«Компьютер — это конечный автомат. Потоковое программирование нужно тем, кто не умеет программировать конечные автоматы». Алан Кокс, прим. Википедия
Как вы уже заметили, одну и ту же программу можно написать множеством различных способов. Если не брать во внимание случаи, когда программа написана просто плохо, то остаются подходы, которые имеют как преимущества, так и недостатки относительно друг друга. Иными словами, вся наша жизнь состоит из компромиссов.
Парадигма программирования
Это совокупность идей и понятий, определяющих стиль написания компьютерных программ (подход к программированию)
Подходы к написанию программ принято называть парадигмами. И эти парадигмы резко отличаются от того, чем они являются в науке.
Своим современным значением в научно-технической области термин «парадигма» обязан, по-видимому, Томасу Куну и его книге «Структура научных революций». Кун называл парадигмами устоявшиеся системы научных взглядов, в рамках которых ведутся исследования. Согласно Куну, в процессе развития научной дисциплины может произойти замена одной парадигмы на другую (как, например, геоцентрическая небесная механика Птолемея сменилась гелиоцентрической системой Коперника), при этом старая парадигма ещё продолжает некоторое время существовать и даже развиваться благодаря тому, что многие её сторонники оказываются по тем или иным причинам неспособны перестроиться для работы в другой парадигме.
Термин «парадигма программирования» впервые применил в 1978 году Роберт Флойд в своей лекции лауреата премии Тьюринга.
Флойд отмечает, что в программировании можно наблюдать явление, подобное парадигмам Куна, но, в отличие от них, парадигмы программирования не являются взаимоисключающими:
Если прогресс искусства программирования в целом требует постоянного изобретения и усовершенствования парадигм, то совершенствование искусства отдельного программиста требует, чтобы он расширял свой репертуар парадигм.
Таким образом, по мнению Роберта Флойда, в отличие от парадигм в научном мире, описанных Куном, парадигмы программирования могут сочетаться, обогащая инструментарий программиста.
А по нашему мнению, каждая новая парадигма в арсенале разработчика делает его профессионалом качественно нового уровня.
Например, владение декларативной парадигмой помогает программисту применять в нужных местах функции высшего порядка, элементы логического программирования, а так же помогает избегать ненужных мутаций состояния. И все это с легкостью можно использовать почти в любом современном императивном языке.
Примеры парадигм
Императивное программирование
Функциональное программирование
Логическое программирование
Программирование, управляемое данными (ООП)
Событийно-ориентированное программирование
Автоматное программирование
Actor-based программирование
Этот курс посвящен одной из самых важных парадигм программирования. Эта парадигма не требует поддержки со стороны языка и применима в бесчисленном количестве ситуаций для управления системами со сложным поведением. То есть поведением, в котором результат операции зависит не только от входных данных, но и от предыдущего состояния системы.
Автоматное программирование
Парадигма программирования, основанная на применении конечных автоматов для описания поведения программ
Автоматное программирование имеет под собой серьезную математическую базу. Сразу предупрежу, что в этом курсе математики не будет. Основная задача курса - дать интуитивное понимание автоматов и научиться их видеть и применять в реальной жизни.
Те, кто хотят узнать про эту тему чуть глубже и стать немного ближе к чистому Computer Science, я рекомендую прочитать про машину Тьюринга.
Темы, затрагиваемые в этом курсе:
Состояние
Конечные автоматы
Диаграмма состояний (UML)
Библиотеки для описания автоматов
Шаблоны проектирования (State, State Machine)
JS: Автоматное программирование → Легкость и виды сложности
Знаете ли вы разницу между словами “простой” и “легкий”? А какое из этих слов является антонимом слова “сложный”?
Чтобы ответить на этот вопрос, обратимся к определению слова “сложность”.
Сложность описывает поведение системы или модели, чьи компоненты взаимодействуют различными способами.
Получается, что “сложный” — это состоящий из большого числа элементов, взаимодействующих друг с другом. Причем, чем больше этого взаимодействия и чем более оно разнообразно, тем более сложная на выходе система.
Отсюда можно сделать вывод, что на обратной стороне находится понятие “простой”. То есть состоящий из одного элемента. В общем случае, конечно, “простой-сложный” — это шкала. Какие-то вещи получаются проще, какие-то сложнее.
