Discover, one by one, the most important built-in JavaScript objects you are going to use in your day to day coding. From Math to Date to Number and beyond!
Introduction
In this module you can find a reference to all the global objects that JavaScript gives you, and every bit of functionality they expose.
Some bits are repeated in other parts of the course, but here is where you can always go back and find that precise method you are looking for, categorize in alphabetical order.
In particular we’ll see
- Object
- Number
- Date
- JSON
- Intl
- String
- Math
and the global functions.
Object
This lesson documents all the Object built-in object properties and methods.
An object value can be generated using the object literal syntax:
const person = {}
typeof person //object
using the Object global function:
const person = Object()
typeof person //object
or using the Object constructor:
const person = new Object()
typeof person //object
You can initialize the object with properties using this syntax:
const person = {
age: 36,
name: 'Flavio',
speak: () => {
//speak
}
}
const person = Object({
age: 36,
name: 'Flavio',
speak: () => {
//speak
}
})
const person = new Object({
age: 36,
name: 'Flavio',
speak: () => {
//speak
}
})
All those ways are basically equivalent as they all give you access to the methods I’ll list below.
We divide methods in static methods, and instance methods. Static methods are called directly on Object . Instance methods are called on an object instance ( an object).
Properties
The Object object has 2 properties
-
lengthalways equal to1 -
prototypethis points to the Object prototype object: the object that all other objects inherit from. Check the prototypal inheritance lesson.
Static methods
Static methods are a great way to offer a namespace for functions that work in the same space. In this way we don’t have global functions around, but all are namespaced under the Object global object.
-
Object.assign()*ES2015 Object.create()Object.defineProperties()Object.defineProperty()-
Object.entries()*ES2017 Object.freeze()Object.getOwnPropertyDescriptor()Object.getOwnPropertyDescriptors()Object.getOwnPropertyNames()Object.getOwnPropertySymbols()Object.getPrototypeOf()-
Object.is()*ES2015 Object.isExtensible()Object.isFrozen()Object.isSealed()Object.keys()Object.preventExtensions()Object.seal()-
Object.setPrototypeOf()*ES2015 Object.values()
Instance methods
hasOwnProperty()isPrototypeOf()propertyIsEnumerable()toLocaleString()toString()valueOf()
The rest of this lesson describes each method in detail.
Before doing so, I want to spend one minute to introduce the property descriptor object .
Property descriptor object
Any object in JavaScript has a set of properties, and each of these properties has a descriptor .
Some of the methods listed above will make use of the property descriptor object. This is an object that defines a property behavior and own properties.
Those methods include:
Object.create()Object.defineProperties()Object.defineProperty()Object.getOwnPropertyDescriptor()Object.getOwnPropertyDescriptors()
Here is an example of a property descriptor object:
{
value: 'Something'
}
This is the simplest one. value is the property value, in a key-value definition. This key is defined as the object key, when you define this property in an object:
{
breed: {
value: 'Siberian Husky'
}
}
Example:
const animal = {}
const dog = Object.create(animal, {
breed: {
value: 'Siberian Husky'
}
});
console.log(dog.breed) //'Siberian Husky'
You can pass additional properties to define each different object property:
- value : the value of the property
- writable : true the property can be changed
- configurable : if false, the property cannot be removed nor any attribute can be changed, except its value
- enumerable : true if the property is enumerable
- get : a getter function for the property, called when the property is read
- set : a setter function for the property, called when the property is set to a value
writable , configurable and enumerable set the behavior of that property. They have a boolean value, and by default those are all false .
Example:
const animal = {}
const dog = Object.create(animal, {
breed: {
value: 'Siberian Husky',
writable: false
}
});
console.log(dog.breed) //'Siberian Husky'
dog.breed = 'Pug' //TypeError: Cannot assign to read only property 'breed' of object '#<Object>'
Object.assign()
Introduced in ES2015 , this method copies all the enumerable own properties of one or more objects into another.
Its primary use case is to create a shallow copy of an object.
const copied = Object.assign({}, original)
Being a shallow copy, values are cloned, and objects references are copied (not the objects themselves), so if you edit an object property in the original object, that’s modified also in the copied object, since the referenced inner object is the same:
const original = {
name: 'Fiesta',
car: {
color: 'blue'
}
}
const copied = Object.assign({}, original)
original.name = 'Focus'
original.car.color = 'yellow'
copied.name //Fiesta
copied.car.color //yellow
I mentioned “one or more”:
const wisePerson = {
isWise: true
}
const foolishPerson = {
isFoolish: true
}
const wiseAndFoolishPerson = Object.assign({}, wisePerson, foolishPerson)
console.log(wiseAndFoolishPerson) //{ isWise: true, isFoolish: true }
Object.create()
Introduced in ES5.
Creates a new object, with the specified prototype.
Usage:
const newObject = Object.create(prototype)
Example:
const animal = {}
const dog = Object.create(animal)
The newly create object will inherit all the prototyope object properties.
You can specify a second parameter to add new properties to the object, that the prototype lacked:
const newObject = Object.create(prototype, newProperties)
where newProperties is an object of objects that define each property.
Example:
const animal = {}
const dog = Object.create(animal, {
breed: {
value: 'Siberian Husky'
}
});
console.log(dog.breed) //'Siberian Husky'
I didn’t just say breed: 'Siberian Husky' but I had to pass a property descriptor object, defined at the beginning of this page.
Object.create() is often used in combination with Object.assign() :
const dog = Object.assign(Object.create(animal), {
bark() {
console.log('bark')
}
})
Object.defineProperties()
Creates or configures multiple object properties at once. Returns the object.
Takes 2 arguments. The first is an object upon which we’re going to create or configure the properties. The second is an object of properties.
Example:
const dog = {}
Object.defineProperties(dog, {
breed: {
value: 'Siberian Husky'
}
})
console.log(dog.breed) //'Siberian Husky'
I didn’t just say breed: 'Siberian Husky' but I had to pass a property descriptor object, defined at the beginning of this page.
It can be used in conjunction with Object.getOwnPropertyDescriptors to copy properties over from another object:
const wolf = { /*... */ }
const dog = {}
Object.defineProperties(dog, Object.getOwnPropertyDescriptors(wolf))
Object.defineProperty()
Creates or configures one object property. Returns the object.
Takes 3 arguments. The first is an object upon which we’re going to create or configure the properties. The second is the property name defined as a string. The third is an object with the property definition.
Example:
const dog = {}
Object.defineProperty(dog, 'breed', {
value: 'Siberian Husky'
})
console.log(dog.breed) //'Siberian Husky'
I didn’t just say breed: 'Siberian Husky' but I had to pass a property descriptor object, defined at the beginning of this page.
Object.entries()
Introduced in ES2017 .
This method returns an array containing all the object own properties, as an array of [key, value] pairs.
Usage:
const person = { name: 'Fred', age: 87 }
Object.entries(person) // [['name', 'Fred'], ['age', 87]]
Object.entries() also works with arrays:
const people = ['Fred', 'Tony']
Object.entries(people) // [['0', 'Fred'], ['1', 'Tony']]
You can use it to count the number of properties an object contains, combined with the length property of the array.
Object.freeze()
Takes an object as argument, and returns the same object. The object passed as argument is mutated and it’s now an immutable object. No properties can be added, no properties can be removed, properties can’t be changed.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
const myDog = Object.freeze(dog)
Object.isFrozen(dog) //true
Object.isFrozen(myDog) //true
dog === myDog //true
dog.name = 'Roger' //TypeError: Cannot add property name, object is not extensible
In the example, both dog and myDog are frozen. The argument passed as argument to Object.freeze() is mutated, and can’t be un-freezed. It’s also returned as argument, hence dog === myDog (it’s the same exact object).
Calling Object.freeze() is the equivalent of calling Object.preventExtensions() to prevent an object to have more properties defined, plus setting all properties as non-configurable and non-writeable.
Object.getOwnPropertyDescriptor()
I talked about property descriptors up above at the beginning of this lesson. This method can be used to retrieve the descriptor of a specific property.
Usage:
const propertyDescriptor = Object.getOwnPropertyDescriptor(object, propertyName)
Example:
const dog = {}
Object.defineProperties(dog, {
breed: {
value: 'Siberian Husky'
}
})
Object.getOwnPropertyDescriptor(dog, 'breed')
/*
{
value: 'Siberian Husky',
writable: false,
enumerable: false,
configurable: false
}
*/
Object.getOwnPropertyDescriptors()
This method returns all own (non-inherited) properties descriptors of an object.
Object.getOwnPropertyDescriptors(obj) accepts an object, and returns a new object that provides a list of the descriptors.
Example:
const dog = {}
Object.defineProperties(dog, {
breed: {
value: 'Siberian Husky'
}
})
Object.getOwnPropertyDescriptors(dog)
/*
{
breed: {
value: 'Siberian Husky',
writable: false,
enumerable: false,
configurable: false
}
}
*/
There is one use case that makes this property very useful. ES2015 gave us Object.assign() , which copies all enumerable own properties from one or more objects, and return a new object. However there is a problem with that, because it does not correctly copies properties with non-default attributes.
If an object has just a setter, it’s not correctly copied to a new object, using Object.assign() . For example, with this object:
const person1 = {
set name(newName) {
console.log(newName)
}
}
This copy attempt won’t work:
const person2 = {}
Object.assign(person2, person1)
But this will work and copy over the setter correctly:
const person3 = {}
Object.defineProperties(person3,
Object.getOwnPropertyDescriptors(person1))
As you can see with a console test:
person1.name = 'x'
"x"
person2.name = 'x'
person3.name = 'x'
"x"
person2 misses the setter, it was not copied over.
The same limitation goes for shallow cloning objects with Object.create() .
Object.getOwnPropertyNames()
Object.getOwnPropertyNames() returns an array containing all the names of the own properties of the object passed as argument, including non-enumerable properties. It does not consider inherited properties.
Non enumerable properties are not iterated upon. Not listed in for…of loops, for example.
To get only a list of the enumerable properties you can use Object.keys() instead.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
dog.name = 'Roger'
Object.getOwnPropertyNames(dog) //[ 'breed', 'name' ]
Object.getOwnPropertySymbols()
Get an array of symbols defined on an object.
Symbols is an ES2015 feature, and this method was introduced in ES2015 as well.
Example:
const dog = {}
const r = Symbol('Roger')
const s = Symbol('Syd')
dog[r] = {
name: 'Roger',
age: 6
}
dog[s] = {
name: 'Syd',
age: 5
}
Object.getOwnPropertySymbols(dog) //[ Symbol(Roger), Symbol(Syd) ]
Object.getPrototypeOf()
Returns the prototype of an object.
