Requirement:
- One-to-one chat.
- Track a users status, whether they’re online or offline.
- User must be able to send media, for example, photos, videos or gifs.
- Must handle delivery status of message (ie: sent/delivered/read)
Non-functional Requirement:
- Message order must be maintained at all times.
- The app should perform in real-time and have low latency.
- The system should be able to withstand significant traffic and not fail.
- We can sacrifice some availability to ensure consistency, this is key since all users need to be able to see the same chat history in their apps.
Estimation & Constraints
For our app, let’s make the assumption that there are 250 million daily active users. On average we’ll estimate each user sends 50 messages a day. Doing the math, this gives us 12.5 billion messages per day, that’s quite a bit!
Estimating Message Storage:
Let’s assume that the average message sent is 100 bytes. We will need 1.25 TB of storage on a daily basis.
12.5 billion * 100 bytes = 12.5 TB/day
Now that we know how much storage we need for a day we can extrapolate how much storage we need for one year.
12.5 TB * 365 = 456.25 TB
Let’s round up and say we need roughly 500 TB for one year of storage.
Estimating Bandwidth:
Since our instant messaging service will expect 1.25 TB daily and there are 86400 seconds in a day, we can calculate our bandwidth from this knowledge.
1.25 TB / 86400 seconds = 14.46 MB/s
Again, we can round up to 15 MB/s. The bandwidth will be the same for incoming and outgoing messages since it’s the same process for both users.
Estimates Overview:
- Daily Message Total: 12.5 billion per day
- Daily Storage: 1.25 TB per day
- Annual Storage: 500 TB per year
- Bandwidth (incoming/outgoing): 15 MB/s
High Level Overview
There are many parts to our instant messaging service, in this section we will give a high-level overview of the main requirements our system needs to have.
As per our system requirements there is a bit more than just sending messages, we also need consider the user’s online status, messages containing media and tracking if the message has been successfully delivered or not.
Let’s discuss the individual requirements at a high level.
One-to-one Chat:
- When user A sends a message to user B, user A’s message is routed through a load balancer to a message server.
- When the message is received it is stored in a database, in case it needs to be retrieved later.
- The message server then routes the message to user B.
Sending Media:
- If a message contains a form of media, like a photo or video, then the contents can be uploaded to an HTTP server.
- The HTTP server will then generate a key-value pair with the UserID as the key and the media type as the value (For example: 123: “mp4”). It will then store the response for future reference.
- Traffic hitting the HTTP server can be routed via a content delivery network (CDN) for reduced latency, useful for global reach.
- The message process continues as normal, but when the message reaches its recipient it can query the media file stored in the HTTP server from the hash it received alongside the message.
User Status:
- The message server will maintain an internal database table that can check if user is active or not.
- Whenever a user is online it can send a request to the server to let it know they’ve come online.
- The message servers database can then update the table with the users information, like they’re UserID, to show they’ve come online.
- Whenever someone needs to check if someone is online, the message servers database can be checked to see if the user is online or not.
Message Delivery Status:
- If user A sends a message to user B, as soon as the message hits the server it can respond with an acknowledgement that the message has been sent out successfully.
- After user B receives message, they send an acknowledgment to the server which then sends another acknowledgment back to user A signaling that the message has been successfully delivered.
- If the user’s chat has unread messages, upon opening the chatroom a notification is sent in a similar manner as a delivered message to alert sender their message has been seen.
This is how the instant messaging services architecture might look like:
Message Server In-Depth
Now that we’ve given a high-level overview of all the key features of our service, we need to go in-depth on the message server, which is the core of our service. Features we need to pay attention to include:
- How the message server routes messages to the correct user.
- How a user’s status is tracked.
- Where message data is stored.
Let’s break down each topic.
Message Server:
What is the most efficient way to send and receive messages? The main consideration we need to have when designing how to send/receive messages is how we can maintain the real-time functionality of our service. So if keeping the app working in real-time is key, one approach we can rule out is periodic checks of the message server, since this would increase latency in the form of pointless checks or having to keep track of pending messages in between server checks. There’s too much overhead involved with periodic checks for it to be efficient with our service.
