Теперь, когда мы уже умеем немного программировать, пришла пора погружаться в специфику работы браузера и фронтенд разработки.
Что вообще такое фронтенд разработка?
Современные сайты обладают высокой степенью интерактивности. Страницы перезагружаются все реже, а манипуляции с содержимым происходят прямо на месте. Программные решения стали настолько сложными (комплексными), что уже сейчас в браузере реализуются полноценные среды разработки (например, hexlet ide), программы, подобные Photoshop или пакеты, аналогичные Microsoft Office.
Да чего уж говорить, существует большая индустрия игр, созданных для браузеров. Причем, благодаря аппаратной поддержке, эти игры не уступают тому, что делается и для обычного десктопа.
Язык, который изначально использовался как способ добавить снежинки на сайт, стал мощнейшим инструментов в руках профессионалов.
На текущий день javascript — единственный язык, исполняемый браузерами.
Кстати, большое количество языков либо созданы поверх js либо позволяют
транслировать свой код в js. К таким языкам относятся: clojurescript,
typescript, kotlin, java, elm.
Но одного языка недостаточно для того, чтобы оживить страницу. Главная ценность состоит в том, что браузеры добавляют в js возможности, которые позволяют манипулировать содержимым страницы, а так же управлять самим браузером. Большинство этих возможностей стандартизировано и описано в спецификациях HTML5. Вот некоторые из них:
Манипуляция содержимым
Управление внешним видом
Реакция на действия пользователя
Работа с куками
Управление браузером
Взаимодействие с сервером
Проигрывание видео
База данных в браузере
Многозадачность Web Workers
IO
2D/3D рисование
С точки зрения языка, большинство этих возможностей выглядят как некие глобальные объекты, с которыми можно взаимодействовать в программе. Самым базовым и ключевым объектом этой системы является представление DOM дерева. Так как DOM - глобальный объект, то при работе с ним почти никогда не используются наши любимые функции высшего порядка такие как map. Дело в том что изменение DOM всегда происходит напрямую, а значит обработка коллекций не порождает новых коллекций. Практически все массовые операции делаются используя функцию forEach.
В этом курсе мы научимся внедрять js на сайт, пройдем по основным способам манипулирования страницей, познакомимся с полифиллами, сделаем свой первый ajax запрос и откроем для себя мир событий.
После этого курса вы сможете попробовать свои силы в создании простых фронтенд игр (в практике после курсов).
JS: DOM API → JavaScript в браузере
https://learn.javascript.ru/external-script
Основной способ добавить js код на страницу — это использование тега script .
Инлайн скрипты
Подобных тегов может быть любое количество в любых местах внутри body или head . Правда, от места расположения зависят возможности, но этот вопрос мы рассмотрим позже.
<html>
<body>
<script>
const greeting = 'hello, world!';
alert(greeting);
</script>
</body>
</html>
Самый простой способ начать взаимодействовать с браузером — это вызвать функцию alert . Хотя в реальном коде она почти не используется, но ее очень любят создатели курсов, в которых обучение программированию ведется через браузер. Нажмите
чтобы увидеть результат выполнения этой функции.
Кроме alert для взаимодействия с пользователем можно использовать функции
и
.
Все эти функции присутствуют только в браузерах и недоступны в серверных версиях js . Это первый пример, когда мы видим как браузер “расширяет” js, добавляя туда новые возможности. Но не возможности самого языка, язык-то как раз остается тем же, а возможности по взаимодействию со средой.
Внешние скрипты
Инлайн скриптинг, как правило, используется для небольших кусков кода, или для вызова кода, загруженного из внешних скриптов. Загружаются внешние скрипты следующим образом:
<body>
<html>
<head>
<script src="/assets/application.js"></script>
</head>
<body>
</body>
</html>
Довольно часто можно увидеть подобный вариант загрузки:
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.2.1/core.js"></script>
В примере выше, файл грузится с CDN, что может давать определенные преимущества в скорости загрузки.
Скорость
В зависимости от того, в каком месте документа появляются теги script , вы можете наблюдать серьезные изменения как в скорости отрисовки сайта, так и в скорости загрузки.