Usage:
Object.getPrototypeOf(obj)
Example:
const animal = {}
const dog = Object.create(animal)
const prot = Object.getPrototypeOf(dog)
animal === prot //true
If the object has no prototype, we’ll get null . This is the case of the Object object:
Object.prototype //{}
Object.getPrototypeOf(Object.prototype) //null
Object.is()
This method was introduced in ES2015. It aims to help comparing values.
Usage:
Object.is(a, b)
The result is always false unless:
-
aandbare the same exact object -
aandbare equal strings (strings are equal when composed by the same characters) -
aandbare equal numbers (numbers are equal when their value is equal) -
aandbare bothundefined, bothnull, bothNaN, bothtrueor bothfalse
0 and -0 are different values in JavaScript, so pay attention in this special case (convert all to +0 using the + unary operator before comparing, for example).
Object.isExtensible()
This method checks if we can add new properties to an object.
Any object is extensible, unless it’s been used as an argument to
Object.freeze()Object.seal()Object.preventExtensions()
Usage:
const dog = {}
Object.isExtensible(dog) //true
const cat = {}
Object.freeze(cat)
Object.isExtensible(cat) //false
Object.isFrozen()
Accepts an object as argument, and returns true if the object is frozen, false otherwise. Objects are frozen when they are return values of the Object.freeze() function.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
const myDog = Object.freeze(dog)
Object.isFrozen(dog) //true
Object.isFrozen(myDog) //true
dog === myDog //true
In the example, both dog and myDog are frozen. The argument passed as argument to Object.freeze() is mutated, and can’t be un-freezed. It’s also returned as argument, hence dog === myDog (it’s the same exact object).
Object.isSealed()
Accepts an object as argument, and returns true if the object is sealed, false otherwise. Objects are sealed when they are return values of the Object.seal() function.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
const myDog = Object.seal(dog)
Object.isSealed(dog) //true
Object.isSealed(myDog) //true
dog === myDog //true
In the example, both dog and myDog are sealed. The argument passed as argument to Object.seal() is mutated, and can’t be un-sealed. It’s also returned as argument, hence dog === myDog (it’s the same exact object).
Object.keys()
Object.keys() accepts an object as argument and returns an array of all its (own) enumerable properties.
const car = {
color: 'Blue',
brand: 'Ford',
model: 'Fiesta'
}
Object.keys(car) //[ 'color', 'brand', 'model' ]
I said enumerable properties. This means their internal enumerable flag is set to true, which is the default. Check MDN for more info on this subject.
One use of the Object.keys function is to create a copy of an object that has all the properties of it, except one:
const car = {
color: 'blue',
brand: 'Ford'
}
const prop = 'color'
const newCar = Object.keys(car).reduce((object, key) => {
if (key !== prop) {
object[key] = car[key]
}
return object
}, {})
Object.preventExtensions()
Takes an object as argument, and returns the same object. The object passed as argument is mutated and it’s now an object that will not accept new properties. New properties can’t be added, but existing properties can be removed, and existing properties can be changed.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
Object.preventExtensions(dog)
dog.name = 'Roger' //TypeError: Cannot add property name, object is not extensible
The argument passed as argument is also returned as argument, hence dog === myDog (it’s the same exact object).
We can’t add new properties, but we can remove existing properties:
const dog = {}
dog.breed = 'Siberian Husky'
dog.name = 'Roger'
Object.preventExtensions(dog)
delete dog.name
dog //{ breed: 'Siberian Husky' }
Object.seal()
Takes an object as argument, and returns the same object. The object passed as argument is mutated and it’s now an object that will not accept new properties. New properties can’t be added, and existing properties can’t be removed, but existing properties can be changed.
Example:
const dog = {}
dog.breed = 'Siberian Husky'
Object.seal(dog)
dog.breed = 'Pug'
dog.name = 'Roger' //TypeError: Cannot add property name, object is not extensible
The argument passed as argument is also returned as argument, hence dog === myDog (it’s the same exact object).
Similar to Object.freeze() but does not make properties non-writable. In only prevents to add or remove properties.
Similar to Object.preventExtensions() but also disallows removing properties:
const dog = {}
dog.breed = 'Siberian Husky'
dog.name = 'Roger'
Object.seal(dog)
delete dog.name //TypeError: Cannot delete property 'name' of #<Object>
Object.setPrototypeOf() * ES2015
Set the prototype of an object. Accepts two arguments: the object and the prototype.
Usage:
Object.setPrototypeOf(object, prototype)
Example:
const Animal = {}
Animal.isAnimal = true
const Mammal = Object.create(Animal)
Mammal.isMammal = true
console.log('-------')
Mammal.isAnimal //true
const dog = Object.create(Animal)
dog.isAnimal //true
console.log(dog.isMammal) //undefined
Object.setPrototypeOf(dog, Mammal)
console.log(dog.isAnimal) //true
console.log(dog.isMammal) //true
Object.values()
This method returns an array containing all the object own property values.
Usage:
const person = { name: 'Fred', age: 87 }
Object.values(person) // ['Fred', 87]
Object.values() also works with arrays:
const people = ['Fred', 'Tony']
Object.values(people) // ['Fred', 'Tony']
Let’s now define the instance methods that any object has. We call these on the object itself, not on the Object global object.
hasOwnProperty()
Called on an object instance, accepts a string as argument. If the object has a property with the name contained in the string argument, it returns true . Otherwise it returns false .
Example:
const person = { name: 'Fred', age: 87 }
person.hasOwnProperty('name') //true
person.hasOwnProperty('job') //false
isPrototypeOf()
Called on an object instance, accepts an object as argument. If the object you called isPrototypeOf() on appears in the prototype chain of the object passed as argument, it returns true . Otherwise it returns false .
Example:
const Animal = {
isAnimal: true
}
const Mammal = Object.create(Animal)
Mammal.isMammal = true
Animal.isPrototypeOf(Mammal) //true
const dog = Object.create(Animal)
Object.setPrototypeOf(dog, Mammal)
Animal.isPrototypeOf(dog) //true
Mammal.isPrototypeOf(dog) //true
propertyIsEnumerable()
Called on an object instance, accepts a string as argument. If the object has a property with the name contained in the string argument, and that property is enumerable, it returns true . Otherwise it returns false .
Example:
const person = { name: 'Fred' }
Object.defineProperty(person, 'age', {
value: 87,
enumerable: false
})
person.propertyIsEnumerable('name') //true
person.propertyIsEnumerable('age') //false
toLocaleString()
Called on an object instance, returns a string representation of the object. Accepts an optional locale as argument.
Returns the [object Object] string unless overridden. Objects can then return a different string representation depending on the locale.
const person = { name: 'Fred' }
person.toLocaleString() //[object Object]
toString()
Called on an object instance, returns a string representation of the object. Returns the [object Object] string unless overridden. Objects can then return a string representation of themselves.
const person = { name: 'Fred' }
person.toString() //[object Object]
valueOf()
Called on an object instance, returns the primitive value of it.
const person = { name: 'Fred' }
person.valueOf() //{ name: 'Fred' }
This is normally only used internally by JavaScript, and rarely actually invoked in user code.
Number
This lesson documents all the Number built-in object properties and methods.
A number value can be generated using a number literal syntax:
const age = 36
typeof age //number
or using the Number global function:
const age = Number(36)
typeof age //number
If we add the new keyword, we get a Number object in return:
const age = new Number(36)
typeof age //object
which has a very different behavior than a number type. You can get the original number value using the valueOf() method:
const age = new Number(36)
typeof age //object
age.valueOf() //36
Properties
-
EPSILONthe smallest interval between two numbers -
MAX_SAFE_INTEGERthe maximum integer value JavaScript can represent -
MAX_VALUEthe maximum positive value JavaScript can represent -
MIN_SAFE_INTEGERthe minimum integer value JavaScript can represent -
MIN_VALUEthe minimum positive value JavaScript can represent -
NaNa special value representing “not a number” -
NEGATIVE_INFINITYa special value representing negative infinity -
POSITIVE_INFINITYa special value representing positive infinity
Those properties evaluated to the values listed below:
Number.EPSILON
Number.MAX_SAFE_INTEGER
Number.MAX_VALUE
Number.MIN_SAFE_INTEGER
Number.MIN_VALUE
Number.NaN
Number.NEGATIVE_INFINITY
Number.POSITIVE_INFINITY
2.220446049250313e-16
9007199254740991
1.7976931348623157e+308
-9007199254740991
5e-324
NaN
-Infinity
Infinity
Object Methods
We can call those methods passing a value:
-
Number.isNaN(value): returns true ifvalueis not a number -
Number.isFinite(value): returns true ifvalueis a finite number -
Number.isInteger(value): returns true ifvalueis an integer -
Number.isSafeInteger(value): returns true ifvalueis a safe integer -
Number.parseFloat(value): convertsvalueto a floating point number and returns it -
Number.parseInt(value): convertsvalueto an integer and returns it
I mentioned “safe integer”. Also up above, with the MAX_SAFE_INTEGER and MIN_SAFE_INTEGER properties. What is a safe integer? It’s an integer that can be exactly represented as an IEEE-754 double precision number (all integers from (2^53 - 1) to -(2^53 - 1)). Out of this range, integers cannot be represented by JavaScript correctly. Out of the scope of the course, but here is a great explanation of that.
Examples of the above methods in use:
Number.isNaN
NaN is a special case. A number is NaN only if it’s NaN or if it’s a division of 0 by 0 expression, which returns NaN . In all the other cases, we can pass it what we want but it will return false :
Number.isNaN(NaN) //true
Number.isNaN(0 / 0) //true
Number.isNaN(1) //false
Number.isNaN('Flavio') //false
Number.isNaN(true) //false
Number.isNaN({}) //false
Number.isNaN([1, 2, 3]) //false
Number.isFinite
Returns true if the passed value is a finite number. Anything else, booleans, strings, objects, arrays, returns false:
Number.isFinite(1) //true
Number.isFinite(-237) //true
Number.isFinite(0) //true
Number.isFinite(0.2) //true
Number.isFinite('Flavio') //false
Number.isFinite(true) //false
Number.isFinite({}) //false
Number.isFinite([1, 2, 3]) //false
Number.isInteger
Returns true if the passed value is an integer. Anything else, booleans, strings, objects, arrays, returns false:
Number.isInteger(1) //true
Number.isInteger(-237) //true
Number.isInteger(0) //true
Number.isInteger(0.2) //false
Number.isInteger('Flavio') //false
Number.isInteger(true) //false
Number.isInteger({}) //false
Number.isInteger([1, 2, 3]) //false
Number.isSafeInteger
A number might satisfy Number.isInteger() but not Number.isSafeInteger() if it goes out of the boundaries of safe integers, which I explained above.