Самое главное, что нужно вынести из этих определений: пара простой-сложный — это объективная оценка системы или модели.
С другой стороны, в своей жизни мы часто оперируем другой парой: “легкий-тяжелый”. И вот эта пара уже представляет собой субъективную оценку. Для нас “легкий”, почти всегда означает “привычный”.
Небезызвестный человек Rich Hickey, по совместительству создатель языка Clojure, сделал доклад с названием Simple Made Easy, в котором подробно рассмотрел эти понятия и то, как ошибаются люди, в частности инженеры, принимая решения.
Так уж устроен мозг, что чаще мы фиксируемся на легкости вместо простоты. Потому что простоту увидеть не всегда просто, ведь это непривычно.
Что дает нам легкость:
- Простой старт
Чем мы за это платим:
- Резкое торможение после предела
- Отсутствие нового опыта, а значит роста
- Сложные решения и подходы
И некоторые примеры из жизни программистов:
Simple | Complex
------------------|---------------
Constant | Variable
Data | Object (Hard)
Recursion (Hard) | Loop
Константы (значение) — это просто, переменные сложно (значение, время). Данные (значения) — это просто, объекты это сложно (значение, поведение, идентификация).
Рекурсия, по сравнению с циклом, требует гораздо меньше компонентов и понятий, кроме самой функции не нужно больше ничего. При этом понять рекурсию не так легко. Справедливости ради отметим, что это касается больше тех людей, чей опыт, до момента знакомства с рекурсией был сугубо императивный.
Из сказанного можно сделать вывод, что всегда есть простая альтернатива, которой можно пользоваться. Но это не так, бывают сложные задачи, требующие не простых решений, и если упрощение идет в одном месте, то в другом, скорее всего, нужно будет усложнить.
No Silver Bullet — Essence and Accidents of Software Engineering (Fred Brooks)
Фредерик Брукс, создатель IBM/360 и автор книги “Мифический человеко-месяц”, в своем эссе “No Silver Bullet” сформулировал два типа сложности, знание которых поможет вам лучше понимать свои системы.
Необходимая сложность
Определяется сложностью решаемой проблемы/предметной области.
Если перед вами стоит задача реализовать программу, которая выполняет 20 действий, то вы не можете (с точки зрения программирования, а не бизнеса) реализовать меньше и при этом выполнить задачу. Если у вас есть 5 бизнес-правил, касающихся оформления заказа (например, у вас должно быть достаточно денег на счету), то вам нужно будет их все реализовать.
Очень важно уметь выделять главное и видеть, где у вас та самая, необходимая, сложность.
Случайная сложность
Определяется проблемами, которые создают сами программисты, например, используют неправильные инструменты для данной задачи.
Именно этот тип сложности является опасным и ведущим к краху. Неправильные процессы, подходы, библиотеки, языки, все это, как минимум, вас сильно замедляет, удорожает разработку и, в конце концов, может стать причиной неудачи проекта.
От этой сложности нужно избавляться всеми способами. Главное, что я хотел бы донести до вас в этом уроке: понимание того, где у вас случайная сложность, приходит только с обогащением вас как профессионала. Многие разработчики смотрят на это так: я выучу еще 10 новых библиотек и пару новых языков и стану круче. Да, вы станете чуть лучше, но это будет совсем чуть-чуть. Потому что эти библиотеки и языки будут использовать подходы, к которым вы привыкли, и вам будет легко, а значит роста почти не будет. Единственный способ расти по-настоящему быстро и качественно это изучать то, что дается тяжело, языки с новыми парадигмами, другие области программирования, такие как мобильные приложения, фронтенд вместо бекенда и наоборот.
Автоматное программирование, как раз, относится к одному из таких пунктов. Эта парадигма изменит вас (если вы позволите этому случиться) невероятно сильно и даст возможность лучше определять и искоренять случайную сложность в вашем коде.
P.S. Основные языки для роста: haskell, clojure, prolog, erlang, kotlin, c.
