Introduction to functions
A function is a block of code, self contained, that can be defined once and run any times you want.
A function can optionally accept parameters, and returns one value.
Functions in JavaScript are objects . Their superpower lies in the fact that they can be invoked.
Functions in JavaScript are called first class functions because they can be assigned to a value, and they can be passed as arguments and used as a return value.
Syntax for functions
Let’s start with the “old”, pre-ES6/2015 syntax. Here’s a function declaration :
function doSomething(foo) {
// do something
}
(now, in post ES6/ES2015 world, referred as a regular function )
Functions can be assigned to variables (this is called a function expression ):
const doSomething = function(foo) {
// do something
}
Named function expressions are similar, but play nicer with the stack call trace, which is useful when an error occurs - it holds the name of the function:
const doSomething = function doSomething(foo) {
// do something
}
ES6/ES2015 introduced arrow functions , which are especially nice to use when working with inline functions, as parameters or callbacks:
const doSomething = foo => {
//do something
}
Arrow functions have an important difference from the other function definitions above, we’ll see which one in the next lesson.
Arrow functions
Arrow functions were introduced in ES6 / ECMAScript 2015, and since their introduction they changed forever how JavaScript code looks (and works).
In my opinion this change was so welcoming that you now rarely see the usage of the function keyword in modern codebases.
Visually, it’s a simple and welcome change, which allows you to write functions with a shorter syntax, from:
const myFunction = function() {
//...
}
to
const myFunction = () => {
//...
}
If the function body contains just a single statement, you can omit the brackets and write all on a single line:
const myFunction = () => doSomething()
Parameters are passed in the parentheses:
const myFunction = (param1, param2) => doSomething(param1, param2)
If you have one (and just one) parameter, you could omit the parentheses completely:
const myFunction = param => doSomething(param)
Thanks to this short syntax, arrow functions encourage the use of small functions .
Implicit return
Arrow functions allow you to have an implicit return: values are returned without having to use the return keyword.
It works when there is a one-line statement in the function body:
const myFunction = () => 'test'
myFunction() //'test'
Another example, when returning an object, remember to wrap the curly brackets in parentheses to avoid it being considered the wrapping function body brackets:
const myFunction = () => ({ value: 'test' })
myFunction() //{value: 'test'}
How this works in arrow functions
this is a concept that can be complicated to grasp, as it varies a lot depending on the context and also varies depending on the mode of JavaScript ( strict mode or not).
It’s important to clarify this concept because arrow functions behave very differently compared to regular functions.
When defined as a method of an object, in a regular function this refers to the object, so you can do:
const car = {
model: 'Fiesta',
manufacturer: 'Ford',
fullName: function() {
return `${this.manufacturer} ${this.model}`
}
}
calling car.fullName() will return "Ford Fiesta" .
The this scope with arrow functions is inherited from the execution context. An arrow function does not bind this at all, so its value will be looked up in the call stack, so in this code car.fullName() will not work, and will return the string "undefined undefined" :
const car = {
model: 'Fiesta',
manufacturer: 'Ford',
fullName: () => {
return `${this.manufacturer} ${this.model}`
}
}
Due to this, arrow functions are not suited as object methods.
Arrow functions cannot be used as constructors either, when instantiating an object will raise a TypeError .
This is where regular functions should be used instead, when dynamic context is not needed .
This is also a problem when handling events. DOM Event listeners set this to be the target element, and if you rely on this in an event handler, a regular function is necessary:
const link = document.querySelector('#link')
link.addEventListener('click', () => {
// this === window
})
const link = document.querySelector('#link')
link.addEventListener('click', function() {
// this === link
})
and you won’t need to write var that = this ever again.
Parameters
A function can accept one or more parameters.
const dosomething = () => {
//do something
}
const dosomethingElse = foo => {
//do something
}
const dosomethingElseAgain = (foo, bar) => {
//do something
}
Starting with ES6/ES2015, functions can have default values for the parameters:
const dosomething = (foo = 1, bar = 'hey') => {
//do something
}
This allows you to call a function without filling all the parameters:
dosomething(3)
dosomething()
ES2018 introduced trailing commas for parameters, a feature that helps reducing bugs due to missing commas when moving around parameters (e.g. moving the last in the middle):
const dosomething = (foo = 1, bar = 'hey',) => {
//do something
}
dosomething(2, 'ho!')