So, anything over 2^53 and below -2^53 is not safe:
Number.isSafeInteger(Math.pow(2, 53)) // false
Number.isSafeInteger(Math.pow(2, 53) - 1) // true
Number.isSafeInteger(Math.pow(2, 53) + 1) // false
Number.isSafeInteger(-Math.pow(2, 53)) // false
Number.isSafeInteger(-Math.pow(2, 53) - 1) // false
Number.isSafeInteger(-Math.pow(2, 53) + 1) // true
Number.parseFloat
Parses the argument as a float number and returns it. The argument is a string:
Number.parseFloat('10') //10
Number.parseFloat('10.00') //10
Number.parseFloat('237,21') //237
Number.parseFloat('237.21') //237.21
Number.parseFloat('12 34 56') //12
Number.parseFloat(' 36 ') //36
Number.parseFloat('36 is my age') //36
Number.parseFloat('-10') //-10
Number.parseFloat('-10.2') //-10.2
As you can see Number.parseFloat() is pretty flexible. It can also convert strings with words, extracting the first number, but the string must start with a number:
Number.parseFloat('I am Flavio and I am 36') //NaN
It only handles radix 10 numbers.
Number.parseInt
Parses the argument as an integer number and returns it:
Number.parseInt('10') //10
Number.parseInt('10.00') //10
Number.parseInt('237,21') //237
Number.parseInt('237.21') //237
Number.parseInt('12 34 56') //12
Number.parseInt(' 36 ') //36
Number.parseInt('36 is my age') //36
As you can see Number.parseInt() is pretty flexible. It can also convert strings with words, extracting the first number, but the string must start with a number:
Number.parseInt('I am Flavio and I am 36') //NaN
You can add a second parameter to specify the radix. Radix 10 is default but you can use octal or hexadecimal number conversions too:
Number.parseInt('10', 10) //10
Number.parseInt('010') //10
Number.parseInt('010', 8) //8
Number.parseInt('10', 8) //8
Number.parseInt('10', 16) //16
Instance methods
When you use the new keyword to instantiate a value with the Number() function, we get a Number object in return:
const age = new Number(36)
typeof age //object
This object offers a few unique methods you can use. Mostly to convert the number to specific formats.
-
.toExponential(): return a string representing the number in exponential notation -
.toFixed(): return a string representing the number in fixed-point notation -
.toLocaleString(): return a string with the local specific conventions of the number -
.toPrecision(): return a string representing the number to a specified precision -
.toString(): return a string representing the specified object in the specified radix (base). Overrides the Object.prototype.toString() method -
.valueOf(): return the number primitive value of the object
.toExponential()
You can use this method to get a string representing the number in exponential notation:
new Number(10).toExponential() //1e+1 (= 1 * 10^1)
new Number(21.2).toExponential() //2.12e+1 (= 2.12 * 10^1)
You can pass an argument to specify the fractional part digits:
new Number(21.2).toExponential(1) //2.1e+1
new Number(21.2).toExponential(5) //2.12000e+1
Notice how we lost precision in the first example.
.toFixed()
You can use this method to get a string representing the number in fixed point notation:
new Number(21.2).toFixed() //21
You can add an optional number setting the digits as a parameter:
new Number(21.2).toFixed(0) //21
new Number(21.2).toFixed(1) //21.2
new Number(21.2).toFixed(2) //21.20
.toLocaleString()
Formats a number according to a locale.
By default the locale is US english:
new Number(21.2).toLocaleString() //21.2
We can pass the locale as the first parameter:
new Number(21.2).toLocaleString('it') //21,2
This is eastern arabic
new Number(21.2).toLocaleString('ar-EG') //٢١٫٢
There are a number of options you can add, and I suggest to look at the MDN page to know more.
.toPrecision()
This method returns a string representing the number to a specified precision:
new Number(21.2).toPrecision(0) //error! argument must be > 0
new Number(21.2).toPrecision(1) //2e+1 (= 2 * 10^1 = 2)
new Number(21.2).toPrecision(2) //21
new Number(21.2).toPrecision(3) //21.2
new Number(21.2).toPrecision(4) //21.20
new Number(21.2).toPrecision(5) //21.200
.toString()
This method returns a string representation of the Number object. It accepts an optional argument to set the radix:
new Number(10).toString() //10
new Number(10).toString(2) //1010
new Number(10).toString(8) //12
new Number(10).toString(16) //a
.valueOf()
This method returns the number value of a Number object:
const age = new Number(36)
typeof age //object
age.valueOf() //36
Date
JavaScript offers us a date handling functionality through a powerful built-in object: Date .
We’ll dive into what it offers, but when you need to work with dates in the real world, I encourage you to use Moment.js or another higher level library that makes things easy for you.
The Date object
A Date object instance represents a single point in time.
Despite being named Date , it also handles time .
Initialize the Date object
We initialize a Date object by using
new Date()
This creates a Date object pointing to the current moment in time.
Internally, dates are expressed in milliseconds since Jan 1st 1970 (UTC). This date is important because as far as computers are concerned, that’s where it all began.
You might be familiar with the UNIX timestamp: that represents the number of seconds that passed since that famous date.
Important: the UNIX timestamp reasons in seconds. JavaScript dates reason in milliseconds.
If we have a UNIX timestamp, we can instantiate a JavaScript Date object by using
const timestamp = 1530826365
new Date(timestamp * 1000)
If we pass 0 we’d get a Date object that represents the time at Jan 1st 1970 (UTC):
new Date(0)
If we pass a string rather than a number, then the Date object uses the parse method to determine which date you are passing. Examples:
new Date('2018-07-22')
new Date('2018-07') //July 1st 2018, 00:00:00
new Date('2018') //Jan 1st 2018, 00:00:00
new Date('07/22/2018')
new Date('2018/07/22')
new Date('2018/7/22')
new Date('July 22, 2018')
new Date('July 22, 2018 07:22:13')
new Date('2018-07-22 07:22:13')
new Date('2018-07-22T07:22:13')
new Date('25 March 2018')
new Date('25 Mar 2018')
new Date('25 March, 2018')
new Date('March 25, 2018')
new Date('March 25 2018')
new Date('March 2018') //Mar 1st 2018, 00:00:00
new Date('2018 March') //Mar 1st 2018, 00:00:00
new Date('2018 MARCH') //Mar 1st 2018, 00:00:00
new Date('2018 march') //Mar 1st 2018, 00:00:00
There’s lots of flexibility here. You can add, or omit, the leading zero in months or days.
Be careful with the month/day position, or you might end up with the month being misinterpreted as the day.
You can also use Date.parse :
Date.parse('2018-07-22')
Date.parse('2018-07') //July 1st 2018, 00:00:00
Date.parse('2018') //Jan 1st 2018, 00:00:00
Date.parse('07/22/2018')
Date.parse('2018/07/22')
Date.parse('2018/7/22')
Date.parse('July 22, 2018')
Date.parse('July 22, 2018 07:22:13')
Date.parse('2018-07-22 07:22:13')
Date.parse('2018-07-22T07:22:13')
Date.parse will return a timestamp (in milliseconds) rather than a Date object.
You can also pass a set of ordered values that represent each part of a date: the year, the month (starting from 0), the day, the hour, the minutes, seconds and milliseconds:
new Date(2018, 6, 22, 7, 22, 13, 0)
new Date(2018, 6, 22)
The minimum should be 3 parameters, but most JavaScript engines also interpret less than these:
new Date(2018, 6) //Sun Jul 01 2018 00:00:00 GMT+0200 (Central European Summer Time)
new Date(2018) //Thu Jan 01 1970 01:00:02 GMT+0100 (Central European Standard Time)
In any of these cases, the resulting date is relative to the timezone of your computer. This means that two different computers might output a different value for the same date object .
JavaScript, without any information about the timezone, will consider the date as UTC, and will automatically perform a conversion to the current computer timezone.
So, summarizing, you can create a new Date object in 4 ways
- passing no parameters , creates a Date object that represents “now”
- passing a number , which represents the milliseconds from 1 Jan 1970 00:00 GMT
- passing a string , which represents a date
- passing a set of parameters , which represent the different parts of a date
Timezones
When initializing a date you can pass a timezone, so the date is not assumed UTC and then converted to your local timezone.
You can specify a timezone by adding it in +HOURS format, or by adding the timezone name wrapped in parentheses:
new Date('July 22, 2018 07:22:13 +0700')
new Date('July 22, 2018 07:22:13 (CET)')
If you specify a wrong timezone name in the parentheses, JavaScript will default to UTC without complaining.
If you specify a wrong numeric format, JavaScript will complain with an “Invalid Date” error.
Date static methods
You can invoke 3 methods on the Date object:
Date.now()
Returns the current timestamp in millieseconds.
Usage:
Date.now()
See the section below titled “Get the current timestamp” for more details on getting the timestamp.
Date.parse()
Parses a string representation of a date and return the timestamp.
Usage:
Date.parse('2018-07-22') //1532217600000
Date.parse('July 22, 2018') //1532210400000
Date.parse('July 22, 2018 07:22:13') //1532236933000
Date.parse('2018-07-22 07:22:13') //1532236933000
Date.parse('2018-07-22T07:22:13') //1532236933000
Date.UTC()
Remember the Date constructor from above? We cna pass it 3 or more parameters to indicate the year, the month (starting from 0), the day, the hour, the minutes, seconds and milliseconds:
new Date(2018, 6, 22, 7, 22, 13, 0)
new Date(2018, 6, 22)
Date.UTC() works in the same way, but returns a timestamp rather than a Date object:
Date.UTC(2018, 6, 22, 7, 22, 13, 0) //1532244133000
Date.UTC(2018, 6, 22) //1532217600000
Date conversions and formatting
Given a Date object, there are lots of methods that will generate a string from that date:
const date = new Date('July 22, 2018 07:22:13')
date.toString() // "Sun Jul 22 2018 07:22:13 GMT+0200 (Central European Summer Time)"
date.toTimeString() //"07:22:13 GMT+0200 (Central European Summer Time)"
date.toUTCString() //"Sun, 22 Jul 2018 05:22:13 GMT"
date.toDateString() //"Sun Jul 22 2018"
date.toISOString() //"2018-07-22T05:22:13.000Z" (ISO 8601 format)
date.toLocaleString() //"22/07/2018, 07:22:13"
date.toLocaleTimeString() //"07:22:13"
date.getTime() //1532236933000
date.getTime() //1532236933000
The Date object getter methods
A Date object offers several methods to check its value. These all depends on the current timezone of the computer:
const date = new Date('July 22, 2018 07:22:13')
date.getDate() //22
date.getDay() //0 (0 means sunday, 1 means monday..)
date.getFullYear() //2018
date.getMonth() //6 (starts from 0)
date.getHours() //7
date.getMinutes() //22
date.getSeconds() //13
date.getMilliseconds() //0 (not specified)
date.getTime() //1532236933000
date.getTimezoneOffset() //-120 (will vary depending on where you are and when you check - this is CET during the summer). Returns the timezone difference expressed in minutes
There are equivalent UTC versions of these methods, that return the UTC value rather than the values adapted to your current timezone:
date.getUTCDate() //22
date.getUTCDay() //0 (0 means sunday, 1 means monday..)
date.getUTCFullYear() //2018
date.getUTCMonth() //6 (starts from 0)
date.getUTCHours() //5 (not 7 like above)
date.getUTCMinutes() //22
date.getUTCSeconds() //13
date.getUTCMilliseconds() //0 (not specified)
Editing a date
A Date object offers several methods to edit a date value:
const date = new Date('July 22, 2018 07:22:13')
date.setDate(newValue)
date.setDay(newValue)
date.setFullYear(newValue) //note: avoid setYear(), it's deprecated
date.setMonth(newValue)
date.setHours(newValue)
date.setMinutes(newValue)
date.setSeconds(newValue)
date.setMilliseconds(newValue)
date.setTime(newValue)
date.setTimezoneOffset(newValue)
setDayandsetMonthstart numbering from 0, so for example, March is month 2.