JS: Автоматное программирование → Конечный автомат
По большей части автоматное программирование связано с понятием “конечный автомат”. Не вдаваясь в математические дебри, конечный автомат можно определить следующим образом:
Модель, с помощью которой удобно представлять процесс, имеющий конечное число дискретных управляющих состояний
В первую очередь необходимо обратить внимание на то, что finite-state machine появляется только там, где есть процесс. Возьмем пример с Хекслета. Сущность “курс” участвует в процессе публикации на сайте. Сначала курс не виден, но потом мы его публикуем, и он становится доступным на сайте. При этом, у нас есть возможность произвести обратное действие. Этот же курс участвует и в другом процессе, который можно, грубо, назвать “завершенность”. Наши курсы могут появляться на сайте до того, как мы их запишем до конца. В какой-то момент курс наполняется всеми уроками, и мы переводим конечный автомат в положение “завершен”. Получается, что одна и та же сущность участвует, как минимум, в двух процессах, и каждый обладает своим собственным конечным автоматом.
Второе, что мы видим в этом определении: слово “состояние”. Состояние — основа любого конечного автомата, и по жизни мы периодически пользуемся этим понятием. Тот смысл, который закладывается в него на интуитивном уровне, идентичен смыслу, который закладывается в него при работе с конечными автоматами. Например, человек бывает сытым или голодным, спящим, болеющим и даже, прости господи, мертвым. А вода бывает жидкой, твердой (лед) и газообразной. Это все состояния разных процессов.
В определении уточняется, что состояния должны быть дискретными, другими словами, мы должны иметь возможность проводить четкие различия между разными состояниями процесса. Процесс нагрева воды нельзя представить как конечный автомат, если мы не выделим в нем конкретные точки (состояния), например, теплая вода (50 градусов), горячая вода (80 градусов) и холодная вода (10 градусов).
И последнее. Что значит “управляющие состояния”? Понятие состояния не является чужеродным для мира программирования. В одной из первых лекций я рассказывал о том, что состояние программы это, грубо говоря, слепок её памяти. Другими словами, значение всех переменных в конкретный момент времени. Это, конечно, так, но можно пойти еще дальше и заметить, что состояние можно поделить на два типа. Первый тип — это состояние, отвечающее за все возможные пути движения данных сквозь программу. Второй — это данные сами по себе или так называемое вычислительное состояние.
Если взять тот же пример с курсом, то мы увидим, что в нем, с одной стороны, присутствует управляющее состояние, отвечающее за видимость курса на сайте, с другой стороны, курс наполнен количественными переменными состояниями, такими как количество уроков, ссылки на видео, тексты и квизы.
| Управляющие состояния | Вычислительные состояния |
|---|---|
| Их число не очень велико | Их число либо бесконечно, либо конечно, но очень велико |
| Каждое из них имеет вполне определенный смысл и качественно отличается от других | Большинство из них не имеет смысла и отличается от остальных лишь количественно |
| Они определяют действия, которые совершает сущность | Они непосредственно определяют лишь результаты действий |
Рассмотрим простейший конечный автомат на примере телевизора и процесса включения. В этом процессе участвуют два состояния “включен” и “выключен”, которые меняются по событиям “включить” и “выключить”.