You can wrap all your arguments in an array, and use the spread operator when calling the function:
const dosomething = (foo = 1, bar = 'hey') => {
//do something
}
const args = [2, 'ho!']
dosomething(...args)
With many parameters, remembering the order can be difficult. Using objects, destructuring allows to keep the parameter names:
const dosomething = ({ foo = 1, bar = 'hey' }) => {
//do something
console.log(foo) // 2
console.log(bar) // 'ho!'
}
const args = { foo: 2, bar: 'ho!' }
dosomething(args)
Functions now support default parameters:
const foo = function(index = 0, testing = true) { /* ... */ }
foo()
Default parameter values have been introduced in ES2015, and are widely implemented in modern browsers.
This is a doSomething function which accepts param1 .
const doSomething = (param1) => {
}
We can add a default value for param1 if the function is invoked without specifying a parameter:
const doSomething = (param1 = 'test') => {
}
This works for more parameters as well, of course:
const doSomething = (param1 = 'test', param2 = 'test2') => {
}
What if you have an unique object with parameters values in it?
Once upon a time, if we had to pass an object of options to a function, in order to have default values of those options if one of them was not defined, you had to add a little bit of code inside the function:
const colorize = (options) => {
if (!options) {
options = {}
}
const color = ('color' in options) ? options.color : 'yellow'
...
}
With object destructuring you can provide default values, which simplifies the code a lot:
const colorize = ({ color = 'yellow' }) => {
...
}
If no object is passed when calling our colorize function, similarly we can assign an empty object by default:
const spin = ({ color = 'yellow' } = {}) => {
...
}
Return value
Every function returns a value, which by default is undefined .
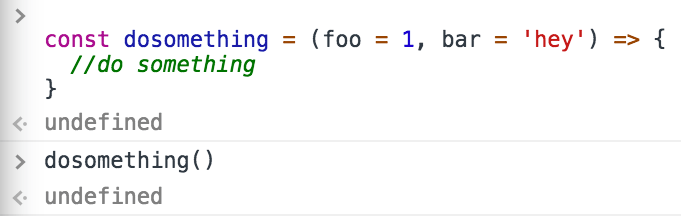
Any function is terminated when its lines of code end, or when the execution flow finds a return keyword.
When JavaScript encounters this keyword it exits the function execution and gives control back to its caller.
If you pass a value, that value is returned as the result of the function:
const dosomething = () => {
return 'test'
}
const result = dosomething() // result === 'test'
You can only return one value.
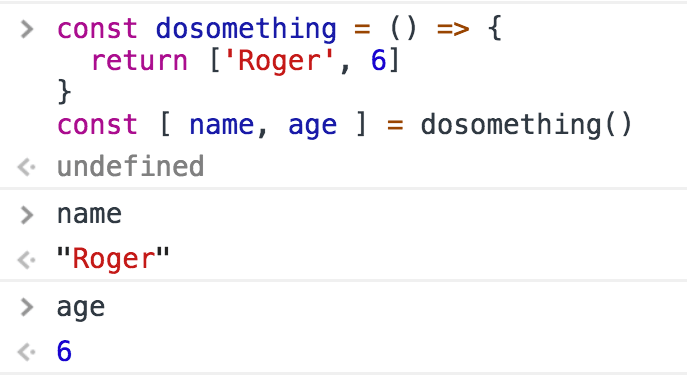
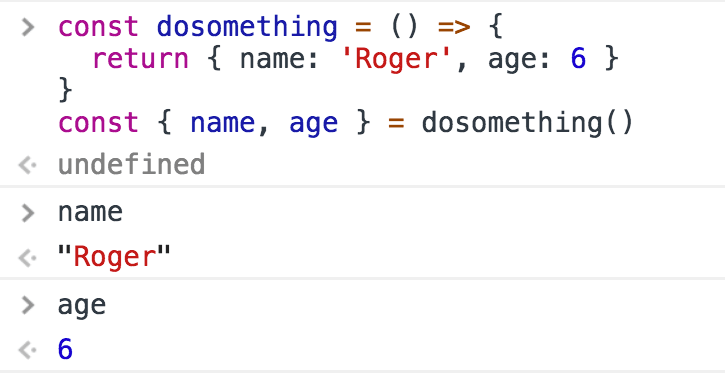
To simulate returning multiple values, you can return an object literal , or an array , and use a destructuring assignment when calling the function.