Fun fact: those methods “overlap”, so if you, for example, set date.setHours(48) , it will increment the day as well.
Good to know: you can add more than one parameter to setHours() to also set minutes, seconds and milliseconds: setHours(0, 0, 0, 0) - the same applies to setMinutes and setSeconds .
As for get , also set methods have an UTC equivalent:
const date = new Date('July 22, 2018 07:22:13')
date.setUTCDate(newValue)
date.setUTCDay(newValue)
date.setUTCFullYear(newValue)
date.setUTCMonth(newValue)
date.setUTCHours(newValue)
date.setUTCMinutes(newValue)
date.setUTCSeconds(newValue)
date.setUTCMilliseconds(newValue)
Get the current timestamp
The UNIX timestamp is an integer that represents the number of seconds elapsed since January 1 1970 .
On UNIX-like machines, which include Linux and macOS, you can type date +%s in the terminal and get the UNIX timestamp back:
$ date +%s
1524379940
The current timestamp can be fetched by calling the now() method on the Date object:
Date.now()
You could get the same value by calling
new Date().getTime()
or
new Date().valueOf()
Note: IE8 and below do not have the
now()method onDate. Look for a polyfill if you need to support IE8 and below, or usenew Date().getTime()ifDate.nowis undefined (as that’s what a polyfill would do)
The timestamp in JavaScript is expressed in milliseconds .
To get the timestamp expressed in seconds, convert it using:
Math.floor(Date.now() / 1000)
Note: some tutorials use
Math.round(), but that will approximate the the next second even if the second is not fully completed.
or, less readable:
~~(Date.now() / 1000)
I’ve seen tutorials using
+new Date
which might seem a weird statement, but it’s perfectly correct JavaScript code. The unary operator + automatically calls the valueOf() method on any object it is assigned to, which returns the timestamp (in milliseconds). The problem with this code is that you instantiate a new Date object that’s immediately discarded.
Pay attention. If you overflow a month with the days count, there will be no error, and the date will go to the next month:
new Date(2018, 6, 40) //Thu Aug 09 2018 00:00:00 GMT+0200 (Central European Summer Time)
The same goes for months, hours, minutes, seconds and milliseconds.
Format dates according to the locale
The Internationalization API, well supported in modern browsers (notable exception: UC Browser), allows you to translate dates.
It’s exposed by the Intl object, which also helps localizing numbers, strings and currencies.
We’re interested in Intl.DateTimeFormat() .
Here’s how to use it.
Format a date according to the computer default locale:
// "12/22/2017"
const date = new Date('July 22, 2018 07:22:13')
new Intl.DateTimeFormat().format(date) //"22/07/2018" in my locale
Format a date according to a different locale:
new Intl.DateTimeFormat('en-US').format(date) //"7/22/2018"
Intl.DateTimeFormat method takes an optional parameter that lets you customize the output. To also display hours, minutes and seconds:
const options = {
year: 'numeric',
month: 'numeric',
day: 'numeric',
hour: 'numeric',
minute: 'numeric',
second: 'numeric'
}
new Intl.DateTimeFormat('en-US', options).format(date) //"7/22/2018, 7:22:13 AM"
new Intl.DateTimeFormat('it-IT', options2).format(date) //"22/7/2018, 07:22:13"
Here’s a reference of all the properties you can use.
Compare two dates
You can calculate the difference between two dates using Date.getTime() :
const date1 = new Date('July 10, 2018 07:22:13')
const date2 = new Date('July 22, 2018 07:22:13')
const diff = date2.getTime() - date1.getTime() //difference in milliseconds
In the same way you can check if two dates are equal:
const date1 = new Date('July 10, 2018 07:22:13')
const date2 = new Date('July 10, 2018 07:22:13')
if (date2.getTime() === date1.getTime()) {
//dates are equal
}
Keep in mind that getTime() returns the number of milliseconds, so you need to factor in time in the comparison. July 10, 2018 07:22:13 is not equal to new July 10, 2018 . In this case you can use setHours(0, 0, 0, 0) to reset the time.
How to determine if a date is today in JavaScript
How can you determine if a JavaScript Date object instance is a representation of a date/time that is “today”?
Given a Date instance, we can use the getDate() , getMonth() and getFullYear() methods, which return the day, month and year of a date, and compare them to today, which can be retrieved using new Date() .
Here’s a small function that does exactly that, returning true if the argument is today.
const isToday = (someDate) => {
const today = new Date()
return someDate.getDate() == today.getDate() &&
someDate.getMonth() == today.getMonth() &&
someDate.getFullYear() == today.getFullYear()
}
You can use it like this:
const today = isToday(myDate)
JSON
JSON is a file format that’s used to store and interchange data.
Data is stored in a set of key-value pairs.
This data is human readable, which makes JSON perfect for manual editing.
Here’s an example of a JSON string:
{
"name": "Flavio",
"age": 35
}
From this little snippet you can see that keys are wrapped in double quotes, a colon separates the key and the value, and the value can be of different types.
Key-value sets are separated by a comma.
Spacing (spaces, tabs, new lines) does not matter in a JSON file. The above is equivalent to
{"name": "Flavio","age": 35}
or
{"name":
"Flavio","age":
35}
but as always well-formatted data is better to understand.
JSON was born in 2002 and got hugely popular thanks to its ease of use, and flexibility, and although being born out of the JavaScript world, it quickly spread out to other programming languages.
It’s defined in the ECMA-404 standard.
JSON strings are commonly stored in .json files and transmitted over the network with an application/json MIME type.
Data types
JSON supports some basic data types:
-
Number: any number that’s not wrapped in quotes -
String: any set of characters wrapped in quotes -
Boolean:trueorfalse -
Array: a list of values, wrapped in square brackets -
Object: a set of key-value pairs, wrapped in curly brackets -
null: thenullword, which represents an empty value
Any other data type must be serialized to a string (and then de-serialized) in order to be stored in JSON.
Encoding and decoding JSON in JavaScript
ECMAScript 5 in 2009 introduced the JSON object in the JavaScript standard, which among other things offers the JSON.parse() and JSON.stringify() methods.
Before it can be used in a JavaScript program, a JSON in string format must be parsed and transformed in data that JavaScript can use.
JSON.parse() takes a JSON string as its parameter, and returns an object that contains the parsed JSON:
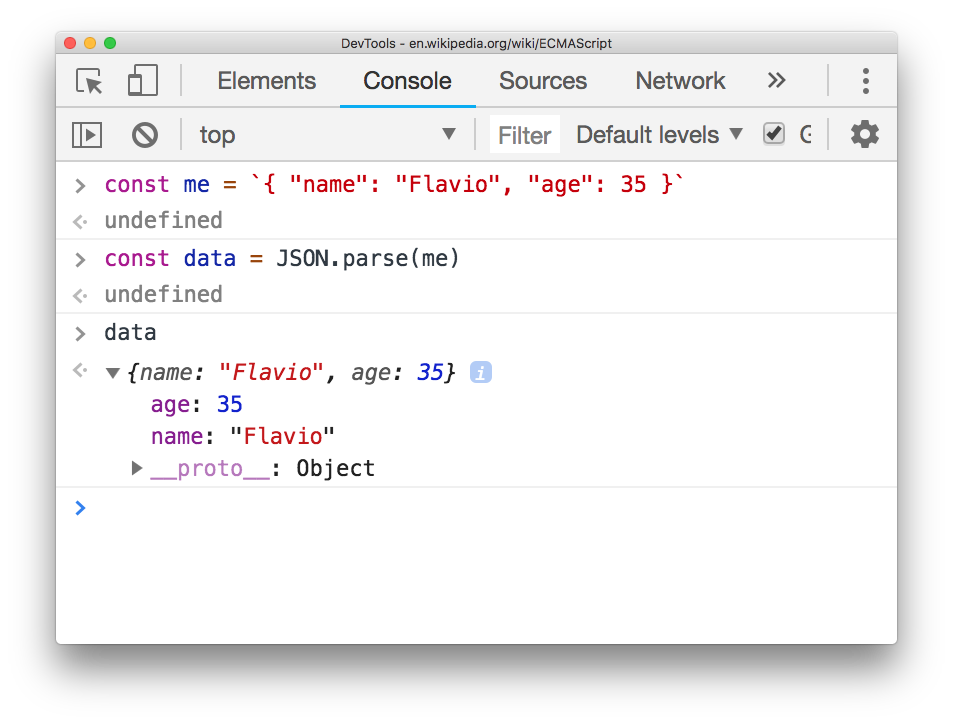
JSON.stringify() takes a JavaScript object as its parameter, and returns a string that represents it in JSON:
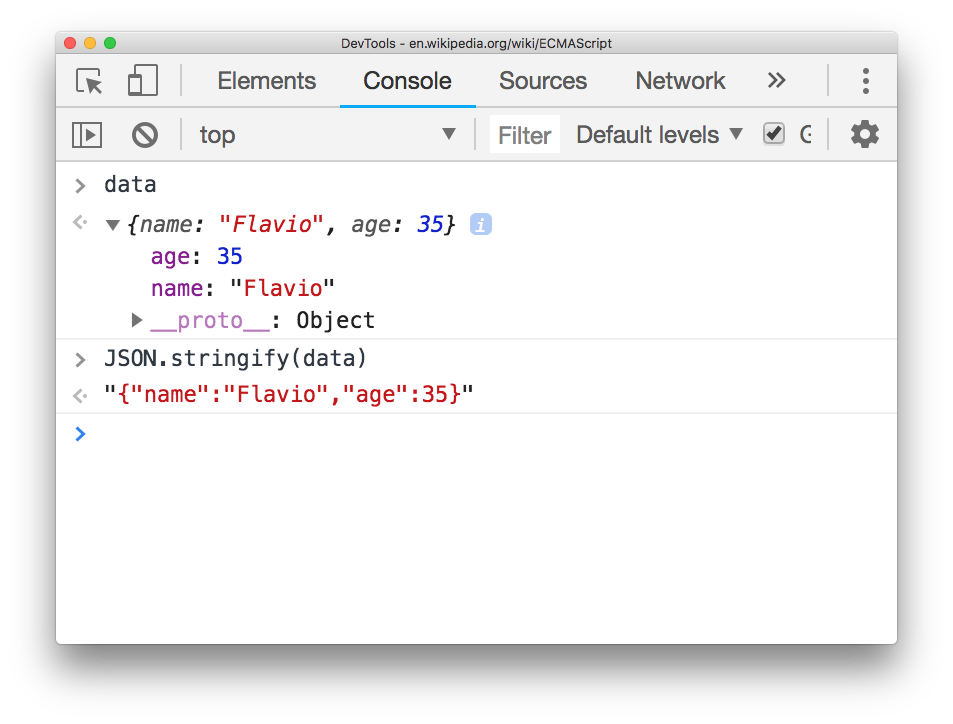
JSON.parse() can also accepts an optional second argument, called the reviver function. You can use that to hook into the parsing and perform any custom operation:
JSON.parse(string, (key, value) => {
if (key === 'name') {
return `Name: ${value}`
} else {
return value
}
})
Nesting objects
You can organize data in a JSON file using a nested object:
{
"name": {
"firstName": "Flavio",
"lastName": "Copes"
},
"age": 35,
"dogs": [
{ "name": "Roger" },
{ "name": "Syd" }
],
"country": {
"details": {
"name": "Italy"
}
}
}
Online tools for working with JSON
There are many useful tools you can use.