Ниже видно так называемую диаграмму состояний. Это графическое отображение, помогающее визуально представить себе схему переходов между состояниями и увидеть все ограничения системы (не из всех состояний можно перейти во все). Как видите, с телевизором все достаточно просто и интуитивно понятно. Давайте взглянем на более интересный пример:
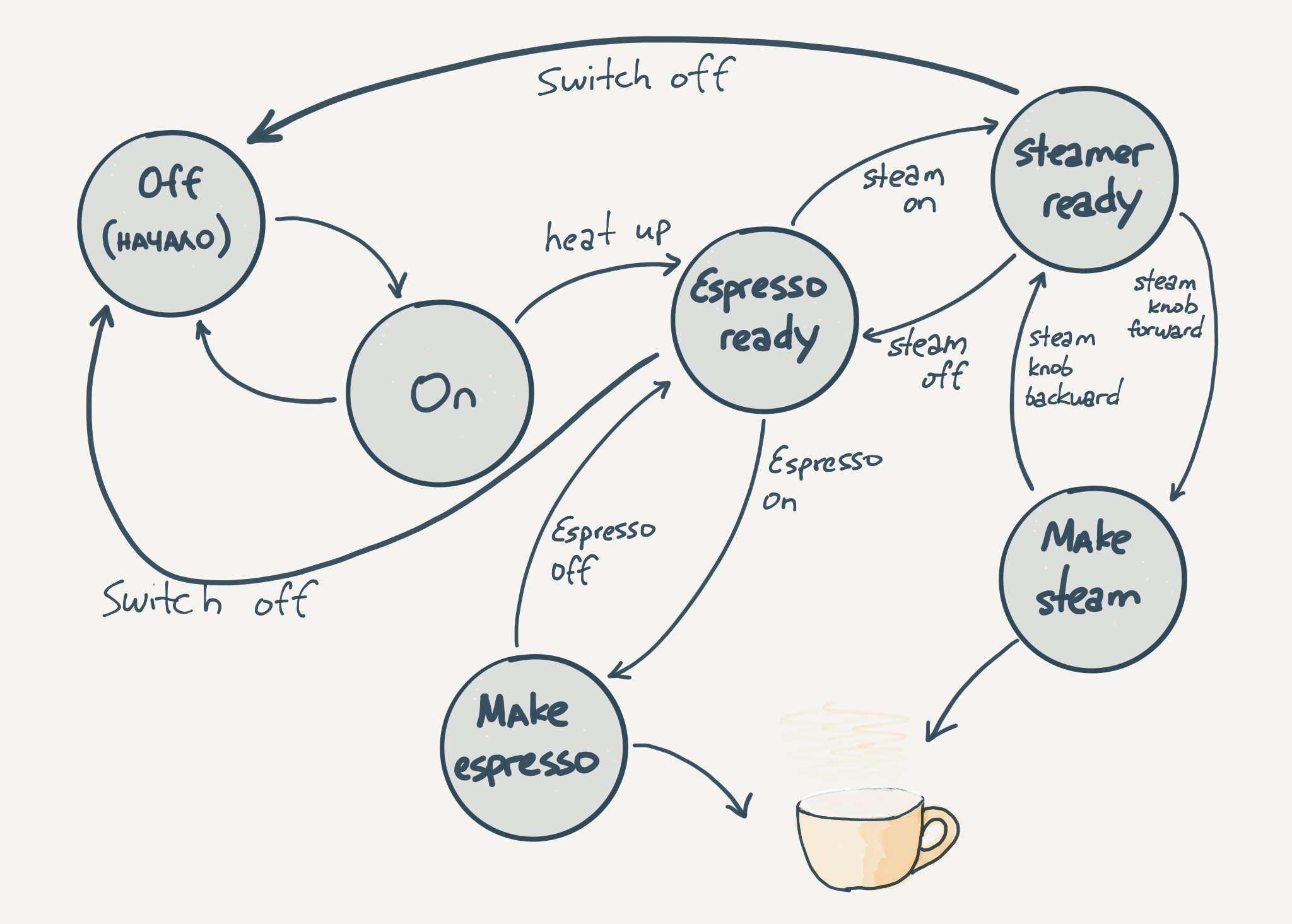
Этот автомат описывает процесс приготовления кофе в кофемашине. Не так тривиально как с телевизором. Что еще может быть описано конечным автоматом?
- Состояние заказа
- Светофор
- Активация симки
- Запуск практики на Хекслете
- Пользовательские интерфейсы (UI)
Лично мне кажется, что проще перечислить то, что не описывается конечным автоматом, чем наоборот.
Вывод
Реальный мир полон процессов, которые описываются конечными автоматами, другими словами, конечные автоматы всегда присутствуют независимо от того, знаем мы про них или нет
Акцентирую на этом ваше внимание. В моей практике часто встречается убеждение у уже опытных программистов, что конечные автоматы усложняют жизнь и/или они нужны только для написания компиляторов. Это большое заблуждение, вызванное отсутствием должной базовой подготовки. Если в вашей программе есть сущность со сложным поведением, то по определению самым простым способом описания ее процессов является конечный автомат.
Распознать сущность со сложным поведением в исходном коде программы можно следующим образом: при традиционной реализации таких сущностей используются логические переменные, называемые флагами, и многочисленные запутанные конструкции ветвления, условиями в которых выступают различные комбинации значений флагов. Такой способ описания логики сложного поведения плохо структурирован, труден для понимания и модификации, подвержен ошибкам.