Using arrays:
Using objects:
The Event Loop
The Event Loop is one of the most important aspects to understand about JavaScript.
This post aims to explain the inner details of how JavaScript works with a single thread, and how it handles asynchronous functions.
Your JavaScript code runs single threaded. There is just one thing happening at a time.
This is a limitation that’s actually very helpful, as it simplifies a lot how you program without worrying about concurrency issues.
You just need to pay attention to how you write your code and avoid anything that could block the thread, like synchronous network calls or infinite loops.
In general, in most browsers there is an event loop for every browser tab, to make every process isolated and avoid a web page with infinite loops or heavy processing to block your entire browser.
The environment manages multiple concurrent event loops, to handle API calls for example. Web Workers run in their own event loop as well.
You mainly need to be concerned that your code will run on a single event loop, and write code with this thing in mind to avoid blocking it.
Blocking the event loop
Any JavaScript code that takes too long to return back control to the event loop will block the execution of any JavaScript code in the page, even block the UI thread, and the user cannot click around, scroll the page, and so on.
Almost all the I/O primitives in JavaScript are non-blocking. Network requests, Node.js filesystem operations, and so on. Being blocking is the exception, and this is why JavaScript is based so much on callbacks, and more recently on promises and async/await. More about those soon.
The call stack
The call stack is a LIFO queue (Last In, First Out).
The event loop continuously checks the call stack to see if there’s any function that needs to run.
While doing so, it adds any function call it finds to the call stack and executes each one in order.
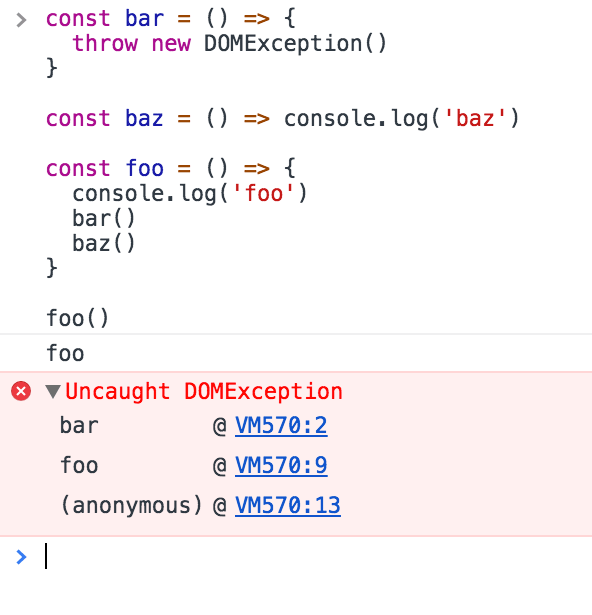
You know the error stack trace you might be familiar with, in the debugger or in the browser console? The browser looks up the function names in the call stack to inform you which function originates the current call:
How the event loop works in practice
Let’s pick an example:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
bar()
baz()
}
foo()
This code prints
foo
bar
baz
as expected.
When this code runs, first foo() is called. Inside foo() we first call bar() , then we call baz() .