The best option would be to maintain a constant, open connection with the client and server. The benefit is that the client will be notified whenever there is a change on the server-side, any incoming messages, delivery status or user status can be sent to the client so they stay up-to-date. This approach also has lower latency than the previous.
How can our users maintain an open connection with the server? In most instant messaging architectures the user is required to maintain a constant connection to the server, we can use a popular method for maintaining an open connection, it’s known as WebSockets. WebSockets uses a TCP connection that allows bidirectional data flow between a client and server. Another benefit is that it is low latency, which is perfect since our service will have a lot of users. The strength of WebSockets shines when trying to achieve real-time functionality as anytime a change happens to the server it will notify the client via the connection.
Doesn’t the load balancer interfere with the client’s open connection to the server? We can design the load balancer to map the clients user id to the server, which will then maintain an open connection for the client.
How many message servers do we need to handle the current estimated amount of users? Our service will need to make use of a lot of servers to handle our estimated 250 million daily active users. Let’s assume one server can handle 50k active connections, this means we need to maintain at least 5,000 servers.
How does the message server route messages between users? In our approach the message server will kickstart a thread/process for an active user which in turn creates an ephemeral queue to handle incoming messages. When a user has incoming messages, the messages will be sent into the queue and the thread will read from the queue and direct messages to their final destination. In the event a user is sending a message to another user, the thread will query an internal database for the recipients UserID to find the id of their active thread, if the user is active then the message will be sent to the recipients queue to then be delivered to the recipient.
How does the message server maintain order of messages sent between users? All incoming messages to a recipient are put into a queue, which ensures that the first messages in are the first messages out.
How do we handle messages to users who have gone offline? The message server will check its internal database to see if a user’s thread is active, if they aren’t, then the server will send the message to an external database to accumulate all offline messages. The next time the recipient comes online, the server will check the offline messages database and return all the missed messages.
Here is how the message server looks in-depth:
User Status:
How does the message server check for a user’s status? This process is made simpler due to the open connection to the server. The message server will need to maintain an internal database, that keeps track of all active threads which are tied to a user, when they go offline the thread is canceled and the users information is removed from the database. A user’s status is tracked by simply querying the database for a user, if they’re not found then they are offline and vice versa. What we can do is whenever the client starts the app the message server can calculate the status for a user’s entire friend list. This is the simplest way to achieve our goal, but there is still some room for optimizations.
To further optimize the status check we can do a few things:
- If the recipient’s UserID isn’t found in the message server table then we can immediately return an offline status.
- Whenever a user comes online we can institute a small delay to check if the user doesn’t immediately go offline, this avoids multiple checks for the users status in a short time.
- We can query the status of the users that are currently on the users screen, any users not in view will not have their statuses updated.
- If a new chat is started, then we can query the status of the recipient.
Message Storage:
How does the undelivered message and message databases fit into our architecture? Outside of the message server will be two databases, one for messages, which will hold the chat histories for all users, and the other for holding undelivered messages for users who are currently offline. These databases increase the systems consistency as the user can easily query all the message data and stay up-to-date.
What is the most efficient way for a user to retrieve data from the database? Retrieved data will need to be paginated, instead of querying all message data we only are concerned with the data for the chats currently on screen.
What is the best storage system to use for our databases? There are many choices to choose from, but our system has some requirements that need to be met to maintain efficiency. Our databases will be written to very frequently but we also will retrieve large ranges of data in the form of chat histories. RDBMS and NoSQL are not good options here since they would require writing a row for every message received, which would be costly since our system is expected to handle thousands of messages a second.
Some notable choices that will fulfill our needs are solutions like BigTable, Cassandra or HBase, which are wide-column databases. Wide-column databases shine for our specific use case since we will be receiving a lot of data at once, which will be stored in columns. The benefit of the columns is that large ranges of data can be queried relatively quickly so retrieving chat histories is no problem.
Load Balancing
We will need load balancers to sit between the message servers and the users. When accepting incoming messages we can take the UserID from the message object and assign that to a server that will maintain a connection for that particular user and route their request accordingly.