Server (Nodejs) vs Client (Browser)
В браузере отсутствует множество тех вещей, с которыми мы привыкли иметь дело работая в серверном окружении. Среди них:
Стандартная библиотека
Про библиотеку можно забыть. Из коробки никаких assert , events , net , http , url и всего остального. Для любой простейшей задачи придется подключать библиотеку из npm .
Модули
До недавнего времени, модульной системы в браузерах не существовало. Сейчас она появляется, но пока только в экспериментальном варианте.
На текущий момент, любой загруженный код, работает в глобальной области видимости. Такое поведение привело к большому количеству обходных маневров используемых повсеместно для ручной изоляции кусков js друг от друга.
<html>
<body>
<script>
const greeting = 'hello, world!';
</script>
<script>
alert(greeting);
</script>
</body>
</html>
Самый распространенный способ изоляции называется Immediately-Invoked Function Expression. Его принцип действия крайне прост: весь код, который должен быть выполнен в браузере, заворачивается в анонимную функцию, которая сразу же вызывается:
(function() {
// some code…
})();
Как вы позже увидите, современные системы сборки избавляют нас от необходимости делать такие манипуляции руками. Мы можем продолжать использовать привычный и полноценный javascript.
Версии и движки
Еще один существенный недостаток js в браузере в том, что реализация js в разных браузерах отличается и иногда весьма существенно. Более того, даже разные версии одного и того же браузера могут отличаться катастрофически. Причем, эту проблему решить невозможно, она является следствием самой природы фронтенда. У каждого пользователя будет стоять тот браузер, который ему нравится, той версии, до которой он не забыл обновиться.
Сборка
К счастью, современный мир фронтенда смог выкрутиться из этой ситуации. Мы по прежнему можем пользоваться всеми (почти) современными фишками js , включая систему модулей. Возможно это благодаря babel с одной стороны и сборщиками, подобными webpack , с другой. Ну и нельзя не упомянуть про полифиллы, которым будет посвящен отдельный урок.
Принцип работы этой связки заключается в том, что сборщик по определенным правилам собирает все наши ресурсы (css, fonts, images) и файлы с кодом, пропускает их через обработчики, например, babel и на выходе мы получаем файлы, готовые к использованию в браузере.
Безопасность
Во всех браузерах поддерживается механизм под названием cookies , который мы изучали в курсе по протоколу http . Этот механизм играет центральную роль в реализации такой вещи, как аутентификация. После того, как сайт вас опознал, он выставляет специальную сессионную куку и на основе нее определяет залогинены вы на сайте или нет.
Как вы, возможно, помните, js позволяет обращаться к вашим кукам. Это автоматически означает, что если злоумышленнику удастся разместить произвольный код на странице сайта, то он сможет прочитать вашу сессионную куку и передать ее в нужное место. Так легко и беззаботно уводятся сессии и пользователи внезапно оказываются без своего аккаунта. Ни антивирус, ни фаервол в такой ситуации ничем помочь не смогут.
Внедрение произвольного кода на сайт называется XSS (Cross-Site Scripting) и является популярным способом атаки, кроме него так же распространен CSRF (Cross-Site Request Forgery).
Выполнение js в браузере
Раз браузеры способны исполнять js , значит должен быть способ это сделать и без взаимодействия с сайтами. Такой способ действительно существует. Современные браузеры неплохо оснащены функциями не только для конечных пользователей, но и для разработчиков. В каждом браузере можно найти (покопавшись в настройках) панель, называемую DevTools . Эта возможность настолько важна в жизни каждого веб-разработчика, что в нашем курсе ей посвящен целый урок.