One of them is JSONLint, the JSON Validator. Using it you can verify if a JSON string is valid.
JSONFormatter is a nice tool to format a JSON string so it’s more readable according to your conventions.
Intl
Intl is a powerful object that exposes the JavaScript Internationalization API
It exposes the following properties:
-
Intl.Collator: gives you access to language-sensitive string comparison -
Intl.DateTimeFormat: gives you access to language-sensitive date and time formatting -
Intl.NumberFormat: gives you access to language-sensitive number formatting -
Intl.PluralRules: gives you access to language-sensitive plural formatting and plural language rules -
Intl.RelativeTimeFormat: gives you access to language-sensitive relative time formatting
It also provides one method: Intl.getCanonicalLocales() .
Intl.getCanonicalLocales() lets you check if a locale is valid, and returns the correct formatting for it. It can accept a string, or an array:
Intl.getCanonicalLocales('it-it') //[ 'it-IT' ]
Intl.getCanonicalLocales(['en-us', 'en-gb']) //[ 'en-US', 'en-GB' ]
and throws an error if the locale is invalid
Intl.getCanonicalLocales('it_it') //RangeError: Invalid language tag: it_it
which you can catch with a try/catch block.
Different types can interface with the Intl API for their specific needs. In particular we can mention:
String.prototype.localeCompare()Number.prototype.toLocaleString()Date.prototype.toLocaleString()Date.prototype.toLocaleDateString()Date.prototype.toLocaleTimeString()
Let’s go and see how to work with the above Intl properties:
Intl.Collator
This property gives you access to language-sensitive string comparison
You initialize a Collator object using new Intl.Collator() , passing it a locale, and you use its compare() method which returns a positive value if the first argument comes after the second one. A negative if it’s the reverse, and zero if it’s the same value:
const collator = new Intl.Collator('it-IT')
collator.compare('a', 'c') //a negative value
collator.compare('c', 'b') //a positive value
We can use it to order arrays of characters, for example.
Intl.DateTimeFormat
This property gives you access to language-sensitive date and time formatting.
You initialize a DateTimeFormat object using new Intl.DateTimeFormat() , passing it a locale, and then you pass it a date to format it as that locale prefers:
const date = new Date()
let dateTimeFormatter = new Intl.DateTimeFormat('it-IT')
dateTimeFormatter.format(date) //27/1/2019
dateTimeFormatter = new Intl.DateTimeFormat('en-GB')
dateTimeFormatter.format(date) //27/01/2019
dateTimeFormatter = new Intl.DateTimeFormat('en-US')
dateTimeFormatter.format(date) //1/27/2019
The formatToParts() method returns an array with all the date parts:
const date = new Date()
const dateTimeFormatter = new Intl.DateTimeFormat('en-US')
dateTimeFormatter.formatToParts(date)
/*
[ { type: 'month', value: '1' },
{ type: 'literal', value: '/' },
{ type: 'day', value: '27' },
{ type: 'literal', value: '/' },
{ type: 'year', value: '2019' } ]
*/
You can print the time as well. Check all the options you can use on MDN.
Intl.NumberFormat
This property gives you access to language-sensitive number formatting. You can use it to format a number as a currency value.
Say you have a number like 10 , and it represents the price of something.
You want to transform it to $10,00 .
If the number has more than 3 digits however it should be displayed differently, for example, 1000 should be displayed as $1.000,00
This is in USD, however.
Different countries have different conventions to display values .
JavaScript makes it very easy for us with the ECMAScript Internationalization API , a relatively recent browser API that provides a lot of internationalization features, like dates and time formatting.
It is very well supported:
const formatter = new Intl.NumberFormat('en-US', {
style: 'currency',
currency: 'USD',
minimumFractionDigits: 2
})
formatter.format(1000) // "$1,000.00"
formatter.format(10) // "$10.00"
formatter.format(123233000) // "$123,233,000.00"
The minimumFractionDigits property sets the fraction part to be always at least 2 digits. You can check which other parameters you can use in the NumberFormat MDN page.
This example creates a number formatter for the Euro currency, for the Italian country:
const formatter = new Intl.NumberFormat('it-IT', {
style: 'currency',
currency: 'EUR'
})
Intl.PluralRules
This property gives you access to language-sensitive plural formatting and plural language rules. I found the example on the Google Developers portal by Mathias Bynens the only one I could relate to practical usage: giving a suffix to ordered numbers: 0th, 1st, 2nd, 3rd, 4th, 5th…
const pr = new Intl.PluralRules('en-US', {
type: 'ordinal'
})
pr.select(0) //other
pr.select(1) //one
pr.select(2) //two
pr.select(3) //few
pr.select(4) //other
pr.select(10) //other
pr.select(22) //two
Every time we got other , we translate that to th . If we have one , we use st . For two we use nd . few gets rd .
We can use an object to create an associative array:
const suffixes = {
'one': 'st',
'two': 'nd',
'few': 'rd',
'other': 'th'
}
and we do a formatting function to reference the value in the object, and we return a string containing the original number, and its suffix:
const format = (number) => `${number}${suffixes[pr.select(number)]}`
Now we can use it like this:
format(0) //0th
format(1) //1st
format(2) //2nd
format(3) //3rd
format(4) //4th
format(21) //21st
format(22) //22nd
Note that there are nice things coming soon to Intl, like Intl.RelativeTimeFormat and Intl.ListFormat , which are at the time of writing only available in browser previews (on Chrome Canary, for example) but will be soon. The Web is evolving at a fast pace.


String
We talked about strings in the string type lesson.
In that lesson I mentioned all the methods we can call on a string type, but I left all the detailed explanation for later. Now is the time to look at them.
The String object has one static method, String.fromCharCode() , which is used to create a string representation from a sequence of Unicode characters. Here we build a simple string using the ASCII codes
String.fromCodePoint(70, 108, 97, 118, 105, 111) //'Flavio'
You can also use octal or hexadecimal numbers:
String.fromCodePoint(0x46, 0154, parseInt(141, 8), 118, 105, 111) //'Flavio'
All the other methods described here are instance methods : methods that are run on a string type:
charAt(i)charCodeAt(i)codePointAt(i)concat(str)endsWith(str)includes(str)indexOf(str)lastIndexOf(str)localeCompare()match(regex)normalize()padEnd()padStart()repeat()replace(str1, str2)search(str)slice(begin, end)split(separator)startsWith(str)substring()toLocaleLowerCase()toLocaleUpperCase()toLowerCase()toString()toUpperCase()trim()trimEnd()trimStart()valueOf()
All methods are case sensitive and do not mutate the original string.
charAt(i)
Return the character at the index i
Examples:
'Flavio'.charAt(0) //'F'
'Flavio'.charAt(1) //'l'
'Flavio'.charAt(2) //'a'
If you give an index that does not match the string, you get an empty string.
JavaScript does not have a “char” type, so a char is a string of length 1.
charCodeAt(i)
Return the character code at the index i . Similar to charAt() , except it returns the Unicode 16-bit integer representing the character:
'Flavio'.charCodeAt(0) //70
'Flavio'.charCodeAt(1) //108
'Flavio'.charCodeAt(2) //97
Calling toString() after that will return the hexadecimal number, which you can lookup in Unicode tables like this.
codePointAt(i)
This was introduced in ES2015 to handle Unicode characters that cannot be represented by a single 16-bit Unicode unit, but need 2 instead.
Using charCodeAt() you need to retrieve the first, and the second, and combine them. Using codePointAt() you get the whole character in one call.
For example, this chinese character “𠮷” is composed by 2 UTF-16 (Unicode) parts:
"𠮷".charCodeAt(0).toString(16) //d842
"𠮷".charCodeAt(1).toString(16) //dfb7
If you create a new character by combining those unicode characters:
"\ud842\udfb7" //"𠮷"
You can get the same result usign codePointAt() :
"𠮷".codePointAt(0) //20bb7
If you create a new character by combining those unicode characters:
"\u{20bb7}" //"𠮷"
concat(str)
Concatenates the current string with the string str
Example:
'Flavio'.concat(' ').concat('Copes') //'Flavio Copes'
endsWith(str)
Check if a string ends with the value of the string str .
'JavaScript'.endsWith('Script') //true
'JavaScript'.endsWith('script') //false
includes(str)
Check if a string includes the value of the string str .