Data Partitioning
We need to establish a partitioning scheme to handle our data as the service grows. It’s estimated we will have 500 TB of data per year, after 5 years we are looking at an estimated storage of 2.5 PB.
One of the simplest ways to partition our data across multiple servers would be to use the UserID, since it is guaranteed to be unique and randomly generated for each user. For our hashing function we can simply do hash(UserID) % 1000 to determine where a user’s data is stored.
Each shard in our system can be 5 TB, so we can start with 100 shards (500/5) for the first year. Our hashing function should evenly distribute our data among the existing servers, over the years as the service grows we can then horizontally scale and add more machines, which we can estimate to be around 500 after 5 years.
If need be, in the early years of our service we can actually store multiple shards on one server, thus utilizing space more efficiently until we need to grow.
Replication & Fault Tolerance
How can we backup user messages? We can have a mechanism that will backup the message database, we can have multiple backups to ensure we never lose a users data. After backing up our data we also need to periodically update all the backups as well, this can be accomplished by using a master/slave technique.
What to do in the event the message server fails? There is an existing safeguard to handle this since we make use of several message servers to handle message requests, so it is unlikely that all will fail. Ideally, if one or multiple servers fail then we can just have the user attempt to reconnect.
Advanced Features
Push Notifications -
In our current implementation we store messages for offline users and only send them once the user comes back online, with push notifications we can now send messages to offline users.
To incorporate push notifications we will need to establish a separate set of servers whose sole responsibility is to send out notifications to users. We can aggregate all the missed messages generated from the message server and then send them to the recipient as a push notification, once the user opens the app we can pull all the messages down from the undelivered messaged database.
Remember that in order for our users to have access to push notifications we need their permission first!
Typing Indicators -
Our instant messaging system currently tracks a messages delivery status (delivered/seen) but to add a more “real-time” feel to the app we need to incorporate typing indicators. A typing indicator just lets the user know that their recipient is currently typing a response to their message(s).
In order to accomplish this feature we will devise a solution similar to the message delivery statuses server acknowledgments, in which whenever a user is typing on their keyboard we can send a typing notification to the other user(s), the notification tells the system to user is typing and will not close out until a “done typing” notification is sent out. The “done typing” notification will need to be throttled, or delayed a bit while the user is typing, in case the user is not finished typing their message and will only be sent out after the delay has transpired.
The status of the users activity will manifest as some sort of icon or animation to let the recipients know what is currently happening.
To make a minor improvement, we will only show typing indicators on chatroom’s that are currently on the users screen, this will reduce unnecessary server calls.
Group Chats -
Group chat as a feature would be implemented in a similar manner to one-to-one chat, when a group chat is created we can give it a unique “GroupChatID” to help identify it and the object will also maintain a list of users in the chatroom.
The way messages would be routed to the group chat would be the same, as in the GroupChatID will be looked up in the message servers database, the GroupChatID will be found and then messages sent to the appropriate group chat queue.
We can save group chats in the database by partitioning them by their GroupChatID.
Design Netflix
Design Netflix
Let’s design Netflix, the goal is to provide on demand entertainment such as popular movies and TV shows to the customer. Other popular streaming services are Youtube Red, Hulu and Prime Video.
Why design a video streaming service?
Streaming services have become quite popular in recent years, with many players rising in the field it has become key to create highly consistent and available systems so thousands of movies and TV shows can be reliably streamed to the customers every minute, without fail.
System Requirements
Functional Requirement:
- Video Streaming company needs to be able to upload media.
- The uploaded media needs to be handled appropriately (Generate thumbnails and encode media into different formats) and stored in a database.
- The uploaded media needs to be stored in databases.
- Users needs to able to create a profile.
- Users need to be able to search for media based on their titles.
Non-functional Requirement:
- The media should be delivered without lag.
- The streaming service needs to reliably store all video files and metadata associated with the media they are uploading. This data needs to be highly available.
- Stored media needs to be highly reliable since we shouldn’t lose any data after uploading.