At this point the call stack looks like this:
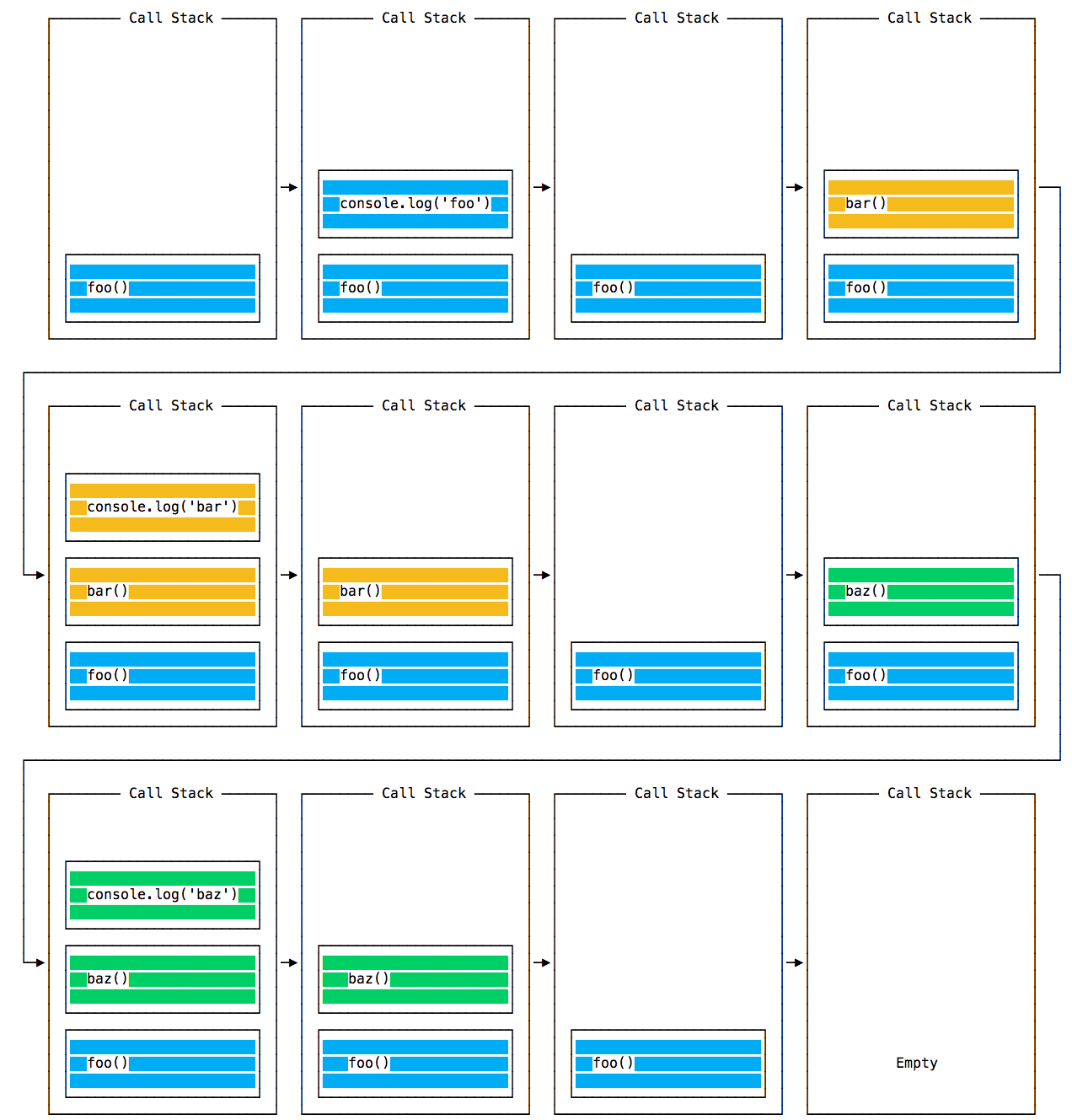
The event loop on every iteration looks if there’s something in the call stack, and executes it:
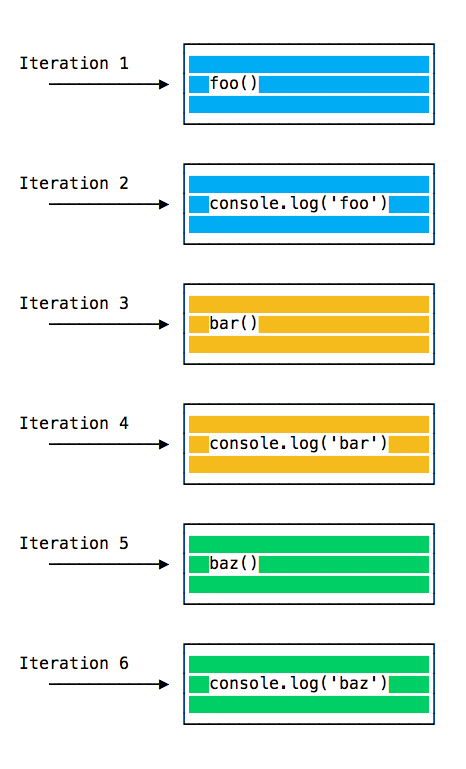
until the call stack is empty.
Recursion
A function can call itself .
This is what recursion means. And it allows us to solve problems in a neat way.
To do so, you need a named function expression, in other words this:
function doSomething() {
}
So we can call doSomething() inside doSomething() .
The simplest example we can make is calculating a factorial of a number. This is the number that we get by multiplying the number for (number - 1), (number - 2), and so on until we reach the number 1.