Одна из центральных идей автоматного программирования состоит в отделении описания логики поведения (при каких условиях необходимо выполнить те или иные действия) от описания его семантики (собственно смысла каждого из действий). Кроме того, описание логики при автоматном подходе жестко структурировано. Эти свойства делают автоматное описание сложного поведения наглядным и ясным.
JS: Автоматное программирование → Лексический анализ
Перед тем, как окунуться в высокоприкладное автоматное программирование, попробуем немного использовать его в более классической теме, а именно в лексическом анализе.
Лексический анализ - процесс распознавания и выделения лексем из входного потока символов.
Перейдем сразу к примеру. Необходимо во входящем тексте сделать заглавной первую букву каждого слова. Задача тривиально решается путём применения цепочки split/map(capitalize)/join , но герои всегда идут в обход, поэтому мы попробуем решить эту задачу так, как сделал бы это настоящий лексер. Главное условие состоит в том, что данные в лексер попадают посимвольно. В нашей задаче мы будем это имитировать простым перебором строки.
Эту задачу я уже использовал в “Основах программирования”. И вот, как её решает “обычный программист”:
export default (str) => {
let result = '';
for (let i = 0; i < str.length; i++) {
const shouldBeBig = str[i] !== ' ' && (i === 0 || str[i - 1] === ' ');
result += shouldBeBig ? str[i].toUpperCase() : str[i];
}
return result;
};
А вот, как её решил бы “автоматный программист”:
Сначала определяем значимые состояния управления. Для текущей задачи это будут “внутри слова” и “снаружи слова”. Почему именно так? При выделении состояний, первое, на что нужно ориентироваться, это переходы. Именно во время переходов из одного состояния в другое происходят необходимые действия. Перевод буквы в верхний регистр происходит во время перехода между состояниями “вне слова” и “в слове”.
export default (str) => {
let result = '';
let state = 'outside'; // outside, inside
for (let i = 0; i < str.length; i++) {
switch (state) {
case 'inside':
if (str[i] === ' ') {
state = 'outside';
}
result += str[i];
break;
case 'outside':
if (str[i] !== ' ') {
result += str[i].toUpperCase();
state = 'inside';
} else {
result += str[i];
}
break;
}
}
return result;
};
Первое, на что можно обратить внимание, это размер. Действительно, ввод нового понятия приводит к увеличению программы, и в данном случае может показаться, что оно того не стоит. Возможно, для такой задачи это правда, но с ростом количества состояний и переходов (рост обычно не линейный, и программа резко скатывается в “невозможно разобраться”) подход без автоматов сделает программу вообще не поддающейся анализу. Вы не раз еще в этом убедитесь в своей профессиональной карьере.
Следующим пунктом будет наличие большого switch по состояниям. Это отличительная черта алгоритмов, реализованных в автоматном стиле. Такой взгляд на программу помогает разбить её на независимые куски, которые легко анализировать. То есть в целом программа больше, но она четко структурирована и может рассматриваться независимыми частями, внутри которых довольно простая логика. Отлаживать такие программы тоже легче, потому что достаточно следить за небольшим количеством управляющих состояний.
Более того, часто оказывается, что именно так мы себе задачу раскладываем в голове. Другими словами, такой подход также позволяет избегать семантического разрыва.
JS: Автоматное программирование → Паттерн State
В соответствии с классификацией, введенной Д. Харелом, любую программную систему можно отнести к одному из следующих классов.
- Трансформирующие системы осуществляют некоторое преобразование входных данных и после этого завершают свою работу. В таких системах, как правило, входные данные полностью известны и доступны на момент запуска системы, а выходные – только после завершения ее работы. К трансформирующим системам относятся, например, архиваторы и компиляторы.
- Интерактивные системы взаимодействуют с окружающей средой в режиме диалога (например, текстовый редактор). Характерной особенностью таких систем является то, что они могут контролировать скорость взаимодействия с окружающей средой – заставлять среду «ждать».
- Реактивные системы взаимодействуют с окружающей средой путем обмена сообщениями в темпе, задаваемом средой. К этому классу можно отнести большинство телекоммуникационных систем, а также системы контроля и управления физическими устройствами.