'JavaScript'.includes('Script') //true
'JavaScript'.includes('script') //false
'JavaScript'.includes('JavaScript') //true
'JavaScript'.includes('aSc') //true
'JavaScript'.includes('C++') //false
includes() also accepts an optional second parameter, an integer which indicates the position where to start searching for:
'a nice string'.includes('nice') //true
'a nice string'.includes('nice', 3) //false
'a nice string'.includes('nice', 2) //true
indexOf(str)
Gives the position of the first occurrence of the string str in the current string. Returns -1 if the string is not found.
'JavaScript'.indexOf('Script') //4
'JavaScript'.indexOf('JavaScript') //0
'JavaScript'.indexOf('aSc') //3
'JavaScript'.indexOf('C++') //-1
You can pass a second parameters to set the starting point:
'a nice string'.indexOf('nice') !== -1 //true
'a nice string'.indexOf('nice', 3) !== -1 //false
'a nice string'.indexOf('nice', 2) !== -1 //true
lastIndexOf(str)
Gives the position of the last occurrence of the string str in the current string
'JavaScript is a great language. Yes I mean JavaScript'.lastIndexOf('Script') //47
'JavaScript'.lastIndexOf('C++') //-1
localeCompare()
This method compares a string to another, returning a number (negative, 0, positive) that tells if the current string is lower, equal or greater than the string passed as argument, according to the locale.
The locale is determined by the current locale, or you can pass it as a second argument:
'a'.localeCompare('à') //-1
'a'.localeCompare('à', 'it-IT') //-1
The most common use case is for ordering arrays:
['a', 'b', 'c', 'd'].sort((a, b) => a.localeCompare(b))
where one would typically use
['a', 'b', 'c', 'd'].sort((a, b) => (a > b) ? 1 : -1)
with the difference that localeCompare() allows us to make this compatible with alphabets used all over the globe.
An object passed as third argument can be used to pass additional options. Look for all the possible values of those options on MDN.
match(regex)
Given a regular expression identified by regex , try to match it in the string.
normalize()
Unicode has four main normalization forms . Their codes are NFC , NFD , NFKC , NFKD . Wikipedia has a good explanation of the topic.
The normalize() method returns the string normalized according to the form you specify, which you pass as parameter ( NFC being the default if the parameter is not set).
I will reuse the MDN example because I’m sure there is a valid usage but I can’t find another example:
'\u1E9B\u0323'.normalize() //ẛ̣
'\u1E9B\u0323'.normalize('NFD') //ẛ̣
'\u1E9B\u0323'.normalize('NFKD') //ṩ
'\u1E9B\u0323'.normalize('NFKC') //ṩ
padEnd()
The purpose of string padding is to add characters to a string , so it reaches a specific length .
padEnd() , introduced in ES2017, adds such characters at the end of the string.
padEnd(targetLength [, padString])
Sample usage:
| padEnd() | |
|---|---|
| ‘test’.padEnd(4) | ‘test’ |
| ‘test’.padEnd(5) | ‘test ‘ |
| ‘test’.padEnd(8) | ‘test ‘ |
| ‘test’.padEnd(8, ‘abcd’) | ‘testabcd’ |
padStart()
Like padEnd() , we have padStart() to add characters at the beginning of a string.
padStart(targetLength [, padString])
Sample usage:
| padStart() | |
|---|---|
| ‘test’.padStart(4) | ‘test’ |
| ‘test’.padStart(5) | ‘ test’ |
| ‘test’.padStart(8) | ‘ test’ |
| ‘test’.padStart(8, ‘abcd’) | ‘abcdtest’ |
repeat()
Introduced in ES2015, repeats the strings for the specificed number of times:
'Ho'.repeat(3) //'HoHoHo'
Returns an empty string if there is no parameter, or the parameter is 0 . If the parameter is negative you’ll get a RangeError.
replace(str1, str2)
Find the first occurrence of str1 in the current string and replaces it with str2 (only the first!). Returns a new string.
'JavaScript'.replace('Java', 'Type') //'TypeScript'
You can pass a regular expression as the first argument:
'JavaScript'.replace(/Java/, 'Type') //'TypeScript'
replace() will only replace the first occurrence, unless you use a regex as the search string, and you specify the global ( /g ) option:
'JavaScript JavaX'.replace(/Java/g, 'Type') //'TypeScript TypeX'
The second parameter can be a function. This function will be invoked for every match found, with a number of arguments:
- the the string that matches the pattern
- an integer that specifies the position within the string where the match occurred
- the string
The return value of the function will replace the matched part of the string.
Example:
'JavaScript'.replace(/Java/, (match, index, originalString) => {
console.log(match, index, originalString)
return 'Test'
}) //TestScript
This also works for regular strings, not just regexes:
'JavaScript'.replace('Java', (match, index, originalString) => {
console.log(match, index, originalString)
return 'Test'
}) //TestScript
In case your regex has capturing groups , those values will be passed as arguments right after the match parameter:
'2015-01-02'.replace(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/, (match, year, month, day, index, originalString) => {
console.log(match, year, month, day, index, originalString)
return 'Test'
}) //Test
search(str)
Return the position of the first occurrence of the string str in the current string.
It returns the index of the start of the occurrence, or -1 if no occurrence is found.
'JavaScript'.search('Script') //4
'JavaScript'.search('TypeScript') //-1
You can search using a regular expression (and in reality, even if you pass a string, that’s internally and transparently used as a regular expression too).
'JavaScript'.search(/Script/) //4
'JavaScript'.search(/script/i) //4
'JavaScript'.search(/a+v/) //1
slice(begin, end)
Return a new string from the part of the string included between the begin and end positions.
The original string is not mutated.
end is optional.
'This is my car'.slice(5) //is my car
'This is my car'.slice(5, 10) //is my
If you set a negative first parameter, the start index starts from the end, and the second parameter must be negative as well, always counting from the end:
'This is my car'.slice(-6) //my car
'This is my car'.slice(-6, -4) //my
split(separator)
split() truncates a string when it finds a pattern (case sensitive), and returns an array with the tokens:
const phrase = 'I love my dog! Dogs are great'
const tokens = phrase.split('dog')
tokens //["I love my ", "! Dogs are great"]
startsWith(str)
Check if a string starts with the value of the string str
You can call startsWith() on any string, provide a substring, and check if the result returns true or false :
'testing'.startsWith('test') //true
'going on testing'.startsWith('test') //false
This method accepts a second parameter, which lets you specify at which character you want to start checking:
'testing'.startsWith('test', 2) //false
'going on testing'.startsWith('test', 9) //true
substring()
substring() returns a portion of a string and it’s similar to slice() , with some key differences.
If any parameter is negative, it is converted to 0 . If any parameter is higher than the string length, it is converted to the length of the string.
So:
'This is my car'.substring(5) //'is my car'
'This is my car'.substring(5, 10) //'is my'
'This is my car'.substring(5, 200) //'is my car'
'This is my car'.substring(-6) //'This is my car'
'This is my car'.substring(-6, 2) //'Th'
'This is my car'.substring(-6, 200) //'This is my car'
toLocaleLowerCase()
Returns a new string with the lowercase transformation of the original string, according to the locale case mappings.
The first parameter represents the locale, but it’s optional (and if omitted, the current locale is used):
'Testing'.toLocaleLowerCase() //'testing'
'Testing'.toLocaleLowerCase('it') //'testing'
'Testing'.toLocaleLowerCase('tr') //'testing'
As usual with internationalization we might not recognize the benefits, but I read on MDN that Turkish does not have the same case mappings at other languages, to start with.
toLocaleUpperCase()
Returns a new string with the uppercase transformation of the original string, according to the locale case mappings.
The first parameter represents the locale, but it’s optional (and if omitted, the current locale is used):
'Testing'.toLocaleUpperCase() //'TESTING'
'Testing'.toLocaleUpperCase('it') //'TESTING'
'Testing'.toLocaleUpperCase('tr') //'TESTİNG'
toLowerCase()
Return a new string with the text all in lower case.
Same as toLocaleLowerCase() , but does not consider locales at all.
'Testing'.toLowerCase() //'testing'
toString()
Returns the string representation of the current String object:
const str = new String('Test')
str.toString() //'Test'
Same as valueOf() .
toUpperCase()
Return a new string with the text all in lower case.
Same as toLocaleUpperCase() , but does not consider locales at all.
'Testing'.toUpperCase() //'TESTING'
trim()
Return a new string with removed white space from the beginning and the end of the original string
'Testing'.trim() //'Testing'
' Testing'.trim() //'Testing'
' Testing '.trim() //'Testing'
'Testing '.trim() //'Testing'
trimEnd()
Return a new string with removed white space from the end of the original string
'Testing'.trimEnd() //'Testing'
' Testing'.trimEnd() //' Testing'
' Testing '.trimEnd() //' Testing'
'Testing '.trimEnd() //'Testing'
trimRight() is an alias of this method.
trimStart()
Return a new string with removed white space from the start of the original string
'Testing'.trimStart() //'Testing'
' Testing'.trimStart() //'Testing'
' Testing '.trimStart() //'Testing '
'Testing'.trimStart() //'Testing'
trimLeft() is an alias of this method.
valueOf()
Returns the string representation of the current String object:
const str = new String('Test')
str.valueOf() //'Test'
Same as toString() .
Math
The Math object contains lots of math-related utilities.
It provides us a lot of properties and functions that we can use to perform calculations.
Properties
| Item | Description |
|---|---|
Math.E |
e , base of the natural logarithm (means ~2.71828) |
Math.LN10 |
represents the base e (natural) logarithm of 10 |
Math.LN2 |
represents the base e (natural) logarithm of 2 |
Math.LOG10E |
represents the base 10 logarithm of e |
Math.LOG2E |
represents the base 2 logarithm of e |
Math.PI |
the π constant (~3.14159) |
Math.SQRT1_2 |
represents the reciprocal of the square root of 2 |
Math.SQRT2 |
represents the square root of 2 |
Methods
All those methods are static. Math cannot be instantiated.
Math.abs()
Returns the absolute value of a number
Math.abs(2.5) //2.5
Math.abs(-2.5) //2.5
Math.acos()
Returns the arccosine of the operand
The operand must be between -1 and 1
Math.acos(0.8) //0.6435011087932843
Math.asin()
Returns the arcsine of the operand
The operand must be between -1 and 1
Math.asin(0.8) //0.9272952180016123
Math.atan()
Returns the arctangent of the operand
Math.atan(30) //1.5374753309166493
Math.atan2()
Returns the arctangent of the quotient of its arguments.