The factorial of 4 is (4 * (4 - 1) * (4 - 2) * (4 - 3)) = 4 * 3 * 2 * 1, which is 24.
We can create a recursive function to calculate it automatically:
function factorial(n) {
return n >= 1 ? n * factorial(n - 1) : 1
}
factorial(1) //1
factorial(2) //2
factorial(3) //6
factorial(4) //24
We can also use an arrow function if we prefer:
const factorial = (n) => {
return n >= 1 ? n * factorial(n - 1) : 1
}
factorial(1) //1
factorial(2) //2
factorial(3) //6
factorial(4) //24
Now it’s a good time to talk about the call stack .
Imagine we do an error, and instead of calculating the factorial as
const factorial = (n) => {
return n >= 1 ? n * factorial(n - 1) : 1
}
we do this:
const factorial = (n) => {
return n >= 1 ? n * factorial(n) : 1
}
As you can see, we are calling factorial(n) ad infinitum. There’s no end, because we forgot to lower it on every call.
If you run this code, you’ll get this error:
RangeError: Maximum call stack size exceeded
Every time a function is invoked, JavaScript needs to remember the current context before switching to the new one, so it puts that context on the call stack . As soon as the function returns, JavaScript goes to the call stack and picks the last element that was added, and resumes its execution.
Maximum call stack size exceeded means that too many elements were put on the stack, and your program crashed.
Immediately-invoked Function Expression
An Immediately-invoked Function Expression (IIFE for friends) is a way to execute functions immediately, as soon as they are created.
IIFEs are very useful because they don’t pollute the global object , and they are a simple way to isolate variables declarations .
This is the syntax that defines an IIFE:
(function() {
/* */
})()
IIFEs can be defined with arrow functions as well:
(() => {
/* */
})()
We basically have a function defined inside parentheses, and then we append () to execute that function: (/* function */)() .
Those wrapping parentheses are actually what make our function, internally, be considered an expression. Otherwise, the function declaration would be invalid, because we didn’t specify any name:
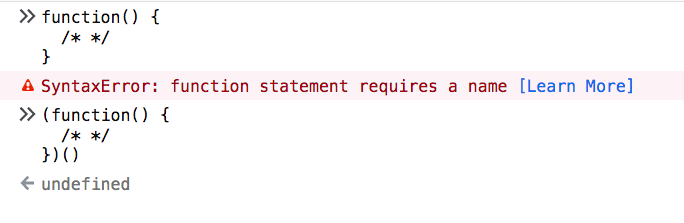
Function declarations want a name, while function expressions do not require it.
You could also put the invoking parentheses inside the expression parentheses, there is no difference, just a styling preference:
(function() {
/* */
}())
(() => {
/* */
}())
Alternative syntax using unary operators
There is some weirder syntax that you can use to create an IIFE, but it’s very rarely used in the real world, and it relies on using any unary operator:
-(function() {
/* */
})() +
(function() {
/* */
})()
~(function() {
/* */
})()
!(function() {
/* */
})()
(does not work with arrow functions)
Named IIFE
An IIFE can also be named regular functions (not arrow functions). This does not change the fact that the function does not “leak” to the global scope, and it cannot be invoked again after its execution:
(function doSomething() {
/* */
})()
IIFEs starting with a semicolon
You might see this in the wild:
;(function() {
/* */
})()
This prevents issues when blindly concatenating two JavaScript files. Since JavaScript does not require semicolons, you might concatenate with a file with some statements in its last line that causes a syntax error.
This problem is essentially solved with “smart” code bundlers like webpack.
Hoisting
JavaScript before executing your code reorders it according to some rules.
Functions in particular are moved at the top of their scope. This is why it’s legal to write
dosomething()
function dosomething() {
console.log('did something')
}

Internally, JavaScript moves the function before its call, along with all the other functions found in the same scope:
function dosomething() {
console.log('did something')
}
dosomething()
Now, if you use named function expressions, since you’re using variables something different happens. The variable declaration is hoisted, but not the value, so not the function.
dosomething()
const dosomething = function dosomething() {
console.log('did something')
}
This example is not going to work:

This is because what happens internally is:
const dosomething
dosomething()
dosomething = function dosomething() {
console.log('did something')
}
The same happens for let declarations. var declarations do not work either, but with a different error:

This is because var declarations are hoisted and initialized with undefined as a value, while const and let are hoisted but not initialized.