- Search results need to be carried out in real time.
- The streaming service would be able to handle multiple media uploads at the same time. (Put queue in diagram)
Scale Estimation
For our service, let’s assume there are 100 million daily active users who each watch 5 shows/movies a day, on average. Using this information, we can calculate our videos-per-second:
100 million * 5 / 86400 sec = 6000 videos/sec
We don’t need to worry about uploads every second since our video streaming service will upload infrequently, this is because these companies usually have to negotiate licensing deals with the organizations that own the show or movie they want to add to the platform.
Estimating Video Storage:
Our service will have 200 hours of video uploaded every week. Let’s say that one minute of video is, on average, about 50MB, we can now calculate how much storage we will need for the entire year:
(200 hours * 60 min * 50MB) * 52 weeks = 31.2TB
Estimating Bandwidth:
Since uploads on the company side are infrequent, let’s focus more on the client side and how much media is consumed by them. Let’s assume that our service streams 200 hours of video every minute and assuming it takes 10MB/min to stream a video, we can calculate the amount of bandwidth per second:
200 hours * 10MB/min = 120GB/min => (2GB/sec)
High Level Overview
One important factor to consider about this system is that we need to have components for the client side and the company side. The client will be concerned with creating their accounts and consuming media, while the company side will have to deal with video uploads and storage.
Though the system is separated, it all has to work together.
First, let’s discuss the high level requirements for the client side.
User Profile Database:
When a new user is created the User Profile service will save the new user profile to the User Profile database. The user profile will contain information like first name, last name, email, phone number etc… ( Can be partitioned on user name? )
Search Service:
A user can search for media based on title, a search will check a datastore holding data for all stored media in the company’s database.
Now let’s discuss the high level requirements for the company side.
Upload Service:
The first step for any uploaded media, will take the video data and store put it in a file storage database since the files will be huge.
Processing Queue:
After being saved to file storage the media data is sent through a processing queue. The queue will be able to handle multiple uploads while still maintaining order, so the process is completed sequentially. The queue will be placed after the upload service.
Thumbnail Generator:
After a media file has been uploaded the thumbnail generator can read from the raw video storage and generate various thumbnails for the video.
Encoder:
The encoder operates in a similar manner to the thumbnail generator, it takes the media as input and returns videos of different sizes and quality. This component is important because it allows the media to be enjoyed on devices of differing screen sizes, like mobile or web.
Video Metadata:
After generating thumbnails and encoding the media files, all the data is then joined together to form the metadata for the upload. This metadata is then saved in a new database that can provide easy access to the video file, thumbnails, description, reviews etc…
This is how the video streaming service architecture might look like:
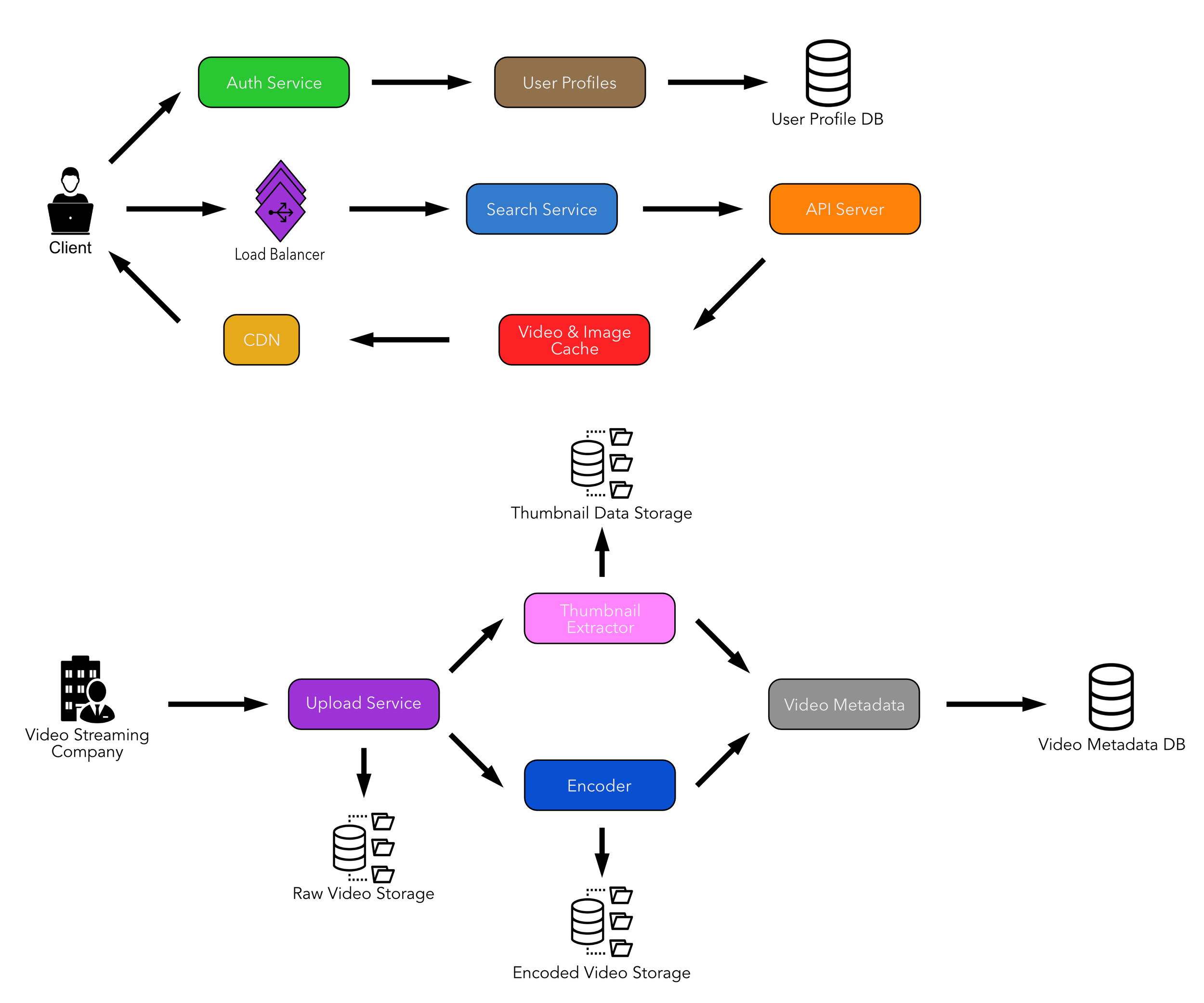
Component Breakdown
Our service will have two sides, the client and company side. The client side will be very read heavy since users will search the media library frequently for their favorite shows and the system, overall, will consume hours of media every minute. Our goal for the client side will be to create a system that allows us to retrieve media fairly quickly.
The company side is mainly concerned with being able to upload media effectively, this entails storing large media files, encoding media to different formats, generating thumbnails and video metadata. Selecting the appropriate storage systems are key since not all database technologies are created equal and can have an impact on the client side if not chosen carefully.
Client Side Components
How will the user profiles be stored?: When a user creates a new profile it is saved to a MySQL database for ease of access.
How will the the search service work?: The search function will be a micro service that has all of its own infrastructure, we’ve actually already covered this topic in the auto suggestion section. Essentially, a list of suggestions will be returned for the user and whatever choice they select will be checked against the video database, if found will return the appropriate information or media. - just takes the users input and checks it against the database …
How will the video database handle large amounts of reads to it?: Instead of allowing reads and writes to happen on one database, we can apply the master/slave approach. All writes will go to the master database, updating the metadata, any time a client needs to request data from the database it can read from one of the slaves. This method adds a layer of safety as it segregate the reads and writes made to our database, thus reducing server load by distributing operations to different servers, this is key since our service will involve significantly more reads than writes. The downside is that the client might read some stale data, this is because the master receives the changes first then they are applied to its slaves, but this is a minor setback as the slave will be promptly updated by the master after a certain amount of time.