Известно, что конечные автоматы в программировании традиционно применяются при создании компиляторов, которые относятся к классу трансформирующих систем. Автомат здесь понимается как некое вычислительное устройство, имеющее входную и выходную ленты. Перед началом работы на входной ленте записана строка, которую автомат далее посимвольно считывает и обрабатывает. В результате обработки автомат последовательно записывает некоторые символы на выходную ленту.
Другая традиционная область использования автоматов – задачи логического управления – является подклассом реактивных систем. Здесь автомат – это, на первый взгляд, совсем другое устройство. У него несколько параллельных входов (чаще всего двоичных), на которые в режиме реального времени поступают сигналы от окружающей среды. Обрабатывая эти сигналы, автомат формирует значения нескольких параллельных выходов.
Таким образом даже традиционные области применения конечных автоматов охватывают принципиально различные классы программных систем.
В качестве примера реактивной системы рассмотрим электронные часы с будильником.

Пусть у них имеются три кнопки. H - кнопка для увеличения часа на единицу, M - для увеличение минуты на единицу и кнопка Mode , которая переключает часы в режим настройки будильника. В этом режиме на экране отображается время срабатывания будильника, а кнопки H и M устанавливают не текущее время, а время срабатывания будильника. Повторное нажатие кнопки Mode возвращает часы в обычный режим. Кроме того, затяжное нажатие на кнопку Mode приводит к тому, что будильник активируется. Такое же нажатие еще раз отключает будильник.
После этого, если текущее время совпадает со временем будильника, включается звонок, который отключается либо нажатием кнопки Mode , либо самопроизвольно через минуту. Кнопки H и M в режиме звонка (когда сработал будильник) не активны.
Поведение часов с будильником уже является сложным, поскольку одни и те же входные воздействия (нажатие одних и тех же кнопок) в зависимости от режима инициируют различные действия.
В программных и программно-аппаратных вычислительных системах сущности со сложным поведением встречаются очень часто. Таким свойством обладают устройства управления, сетевые протоколы, диалоговые окна, персонажи компьютерных игр и многие другие объекты и системы.
Подведем итог. У нас есть следующие действия:
- Установка времени
- Установка времени срабатывания будильника
- Включение/Выключение будильника
- Отключение звонка будильника
Флаго-ориентированное программирование
class AlarmClock {
clickH() {
if (!this.onBell) {
if (this.mode === 'alarm') {