JS: DOM API → Глобальный объект Window
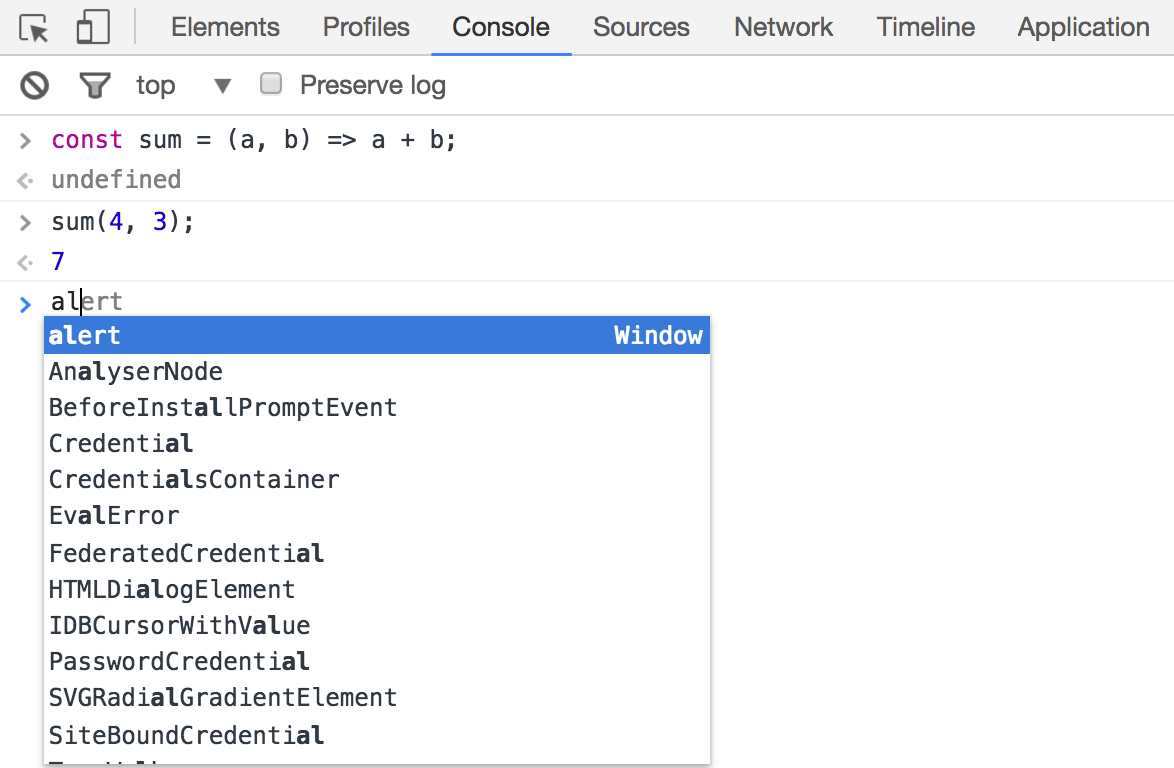
Если в консоли браузера выполнить команду console.log(this) , то на экран будет выведен некий Window .

Window — это глобальный объект, то есть доступный из любого места всегда. Он не является частью js и предоставляется браузерами. Как правило, к нему обращаются по имени window , так как this из-за позднего связывания указывает на него не всегда.
Обратите внимание на то, что функция alert находится в объекте window , это видно на скрине выше. Другими словами, когда мы вызываем функцию alert , то в действительности происходит вызов window.alert . Более того, все глобальные объекты js тоже принадлежат window .