How many load balancers should we place before the search service?: We can calculate this by taking the daily average users (100 million) and the amount of load one server can take (1 server can handle 50000 requests), we can conclude that our service will need at least 2000 servers to handle all the load from our daily users.
Company Side Components
How will the video files be stored?: Since video files are often large they can’t just be saved to a database, they need a specialized form of storage to handle large files. We can turn to distributed file systems like HDFS and GoogleFS for this requirement. We can use the same approach when dealing with encoded videos
How can we store thumbnails?: Thumbnails are a special case, since they will receive a lot of read requests. Even though thumbnails are generally small files, the amount of requests can be significant when scrolling through, let’s say the home page, where several titles will appear each with a thumbnail. When taking this into consideration some choices might be to use a database like Google’s BigTable. BigTable is a wide-column store database that excels at retrieving multiple pieces of data from various locations, this also will reduce latency in our system.
To take this a bit further, we can also implement an in-memory cache in our system that takes in the most requested (popular) video thumbnails and stores them. The in-memory cache provides even further boosts to performance, with the added benefit of taking a lot of thumbnail data, since thumbnail files are usually small.
How exactly does the video metadata contain large files like video and thumbnails?: The video metadata is made up of data from the thumbnail generator and the encoder, essentially it holds a reference to the data in their respective databases, as well as it’s own data (title, description, reviews etc…).
What if the media upload fails?: In the event there is a disruption, like an internet connection failure, we can have a mechanism in place that will save and resume to the point where the upload lost connection.
Data Partitioning
Since our service will have millions of daily viewers a day, we will receive large amounts of read requests to our video databases. When dealing with large amounts of requests on a server, the logical solution is to split the server up via sharding. A method we can use to shard our database is to use a hash function that takes the VideoID, which will then take the result and map the video metadata to a server.
To improve performance a bit more, we can maintain a cache in front of our video database that will hold the most popular videos, this will speed up the request when users inevitably elect to watch a popular video on our service.
Load Balancer
After successfully, and efficiently partitioning our video data, we must design a way for our caches to handle large amounts of requests. Whenever a request is made to check if a video is in our cache it needs to pass through a load balancer, which will effectively route all the incoming requests evenly amongst the servers.
For our load balancers we can use a simple technique known as round robin. But round robin is too simplistic to be the only solution for a high traffic, video streaming service, we can add a few conditions to the round robin to ensure even server distribution.
One condition could be that our load balancers will need to filter out unresponsive servers and “close” them for a short amount of time. After the time limit has passed then the server can come online again, but if it receives to much traffic and is unable to make any further connections then the server is penalized with a longer wait period, the wait period grows after each consecutive failure. This condition helps as the system is no longer concerned with taking a request to a server with too much traffic and will instead send the request to the pool of available servers.
Another condition we could add to our load balancer servers is using weighted response times. Our system could track the response times of our servers and assign it a weight based on performance, slow response times would equal less weight and vice versa. This information can then be used to route requests to servers which have higher weights assigned to them, so we know which servers will be the most capable of handling requests at all times.
Fault Tolerance
In the event one of our servers dies, we can fallback onto consistent hashing to help remove the server from the pool and keep the distribution fairly even amongst our servers.
Content Delivery Network (CDN)
Since our service will be available worldwide, it’s important that we utilize a CDN to ensure low latency when users stream videos, no matter their location. To maximize performance, we can devise a mechanism that keeps a cache of the most popular videos for a particular region (since taste in video varies worldwide), the benefit is the most requested videos will be delivered even faster due to being geographically closer to the user but also kept in an in-memory cache which has increased performance than a regular database. Videos that aren’t as popular can just be requested from a regular server that’s not in a CDN.
It All Starts With Your Resume - Resume Review
Links + example resumes:

http://resume.programminginterview.com/
“I Don’t Have Enough Experience!”
Source:
Where To Find Jobs - Resources
These are some quick links to various job boards with specific niches to help get your job hunt started. You can use these as a starting point but remember that combining this with reaching out to recruiters will help your job search exponentially.