this.alarmHours += 1;
} else {
this.hours += 1;
}
}
}
}
const clock = new AlarmClock();
clock.clickH();
Выше типичный пример флаго-ориентированного программирования. Примерно так выглядит код большинства программ.
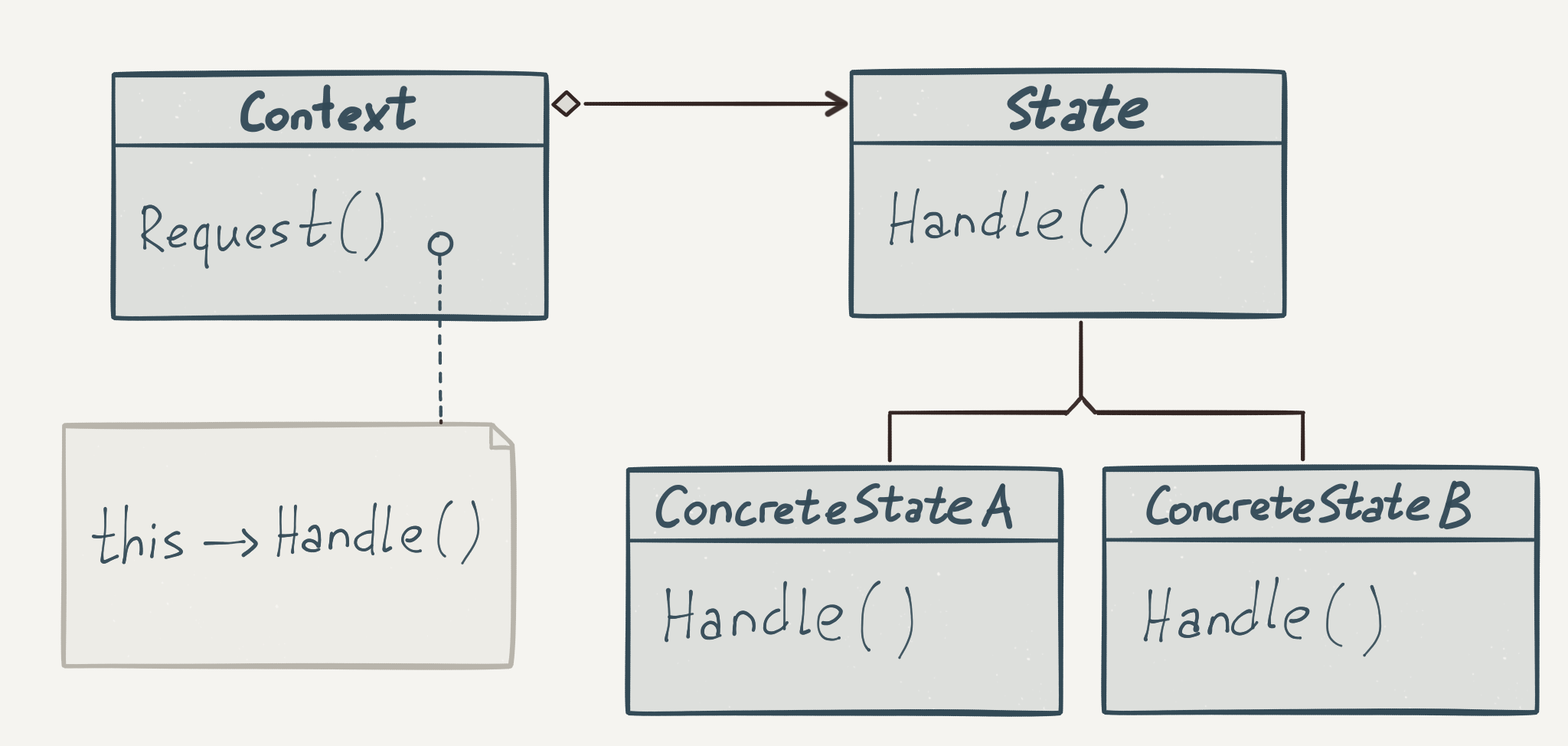
Давайте немного вспомним курс “Программирование, управляемое данными”. В рамках этого курса мы делали диспетчеризацию по интересующему нас параметру (типу), что приводило к устранению условных конструкций и давало возможность расширять поведение программы без её постоянного переписывания. Здесь наблюдается точно такая же ситуация, в которую так и просится полиморфизм включения. Достаточно очевидно, что диспетчеризация нам нужна по состоянию, другими словами, должен выполняться разный код в зависимости от того, в каком состоянии находится наш объект. Из этого предположения может следовать только одно. Нужно каждое состояние превратить в тип данных. Так появляется на свет паттерн State .
Выделим три управляющих состояния для наших часов:
- ClockState
- AlarmState
- BellState
Обратите внимание, что состояние “включен будильник” сюда не входит. Оно не является управляющим. Этот параметр влияет только на то, что произойдет переход в BellState в тот момент, когда время на часах и время на будильнике будет одинаковым.
Теперь давайте посмотрим на реализацию с использованием динамической диспетчеризации:
class AlarmClock {
constructor() {
this.hours = 12;
this.alarmHours = 6;
this.setState(ClockState);
}
setState(Klass) {
this.state = new Klass(this);
}
clickH() {
// Делегирование
this.state.clickH();
}
}
Код, который здесь написан, это всего лишь один из вариантов реализации паттерна State . Не принимайте как догму все, что вы читаете в книгах “10 лучших паттернов”. Главное, это концептуальная идея и решаемая задача, остальное очень сильно варьируется от большого числа параметров. В основном в книгах все примеры даны для статических языков, и эти реализации очень громоздки для такого языка как javascript .
От чего точно не уйти, так это от того, что в начале наши часы инициализируются неким начальным состоянием. В нашем случае оно statefull (мы передаем туда текущий объект), но так же оно могло бы быть и stateless . А дальше все интерфейсные методы часов, поведение которых зависит от состояния, делегируют все вызовы внутрь объекта состояния. Внутри, без условных конструкций, находится код, который выполняет только то, что нужно делать в текущем состоянии. При необходимости этот код меняет сам объект часов. Это возможно благодаря тому, что мы передали внутрь состояния this .