window.console.log('hey');
window.Math.abs(5);
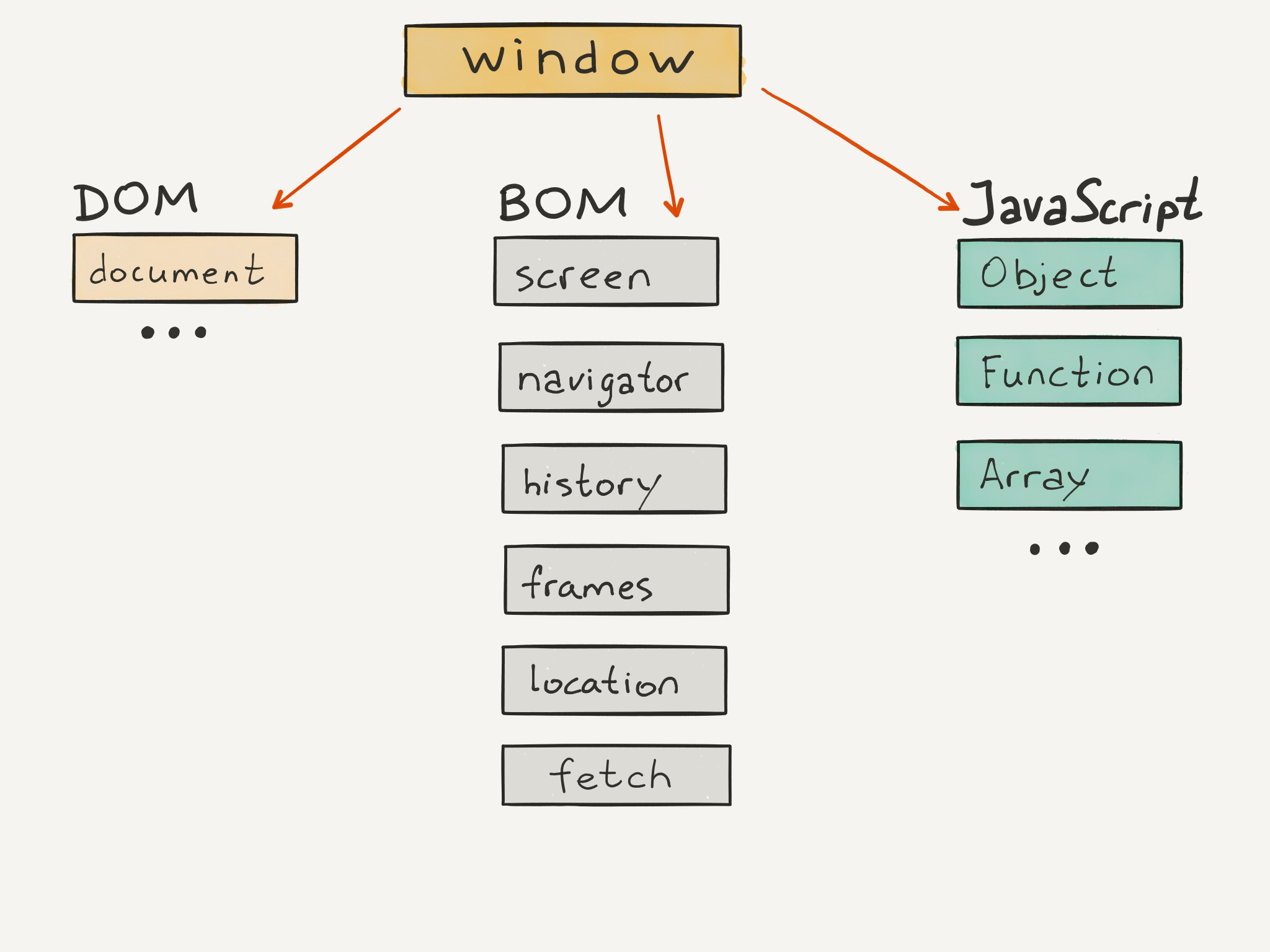
Объектная модель браузера
Это набор глобальных объектов, управляющих поведением браузера. Все они так же находятся внутри window . Разберем некоторые из них.
Navigator
Предоставляет информацию о браузере, такую как версию, название, используемую локаль, доступные права, подключенные плагины.