Math.atan2(30, 20) //0.982793723247329
Math.ceil()
Rounds a number up
Math.ceil(2.5) //3
Math.ceil(2) //2
Math.ceil(2.1) //3
Math.ceil(2.99999) //3
Math.cos()
Return the cosine of an angle expressed in radiants
Math.cos(0) //1
Math.cos(Math.PI) //-1
Math.exp()
Return the value of Math.E multiplied per the exponent that’s passed as argument
Math.exp(1) //2.718281828459045
Math.exp(2) //7.38905609893065
Math.exp(5) //148.4131591025766
Math.floor()
Rounds a number down
Math.floor(2.5) //2
Math.floor(2) //2
Math.floor(2.1) //2
Math.floor(2.99999) //2
Math.log()
Return the base e (natural) logarithm of a number
Math.log(10) //2.302585092994046
Math.log(Math.E) //1
Math.max()
Return the highest number in the set of numbers passed
Math.max(1,2,3,4,5) //5
Math.max(1) //1
Math.min()
Return the smallest number in the set of numbers passed
Math.max(1,2,3,4,5) //1
Math.max(1) //1
Math.pow()
Return the first argument raised to the second argument
Math.pow(1, 2) //1
Math.pow(2, 1) //2
Math.pow(2, 2) //4
Math.pow(2, 4) //16
Math.random()
Returns a pseudorandom number between 0.0 and 1.0
Math.random() //0.9318168241227056
Math.random() //0.35268950194094395
Math.round()
Rounds a number to the nearest integer
Math.round(1.2) //1
Math.round(1.6) //2
Math.sin()
Calculates the sin of an angle expressed in radiants
Math.sin(0) //0
Math.sin(Math.PI) //1.2246467991473532e-16)
Math.sqrt()
Return the square root of the argument
Math.sqrt(4) //2
Math.sqrt(16) //4
Math.sqrt(5) //2.23606797749979
Math.tan()
Calculates the tangent of an angle expressed in radiants
Math.tan(0) //0
Math.tan(Math.PI) //-1.2246467991473532e-16
Regular Expressions
A regular expression (also called regex ) is a way to work with strings, in a very performant way.
By formulating a regular expression with a special syntax, you can
- search text a string
- replace substrings in a string
- extract information from a string
Almost every programming language implements regular expressions. There are small differences between each implementation, but the general concepts apply almost everywhere.
Regular Expressions date back to the 1950s, when it was formalized as a conceptual search pattern for string processing algorithms.
Implemented in UNIX tools like grep, sed, and in popular text editors, regexes grew in popularity and were introduced in the Perl programming language, and later in many others.
JavaScript, among with Perl, is one of the programming languages that have regular expressions support directly built in the language.
Hard but useful
Regular expressions can appear like absolute nonsense to the beginner, and many times also to the professional developer, if one does not invest the time necessary to understand them.
Cryptic regular expressions are hard to write , hard to read , and hard to maintain/modify .
But sometimes a regular expression is the only sane way to perform some string manipulation, so it’s a very valuable tool in your pocket.
This tutorial aims to introduce you to JavaScript Regular Expressions in a simple way, and give you all the information to read and create regular expressions.
The rule of thumb is that simple regular expressions are simple to read and write, while complex regular expressions can quickly turn into a mess if you don’t deeply grasp the basics.
How does a Regular Expression look like
In JavaScript, a regular expression is an object , which can be defined in two ways.
The first is by instantiating a new RegExp object using the constructor:
const re1 = new RegExp('hey')
The second is using the regular expression literal form:
const re1 = /hey/
You know that JavaScript has object literals and array literals ? It also has regex literals .
In the example above, hey is called the pattern . In the literal form it’s delimited by forward slashes, while with the object constructor, it’s not.
This is the first important difference between the two forms, but we’ll see others later.
How does it work?
The regular expression we defined as re1 above is a very simple one. It searches the string hey , without any limitation: the string can contain lots of text, and hey in the middle, and the regex is satisfied. It could also contains just hey , and it will be satisfied as well.
That’s pretty simple.
You can test the regex using RegExp.test(String) , which returns a boolean:
re1.test('hey') //✅
re1.test('blablabla hey blablabla') //✅
re1.test('he') //❌
re1.test('blablabla') //❌
In the above example we just checked if "hey" satisfies the regular expression pattern stored in re1 .
This is the simplest it can be, but you already know lots of concepts about regexes.
Anchoring
/hey/
matches hey wherever it was put inside the string.
If you want to match strings that start with hey , use the ^ operator:
/^hey/.test('hey') //✅
/^hey/.test('bla hey') //❌
If you want to match strings that end with hey , use the $ operator:
/hey$/.test('hey') //✅
/hey$/.test('bla hey') //✅
/hey$/.test('hey you') //❌
Combine those, and match strings that exactly match hey , and just that string:
/^hey$/.test('hey') //✅
To match a string that starts with a substring and ends with another, you can use .* , which matches any character repeated 0 or more times:
/^hey.*joe$/.test('hey joe') //✅
/^hey.*joe$/.test('heyjoe') //✅
/^hey.*joe$/.test('hey how are you joe') //✅
/^hey.*joe$/.test('hey joe!') //❌
Match items in ranges
Instead of matching a particular string, you can choose to match any character in a range, like:
/[a-z]/ //a, b, c, ... , x, y, z
/[A-Z]/ //A, B, C, ... , X, Y, Z
/[a-c]/ //a, b, c
/[0-9]/ //0, 1, 2, 3, ... , 8, 9
These regexes match strings that contain at least one of the characters in those ranges:
/[a-z]/.test('a') //✅
/[a-z]/.test('1') //❌
/[a-z]/.test('A') //❌
/[a-c]/.test('d') //❌
/[a-c]/.test('dc') //✅
Ranges can be combined:
/[A-Za-z0-9]/
/[A-Za-z0-9]/.test('a') //✅
/[A-Za-z0-9]/.test('1') //✅
/[A-Za-z0-9]/.test('A') //✅
Matching a range item multiple times
You can check if a string contains one an only one character in a range, by using the - char:
/^[A-Za-z0-9]$/
/^[A-Za-z0-9]$/.test('A') //✅
/^[A-Za-z0-9]$/.test('Ab') //❌
Negating a pattern
The ^ character at the beginning of a pattern anchors it to the beginning of a string.
Used inside a range, it negates it, so:
/[^A-Za-z0-9]/.test('a') //❌
/[^A-Za-z0-9]/.test('1') //❌
/[^A-Za-z0-9]/.test('A') //❌
/[^A-Za-z0-9]/.test('@') //✅
Meta characters
-
\dmatches any digit, equivalent to[0-9] -
\Dmatches any character that’s not a digit, equivalent to[^0-9] -
\wmatches any alphanumeric character (plus underscore), equivalent to[A-Za-z_0-9] -
\Wmatches any non-alphanumeric character, anything except[^A-Za-z_0-9] -
\smatches any whitespace character: spaces, tabs, newlines and Unicode spaces -
\Smatches any character that’s not a whitespace -
\0matches null -
\nmatches a newline character -
\tmatches a tab character -
\uXXXXmatches a unicode character with code XXXX (requires theuflag) -
.matches any character that is not a newline char (e.g.\n) (unless you use thesflag, explained later on) -
[^]matches any character, including newline characters. It’s useful on multiline strings
Regular expressions choices
If you want to search one string or another, use the | operator.
/hey|ho/.test('hey') //✅
/hey|ho/.test('ho') //✅
Quantifiers
Say you have this regex, that checks if a string has one digit in it, and nothing else:
/^\d$/
You can use the ? quantifier to make it optional, thus requiring zero or one:
/^\d?$/
but what if you want to match multiple digits?
You can do it in 4 ways, using + , * , {n} and {n,m} .
+
Match one or more (>=1) items
/^\d+$/
/^\d+$/.test('12') //✅
/^\d+$/.test('14') //✅
/^\d+$/.test('144343') //✅
/^\d+$/.test('') //❌
/^\d+$/.test('1a') //❌
*
Match 0 or more (>= 0) items
/^\d+$/
/^\d*$/.test('12') //✅
/^\d*$/.test('14') //✅
/^\d*$/.test('144343') //✅
/^\d*$/.test('') //✅
/^\d*$/.test('1a') //❌
{n}
Match exactly n items
/^\d{3}$/
/^\d{3}$/.test('123') //✅
/^\d{3}$/.test('12') //❌
/^\d{3}$/.test('1234') //❌
/^[A-Za-z0-9]{3}$/.test('Abc') //✅
{n,m}
Match between n and m times:
/^\d{3,5}$/
/^\d{3,5}$/.test('123') //✅
/^\d{3,5}$/.test('1234') //✅
/^\d{3,5}$/.test('12345') //✅
/^\d{3,5}$/.test('123456') //❌
m can be omitted to have an open ending to have at least n items:
/^\d{3,}$/
/^\d{3,}$/.test('12') //❌
/^\d{3,}$/.test('123') //✅
/^\d{3,}$/.test('12345') //✅
/^\d{3,}$/.test('123456789') //✅
Optional items
Following an item with ? makes it optional:
/^\d{3}\w?$/
/^\d{3}\w?$/.test('123') //✅
/^\d{3}\w?$/.test('123a') //✅
/^\d{3}\w?$/.test('123ab') //❌
Groups
Using parentheses, you can create groups of characters: (...)
This example matches exactly 3 digits followed by one or more alphanumeric characters:
/^(\d{3})(\w+)$/
/^(\d{3})(\w+)$/.test('123') //❌
/^(\d{3})(\w+)$/.test('123s') //✅
/^(\d{3})(\w+)$/.test('123something') //✅
/^(\d{3})(\w+)$/.test('1234') //✅
Repetition characters put after a group closing parentheses refer to the whole group:
/^(\d{2})+$/
/^(\d{2})+$/.test('12') //✅
/^(\d{2})+$/.test('123') //❌
/^(\d{2})+$/.test('1234') //✅
Capturing Groups
So far, we’ve seen how to test strings and check if they contain a certain pattern.
A very cool feature of regular expressions is the ability to capture parts of a string , and put them into an array.
You can do so using Groups, and in particular Capturing Groups .
By default, a Group is a Capturing Group. Now, instead of using RegExp.test(String) , which just returns a boolean if the pattern is satisfied, we use one of
String.match(RegExp)RegExp.exec(String)
They are exactly the same, and return an Array with the whole matched string in the first item, then each matched group content.
If there is no match, it returns null :
'123s'.match(/^(\d{3})(\w+)$/)
//Array [ "123s", "123", "s" ]
/^(\d{3})(\w+)$/.exec('123s')
//Array [ "123s", "123", "s" ]
'hey'.match(/(hey|ho)/)
//Array [ "hey", "hey" ]
/(hey|ho)/.exec('hey')
//Array [ "hey", "hey" ]
/(hey|ho)/.exec('ha!')