Если какое-то событие приводит к изменению состояния, то само состояние (в паттерне State ) отвечает за то, чтобы поменять себя на другое состояние. Например, при очередном тике часов, если настало время работы будильника, то мы подставляем вместо себя состояние BellState .
export default class ClockState {
tick() {
if (this.clock.isAlarmTime()) {
this.clock.setState(BellState);
}
}
}
Общая схема работы паттерна State .
Пример из жизни
Дополнение
Материал этого урока во многом основан и использует материал из книги: “Автоматное программирование” (Надежда Поликарпова, Анатолий Шалыто).
JS: Автоматное программирование → Паттерн State Machine
Паттерн State настоящее спасение во многих ситуациях, но и он не совершенен. Главная проблема этого подхода в том, что логика переходов разбросана по всему коду, и сами состояния знают о том, когда и в какое состояние нужно перевести автомат. При достаточно большом автомате это становится проблемой.
Решением является выделение таблицы переходов. Делать это можно как и в рамках паттерна State , плавно доводя его до паттерна State Machine , либо с использованием специальных библиотек, которые водятся в изобилии для каждого языка программирования.
const fsm = {
initial: 'draft',
transitions: [
{ name: 'sendToModerate', from: ['draft', 'declined'], to: 'moderating' },
{ name: 'accept', from: 'moderating', to: 'published' },
{ name: 'decline', from: ['moderating', 'published'], to: 'declined' },
],
};
Я, надеюсь, что такая форма (декларативная) говорит сама за себя. Описанный здесь процесс похож на то, как работает публикация статей на Хабре.
Переходы в fsm осуществляются только посредством порождения событий. Это настолько важно, что я вынужден повторить. При использовании конечных автоматов состояния не могут меняться напрямую, такой подход уничтожает весь смысл использования автоматов. Именно переходы между состояниями являются значимыми в таких системах и программируются разработчиком.
javascript-state-machine
Рассмотрим самую популярную на гитхабе библиотеку для работы с автоматами в js .
import StateMachine from 'javascript-state-machine';
const fsm = new StateMachine({
initial: 'green',
transitions: [
{ name: 'warn', from: 'green', to: 'yellow' },
{ name: 'panic', from: 'yellow', to: 'red' },
{ name: 'calm', from: 'red', to: 'yellow' },
{ name: 'clear', from: 'yellow', to: 'green' },
]});
fsm.current; // green
fsm.warn();
fsm.is('yellow'); // true
fsm.can('calm'); // false
fsm.calm(); // throw error
- Таблица отражает логику процесса. В своей повседневной практике, первое, на что я смотрю в коде, это автоматы, реализованные в сущностях. По ним можно понять, какие основные процессы происходят в программе и как они концептуально работают.
- Подобные библиотеки, обычно, автоматически генерируют код для работы автомата и самостоятельно проверяют его корректность, не позволяя случаться неправильным переходам. Это огромный плюс перед ручным кодированием.
- Также эти библиотеки предоставляют возможность реагировать на события и переходы.
Коллбеки
const fsm = new StateMachine({
initial: 'green',
transitions: [/* ... */],
methods: {
onGreen: ({ transition, from, to }) => { /*...*/ },
onBeforeWarn: (lifecycle) => { /*...*/ },
onLeaveRed: ({ transition, from, to }) => { /*...*/ },
}
});
fsm.calm('message');
Обратите внимание на то, что автомат не всегда подразумевает разное поведение всех подсистем в зависимости от того, в каком он состоянии. Часто, в реальном коде, важен сам факт того, что сущность находится в каком-то состоянии и может переходить в другое. Даже в этом случае имеет смысл явно выделять автомат и пользоваться всей прелестью автоматической генерации и верификации. Набрав определенный опыт, вы будете использовать автоматы повсеместно, даже в случаях когда состояний всего два и, казалось бы, можно просто использовать флаг. На самом деле даже с флагом у вас появится логика, которую мог бы обеспечить автомат. К слову, в Хекслете используется около 80 явных автоматов (на момент написания урока).