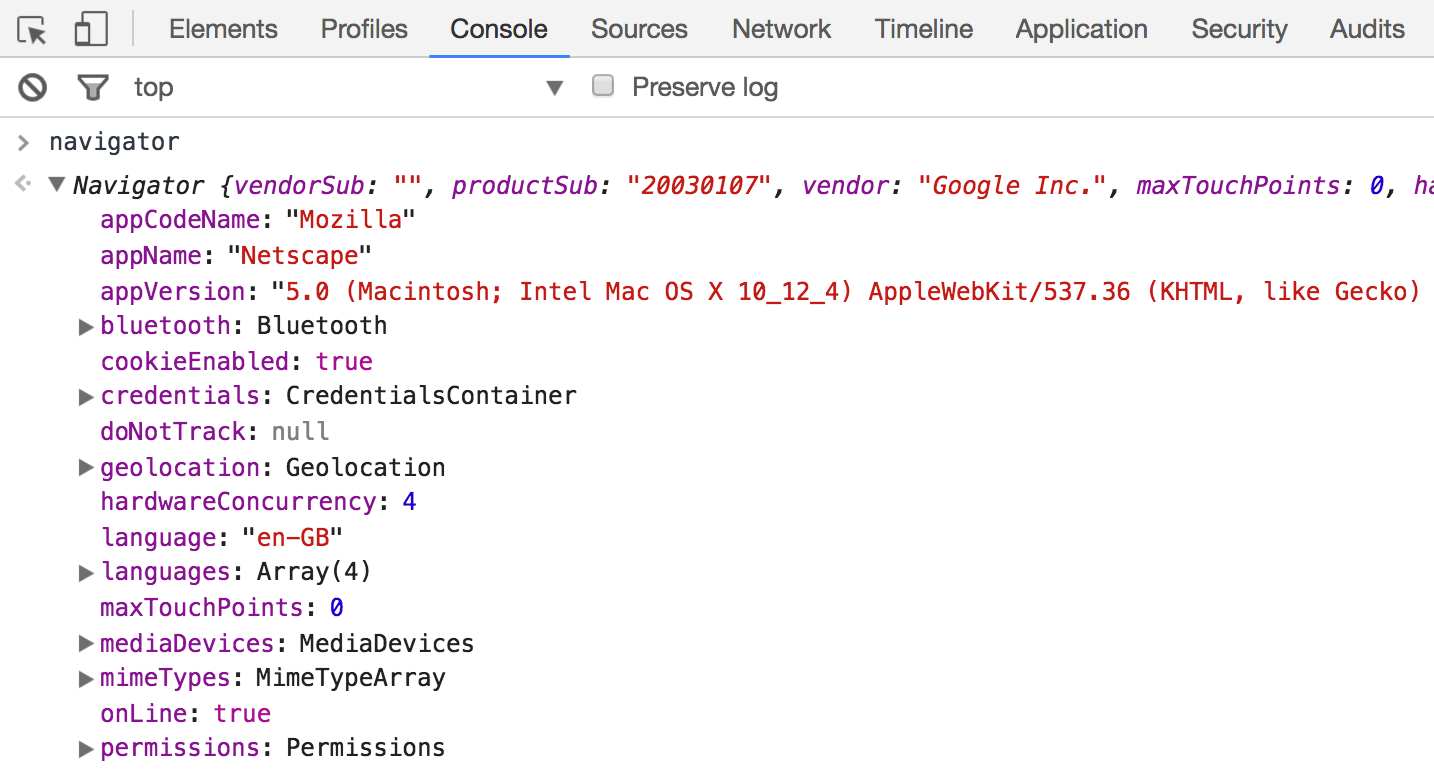
Location
Позволяет управлять адресной строкой. Например, вот так можно инициировать загрузку другой страницы:
location.href = "https://hexlet.io";
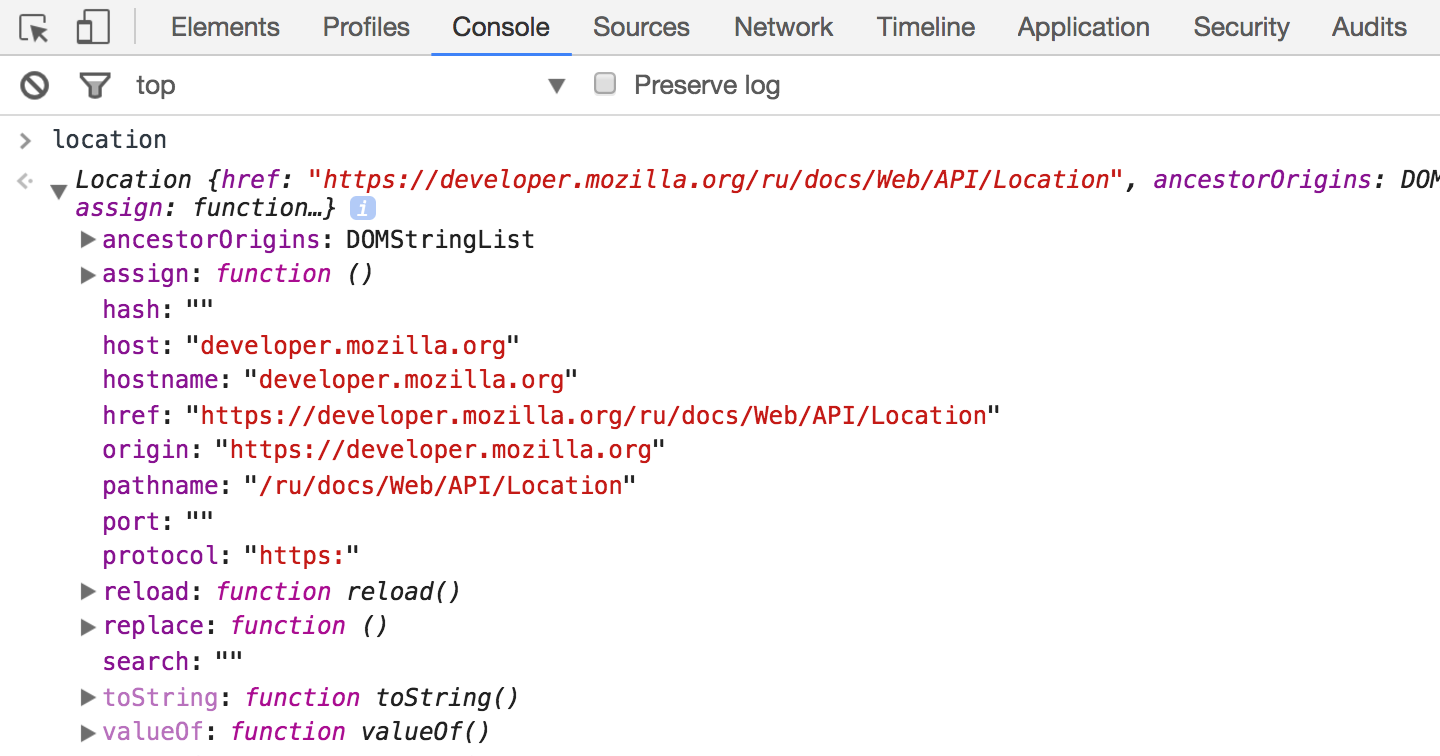
History
С помощью этого объекта можно перемещаться по истории переходов, а так же формировать ее в тех ситуациях, когда не происходит реального переход по страницам. Это особенно актуально для SPA .
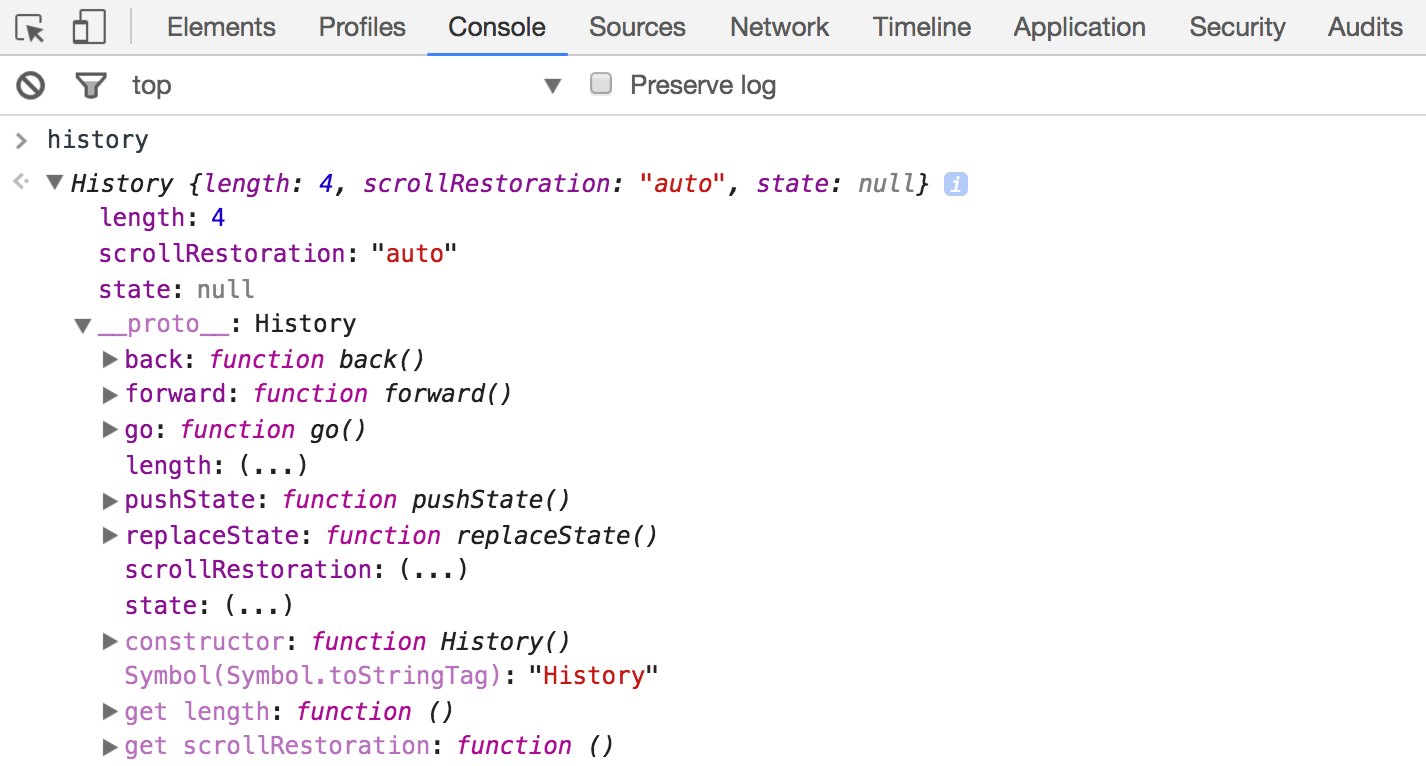
Fetch
Современный метод для выполнения AJAX запросов. Именно с помощью fetch происходит общение с сервером и другими сайтами.