//null
When a group is matched multiple times, only the last match is put in the result array:
'123456789'.match(/(\d)+/)
//Array [ "123456789", "9" ]
Optional groups
A capturing group can be made optional by using (...)? . If it’s not found, the resulting array slot will contain undefined :
/^(\d{3})(\s)?(\w+)$/.exec('123 s') //Array [ "123 s", "123", " ", "s" ]
/^(\d{3})(\s)?(\w+)$/.exec('123s') //Array [ "123s", "123", undefined, "s" ]
Reference matched groups
Every group that’s matched is assigned a number. $1 refers to the first, $2 to the second, and so on. This will be useful when we’ll later talk about replacing parts of a string.
Named Capturing Groups
This is a new, ES2018 feature.
A group can be assigned to a name, rather than just being assigned a slot in the result array:
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/
const result = re.exec('2015-01-02')
// result.groups.year === '2015';
// result.groups.month === '01';
// result.groups.day === '02';

Using match and exec without groups
There is a difference with using match and exec without groups: the first item in the array is not the whole matched string, but the match directly:
/hey|ho/.exec('hey') // [ "hey" ]
/(hey).(ho)/.exec('hey ho') // [ "hey ho", "hey", "ho" ]
Noncapturing Groups
Since by default groups are Capturing Groups, you need a way to ignore some groups in the resulting array. This is possible using Noncapturing Groups , which start with an (?:...)
'123s'.match(/^(\d{3})(?:\s)(\w+)$/)
//null
'123 s'.match(/^(\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
Flags
You can use the following flags on any regular expression:
-
g: matches the pattern multiple times -
i: makes the regex case insensitive -
m: enables multiline mode. In this mode,^and$match the start and end of the whole string. Without this, with multiline strings they match the beginning and end of each line. -
u: enables support for unicode (introduced in ES6/ES2015) -
s: (new in ES2018 short for single line , it causes the.to match new line characters as well
Flags can be combined, and they are added at the end of the string in regex literals:
/hey/ig.test('HEy') //✅
or as the second parameter with RegExp object constructors:
new RegExp('hey', 'ig').test('HEy') //✅
Inspecting a regex
Given a regex, you can inspect its properties:
-
sourcethe pattern string -
multilinetrue with themflag -
globaltrue with thegflag -
ignoreCasetrue with theiflag lastIndex
/^(\w{3})$/i.source //"^(\\d{3})(\\w+)$"
/^(\w{3})$/i.multiline //false
/^(\w{3})$/i.lastIndex //0
/^(\w{3})$/i.ignoreCase //true
/^(\w{3})$/i.global //false
Escaping
These characters are special:
\/[ ]( ){ }?+*|.^$
They are special because they are control characters that have a meaning in the regular expression pattern, so if you want to use them inside the pattern as matching characters, you need to escape them, by prepending a backslash:
/^\\$/
/^\^$/ // /^\^$/.test('^') ✅
/^\$/ // /^\$/.test('
String boundaries
\b and \B let you inspect whether a string is at the beginning or at the end of a word:
-
\bmatches a set of characters at the beginning or end of a word -
\Bmatches a set of characters not at the beginning or end of a word
Example:
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //null
Replacing using Regular Expressions
We already saw how to check if a string contains a pattern.
We also saw how to extract parts of a string to an array, matching a pattern.
Let’s see how to replace parts of a string based on a pattern.
The String object in JavaScript has a replace() method, which can be used without regular expressions to perform a single replacement on a string:
"Hello world!".replace('world', 'dog') //Hello dog!
"My dog is a good dog!".replace('dog', 'cat') //My cat is a good dog!
This method also accepts a regular expression as argument:
"Hello world!".replace(/world/, 'dog') //Hello dog!
Using the g flag is the only way to replace multiple occurrences in a string in vanilla JavaScript:
"My dog is a good dog!".replace(/dog/g, 'cat') //My cat is a good cat!
Groups let us do more fancy things, like moving around parts of a string:
"Hello, world!".replace(/(\w+), (\w+)!/, '$2: $1!!!')
// "world: Hello!!!"
Instead of using a string you can use a function, to do even fancier things. It will receive a number of arguments like the one returned by String.match(RegExp) or RegExp.exec(String) , with a number of arguments that depends on the number of groups:
"Hello, world!".replace(/(\w+), (\w+)!/, (matchedString, first, second) => {
console.log(first);
console.log(second);
return `${second.toUpperCase()}: ${first}!!!`
})
//"WORLD: Hello!!!"
Greediness
Regular expressions are said to be greedy by default.
What does it mean?
Take this regex
/\$(.+)\s?/
It is supposed to extract a dollar amount from a string
/\$(.+)\s?/.exec('This costs $100')[1]
//100
but if we have more words after the number, it freaks off
/\$(.+)\s?/.exec('This costs $100 and it is less than $200')[1]
//100 and it is less than $200
Why? Because the regex after the $ sign matches any character with .+ , and it won’t stop until it reaches the end of the string. Then, it finishes off because \s? makes the ending space optional.
To fix this, we need to tell the regex to be lazy, and perform the least amount of matching possible. We can do so using the ? symbol after the quantifier:
/\$(.+?)\s/.exec('This costs $100 and it is less than $200')[1]
//100
I removed the
?after\sotherwise it matched only the first number, since the space was optional
So, ? means different things based on its position, because it can be both a quantifier and a lazy mode indicator.
Lookaheads: match a string depending on what follows it
Use ?= to match a string that’s followed by a specific substring:
/Roger(?=Waters)/
/Roger(?= Waters)/.test('Roger is my dog') //false
/Roger(?= Waters)/.test('Roger is my dog and Roger Waters is a famous musician') //true
?! performs the inverse operation, matching if a string is not followed by a specific substring:
/Roger(?!Waters)/
/Roger(?! Waters)/.test('Roger is my dog') //true
/Roger(?! Waters)/.test('Roger Waters is a famous musician') //false
Lookbehinds: match a string depending on what precedes it
This is an ES2018 feature.
Lookaheads use the ?= symbol. Lookbehinds use ?<= .
/(?<=Roger) Waters/
/(?<=Roger) Waters/.test('Pink Waters is my dog') //false
/(?<=Roger) Waters/.test('Roger is my dog and Roger Waters is a famous musician') //true
A lookbehind is negated using ?<! :
/(?<!Roger) Waters/
/(?<!Roger) Waters/.test('Pink Waters is my dog') //true
/(?<!Roger) Waters/.test('Roger is my dog and Roger Waters is a famous musician') //false
Regular Expressions and Unicode
The u flag is mandatory when working with Unicode strings, in particular when you might need to handle characters in astral planes, the ones that are not included in the first 1600 Unicode characters.
Like Emojis, for example, but not just those.
If you don’t add that flag, this simple regex that should match one character will not work, because for JavaScript that emoji is represented internally by 2 characters:
/^.$/.test('a') //✅
/^.$/.test('🐶') //❌
/^.$/u.test('🐶') //✅
So, always use the u flag.
Unicode, just like normal characters, handle ranges:
/[a-z]/.test('a') //✅
/[1-9]/.test('1') //✅
/[🐶-🦊]/u.test('🐺') //✅
/[🐶-🦊]/u.test('🐛') //❌
JavaScript checks the internal code representation, so  <
<  <
<  because
because \u1F436 < \u1F43A < \u1F98A . Check the full Emoji list to get those codes, and to find out the order (tip: the macOS Emoji picker has some emojis in a mixed order, don’t count on it)
Unicode property escapes
As we saw above, in a regular expression pattern you can use \d to match any digit, \s to match any character that’s not a white space, \w to match any alphanumeric character, and so on.
Unicode property escapes is an ES2018 feature that introduces a very cool feature, extending this concept to all Unicode characters introducing \p{} and is negation \P{} .
Any Unicode character has a set of properties. For example, Script determines the language family, ASCII is a boolean that’s true for ASCII characters, and so on. You can put this property in the graph parentheses, and the regex will check for that to be true:
/^\p{ASCII}+$/u.test('abc') //✅
/^\p{ASCII}+$/u.test('ABC@') //✅
/^\p{ASCII}+$/u.test('ABC🙃') //❌
ASCII_Hex_Digit is another boolean property, that checks if the string only contains valid hexadecimal digits:
/^\p{ASCII_Hex_Digit}+$/u.test('0123456789ABCDEF') //✅
/^\p{ASCII_Hex_Digit}+$/u.test('h') //❌
There are many other boolean properties, which you just check by adding their name in the graph parentheses, including Uppercase , Lowercase , White_Space , Alphabetic , Emoji and more:
/^\p{Lowercase}$/u.test('h') //✅
/^\p{Uppercase}$/u.test('H') //✅
/^\p{Emoji}+$/u.test('H') //❌
/^\p{Emoji}+$/u.test('🙃🙃') //✅
In addition to those binary properties, you can check any of the unicode character properties to match a specific value. In this example, I check if the string is written in the greek or latin alphabet:
/^\p{Script=Greek}+$/u.test('ελληνικά') //✅
/^\p{Script=Latin}+$/u.test('hey') //✅
Read more about all the properties you can use [directly on the TC39
proposal](https://github.com/tc39/proposal-regexp-unicode-property-escapes).
Examples
Extract a number from a string
Supposing a string has only one number you need to extract, /\d+/ should do it:
'Test 123123329'.match(/\d+/)
// Array [ "123123329" ]
Match an email address
A simplistic approach is to check non-space characters before and after the @ sign, using \S :
/(\S+)@(\S+)\.(\S+)/
/(\S+)@(\S+)\.(\S+)/.exec('copesc@gmail.com')
//["copesc@gmail.com", "copesc", "gmail", "com"]
This is a simplistic example however, as many invalid emails are still satisfied by this regex.
Capture text between double quotes
Suppose you have a string that contains something in double quotes, and you want to extract that content.
The best way to do so is by using a capturing group , because we know the match starts and ends with " , and we can easily target it, but we also want to remove those quotes from our result.
We’ll find what we need in result[1] :
const hello = 'Hello "nice flower"'
const result = /"([^']*)"/.exec(hello)
//Array [ "\"nice flower\"", "nice flower" ]
Get the content inside an HTML tag
For example, get the content inside a span tag, allowing any number of arguments inside the tag:
/<span\b[^>]*>(.*?)<\/span>/
/<span\b[^>]*>(.*?)<\/span>/.exec('test')
// null
/<span\b[^>]*>(.*?)<\/span>/.exec('<span>test</span>')
// ["<span>test</span>", "test"]
/<span\b[^>]*>(.*?)<\/span>/.exec('<span class="x">test</span>')
// ["<span class="x">test</span>", "test"]
```) ✅
``