Entry Level Jobs:
Startup Jobs:
Remote Jobs:
https://www.workingnomads.co/jobs
Companies That Offer Remote Jobs:
Javascript Jobs:
Mobile Developer -
https://www.swiftlangjobs.com/
The Software Developer Interview Process
The interview process usually looks like this for most software engineers:
- You will be contacted by someone from the company you applied to set up interview
- Usually you’ll have to do 1-2 phone interviews, usually the interviews just ask about your background or even have you do some coding via a code share. These interviews can be thought of as bouncers at a club, they’re preliminary checks to make sure you’re good enough for an onsite interview… so make sure you’re competent in your favorite programming language and rite clean code as most candidates get weeded out here
- Or sometimes you’ll be tasked to do a take home test, though in my experience this is more common in junior level positions.
- After the phone interviews, there is the onsite. Onsite interviews differ from company to company, some only have you do one 1 hour interview, others will have you meet with several people
- In these interviews you will be asked behavioral and technical questions, for sure, as well as at least one whiteboard question. In higher level jobs, object oriented programming and system design questions will be asked. If you’re interviewing for any Big 4 or FAANG company then you’re almost guaranteed to be asked system design so make sure to account for that in your studying.
Common Technical Interview Mistakes
Key Takeaways:
- Not practicing enough, have a study regimen and stick to it, make sure to diversify your study, focus on the areas you struggle most with but remember that technical interviews are more than the whiteboard
- Ignoring interviewer hints, most interviewers want to see you succeed and will sometimes drop hints to nudge you in the right direction. Take these and use them, never ignore them the interviewer already knows the answer to the problem so ignoring them is foolish
- Silence - Never stay quiet you want to think out loud but don’t be overbearing, there is nothing wrong with saying you need a minute to think and organize your thoughts
- Show enthusiasm for the job, nobody wants to hire someone who seems disinterested. Always have insightful questions ready to ask
Interview Mindset
Key points
- More opportunities out there - It’s best to always go into an interview thinking that his isn’t your only opportunity, if you don’t get the job, ok thats fine, there are many more opportunities out there. You can think of interviewing like dating, if one person doesn’t workout theres other fish in the sea.
- Treat as a learning experience - Another thing to consider is that you should view interviewing as a learning experience. After every failed interview, reflect on where you struggled the most and work to improve yourself. Don’t be afraid to ask for feedback from the interviewer.
- Interviewing is a numbers game , thats the harsh reality - It is rare for people to get a job with the first interview, it’s a process and more likely than not, you will have to do through several. Interviewing is a numbers game, for me personally, I’ve done close to a 100 interviews and I’ve only received 3 jobs as of this moment. For me thats roughly a 3% success rate, I know it sounds demoralizing but thats the game and if I’d given up I wouldn’t be where I’m at today.
- People match your energy level - One way to make interviews more pleasant is to simply have a good attitude, if you go in nervous then your interviewer will be business as usual, but if you walk in excited for the opportunity to interview with a big smile on your face, they can sense that, not only does that convey enthusiasm for the job but it might make the interviewer loosen up as well. Another benefit to this is interviewers also consider how you’re like to work with when deciding if they want to hire you or not, so if you have a good attitude and are pleasant to be around then that will leave a good image of you in the interviewers mind, which may turn in your favor, who knows?
‘Hero Stories’ - Crafting A Perfect Response
When walking into interview you should have at least 4 ‘hero’ stories prepared, these stories should cover each of the 4 topics I’m going to discuss in this video:
- Technical - technical challenges and how you think, on past/personal projects that you can talk about technical stuff - In one of my personal projects, I wanted to build a morse code app, had to look deep into the phones hardware API’s and figure out how to manipulate the flash according to text input.
- Success - Tell stories how you succeeded, like the story behind a promotion, or how you scaled an app, how your idea helped the team, any story that shows something you were successful in. - talk about story where i improved test coverage in app by 20% single-handedly
- Leadership - How you’re able to take charge and lead by example - Took initiative to teach another team abut react native and get them on-boarded so they can start developing new components in the app in RN.