Closures
If you’ve ever written a function in JavaScript, you already made use of closures .
It’s a key topic to understand, which has implications on the things you can do.
When a function is run, it’s executed with the scope that was in place when it was defined , and not with the state that’s in place when it is executed .
The scope basically is the set of variables which are visible.
A function remembers its Lexical Scope, and it’s able to access variables that were defined in the parent scope.
In short, a function has an entire baggage of variables it can access.
Let me immediately give an example to clarify this.
const bark = dog => {
const say = `${dog} barked!`
;(() => console.log(say))()
}
bark(`Roger`)
This logs to the console Roger barked! , as expected.
What if you want to return the action instead:
const prepareBark = dog => {
const say = `${dog} barked!`
return () => console.log(say)
}
const bark = prepareBark(`Roger`)
bark()
This snippet also logs to the console Roger barked! .
Let’s make one last example, which reuses prepareBark for two different dogs:
const prepareBark = dog => {
const say = `${dog} barked!`
return () => {
console.log(say)
}
}
const rogerBark = prepareBark(`Roger`)
const sydBark = prepareBark(`Syd`)
rogerBark()
sydBark()
This prints
Roger barked!
Syd barked!
As you can see, the state of the variable say is linked to the function that’s returned from prepareBark() .
Also notice that we redefine a new say variable the second time we call prepareBark() , but that does not affect the state of the first prepareBark() scope.
This is how a closure works: the function that’s returned keeps the original state in its scope.
call() and apply()
call() and apply() are two functions that JavaScript offers to perform a very specific task: call a function and set its this value.
A function can use the this value for many different use cases. The problem is that it’s given by the environment and cannot be changed from the outside, except when using call() or apply() .
When using those methods, you can pass in an additional object that will be used as this in the function invoked.
Those functions perform the same thing, but have a difference. In call() you can pass the function parameters as a comma separated list of parameters, taking as many parameters as you need, while in apply() you pass a single array that contains the parameters:
const car = {
brand: 'Ford',
model: 'Fiesta'
}
const drive = function(from, to, kms) {
console.log(`Driving for ${kms} kilometers from ${from} to ${to} with my car, a ${this.brand} ${this.model}`)
}
drive.call(car, 'Milan', 'Rome', 568)
drive.apply(car, ['Milan', 'Rome', 568])
Note that when using arrow functions this is not bound, so this method only works with regular functions.
Nested functions
Functions can be defined inside other functions:
const dosomething = () => {
const dosomethingelse = () => {
//some code here
}
dosomethingelse()
return 'test'
}
The nested function is scoped to the outside function, and cannot be called from the outside.
This means that dosomethingelse() is not reachable from outside dosomething() :
const dosomething = () => {
const dosomethingelse = () => {
//some code here
}
dosomethingelse()
return 'test'
}
dosomethingelse() //ReferenceError: dosomethingelse is not defined
This is very useful because we can create encapsulated code that is limited in its scope by the outer function it’s defined in.
We could have 2 function define a function with the same name, inside them:
const bark = () => {
const dosomethingelse = () => {
//some code here
}
dosomethingelse()
return 'test'
}
const sleep = () => {
const dosomethingelse = () => {
//some code here
}
dosomethingelse()
return 'test'
}
and most importantly you don’t have to think about overwriting existing functions and variables defined inside other functions.
Quiz
Welcome to the quiz! Try to answer those questions, which cover the topics of this module.
You can also write the question/answer into the Discord chat, to make sure it’s correct - other students or Flavio will check it for you!
- why do we have multiple ways to define functions?
- how are arrow functions different than regular functions?
- object destructuring allows to have a nice way to extract prarameter passed as object properties. Can you write a
run()function that takes an object as parameter, with thedistanceanddestinationproperties, and print them in aconsole.log()? When I callrun()I want you to print the string “I ran for until I got to ”. - Functions return only one value. Which ways do we have to simulate retruning multiple values from a function?
- The event loop is crucial to understanding how JavaScript works. Read the lesson on the event loop and then try to explain how it works
- What would happen if we don’t return anything from a recursive function? Can we even have a recursive function if we don’t return a value?
- can you explain what hoisting is?
- what is the difference between
let/constandvardeclarations in regards to hoisting? - what is a closure?
- what is the difference between
call()andapply() - how can we achieve encapsulation in JavaScript?