- Challenge - How, even if given ambiguous directions, you can still overcome obstacles. ‘Describe a problem where you didn’t have all the info?’ - challenging technical problems - When working at a startup my boss gave me the freedom to design a newsfeed for the app, I had to do my own research and come up with my own solution to the problem, i had no idea how to implement this and was able to devise a solution regardless
Tips For Communicating Effectively
In software engineering interviews, the one thing you must always do is let the interviewer know what you’re thinking. Thinking out loud is crucial because it demonstrates to the interviewer what your thought process is like. At every step your interviewer needs to be in the loop so make sure you emphasize things like why you’re selecting a particular data structure over another, or what kind of edge cases this problem could face.
- Make sure you understand the problem given to you, never be afraid to ask clarifying questions — maybe
- Make it easy for interviewer to follow along with you
- You should have a linear thought process , avoid jumping around the problem. Following previous video is a good strategy.
- If possible, use pictures to illustrate your thought process as this can bring your idea together fully for the interviewer to understand since pictures are more easily digestible.
- Discuss tradeoffs and alternate approaches , interviewer how you consider alternate ideas you should avoid settling on the first solution that comes to mind
Questions To Ask At The End Of The Interview
At the end of every interview you will be asked if you have any questions, this is your chance to find out more about the company, your role, the team, culture, anything really. Although, as a general rule of thumb, avoid asking questions HR could answer for you, such as, salary, benefits etc. Asking good questions helps you to really understand the role and see if it’s a good fit for you, as well as being a chance to leave a good impression to your interviewer.
Job Related Questions:
- What would a typical day look like?
- How will my performance be measured?
- What will be expected of me after 30 days, 90 days, 1 year?
- How big is the team?
- What tech stack does the company use?
- Does the company practice test driven development?
Culture Related Questions:
- What is the culture like at this company?
- How much say do developers have regarding the product(s)?
- What qualities make someone excel at this company?
- What learning opportunities are there for developers?
- Do the teams go out and do things outside the office?
- What do you enjoy most about working here?
Organization Related Questions:
- What are the biggest challenges facing the team right now?
- What career paths are there in this company?
- What is your software development process like?
- What is the process like for on boarding new employees?
- How much guidance can I expect from my supervisor and how much ownership can I expect for my projects?
Quality Of Life Related Questions:
- Is working from home an option?
- Will I be expected to work overtime?
- Do you think this company offers good work-life balance?
Day Before Guide
- Relax - get good nights sleep, don’t practice difficult problems, at this point you just need to focus on maximizing your performance and contrary to popular belief studying harder can make you more stressed.
- If you do study, go over stuff you are already good at , its important to not only reinforce your learning but to give yourself a win, this boosts your self-esteem as you’ll feel like you’ve actually learned something through all your studying and primes your brain for the whiteboard.
- Walkthrough your problem solving process - this brings reassurance that if faced with unfamiliar or difficult questions that you can always trust your problem solving ability to see you through. Apply this process to some practice problems, and see how well it works for you
- Plan out your morning routine - Your goal is to be as relaxed as possible going in and you should have your morning rituals planned out so you can avoid any decision fatigue
How To Determine Your Salary
Link resources:
How To Get A Raise + Slide Deck & Email Template
Key Takeaways:
Show them why you’re valuable -
- Show doc highlighting your accomplishes and metrics your boss is looking for.
- Showcase tasks you can accomplish with in the next 12-18 months, the goal here is to show initiative and how you can expand beyond you current role.
- Show how you can achieve said goals, summarize key steps.
Present your salary w/ data-
- Present multiple salary options, remember it’s not just base salary, you can negotiate benefits or things like bonuses, equity, stock. It’s all dependent on your company.
- Whenever you present salary data you need to have the data to back it up, if you followed previous videos on calculating salary then this shouldn’t be an issue and you can play with the number to your liking.
If you’re asking for a large raise, then a pitch deck is the way to go, as its more professional. But if your ask isn’t that high then you can opt for an email, plus a meeting with manager.
Video Resources:
Below is the email template:
Asking for raise email template.pdf (30.8 КБ)