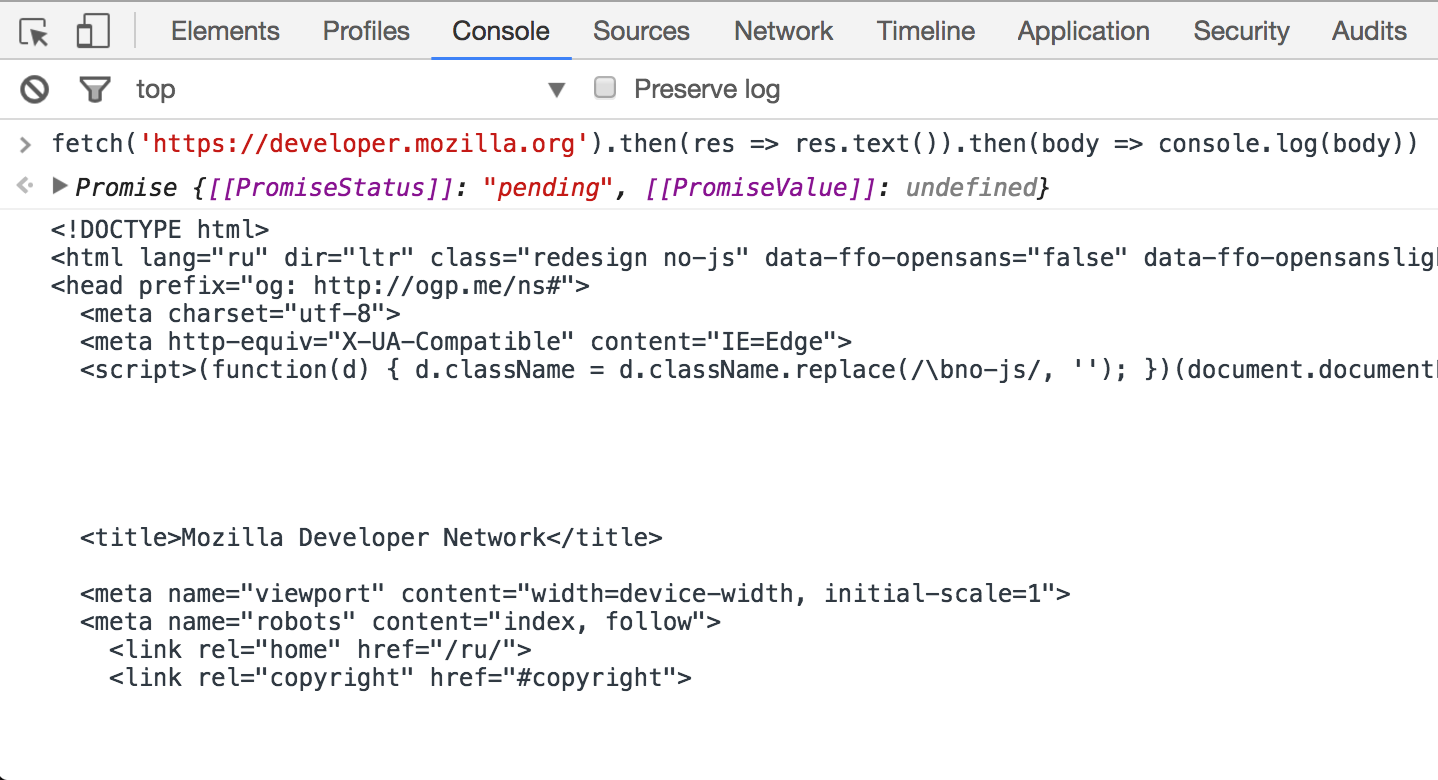
JS: DOM API → Что такое DOM?
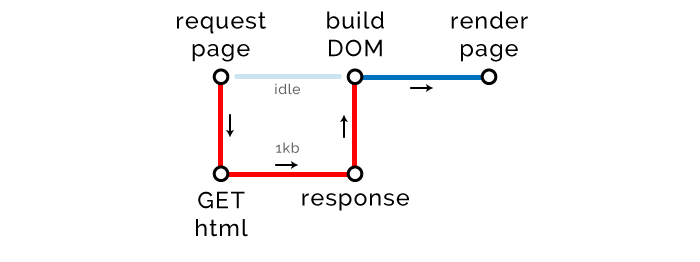
Каким образом формируется страница, показанная на скриншоте ниже?
С высоты птичьего полета процесс отображения страницы можно представить следующим образом:
- Браузер выполняет запрос на сервер (предварительно выяснив этот адрес с помощью DNS)
GET /courses HTTP/1.1
HOST: ru.hexlet.io
- Пришедший в ответ
htmlпарсится, и на его основе строится DOM дерево - Браузер рисует страницу, используя DOM дерево (упрощенно).
Чтобы понять, что такое DOM и, в частности, DOM дерево, рассмотрим следующий пример.
const json = '{ "key": "value" }';
const obj = JSON.parse(json);
console.log(obj.key); // value
Как мы помним, json — это текстовый формат, используемый для взаимодействия между разными программами, которые, возможно, написаны на совершенно разных языках. Одна программа сериализует данные в json , а другая десереализует их во внутренние структуры своего языка.
Думаю, достаточно очевидно, что программа, получившая какие-то данные в виде json , не сможет работать с ним, если он останется в текстовом представлении, ведь по сути это строчка текста.
Теперь, попробуем понять смысл DOM дерева:
// Гипотетический пример, так как модуля HTML не существует в природе
const html = `
<body>
<p>hello, <b>world</b>!</p>
</body>
`;
const document = HTML.parse(html);
console.log(document.firstChild.name); // html
Грубо говоря, html можно сравнить с json . Другими словами, html — это текстовое представление DOM дерева, не зависящее от языка программирования. То, что оно является деревом, видно невооруженным взглядом, так как теги вкладываются в теги.
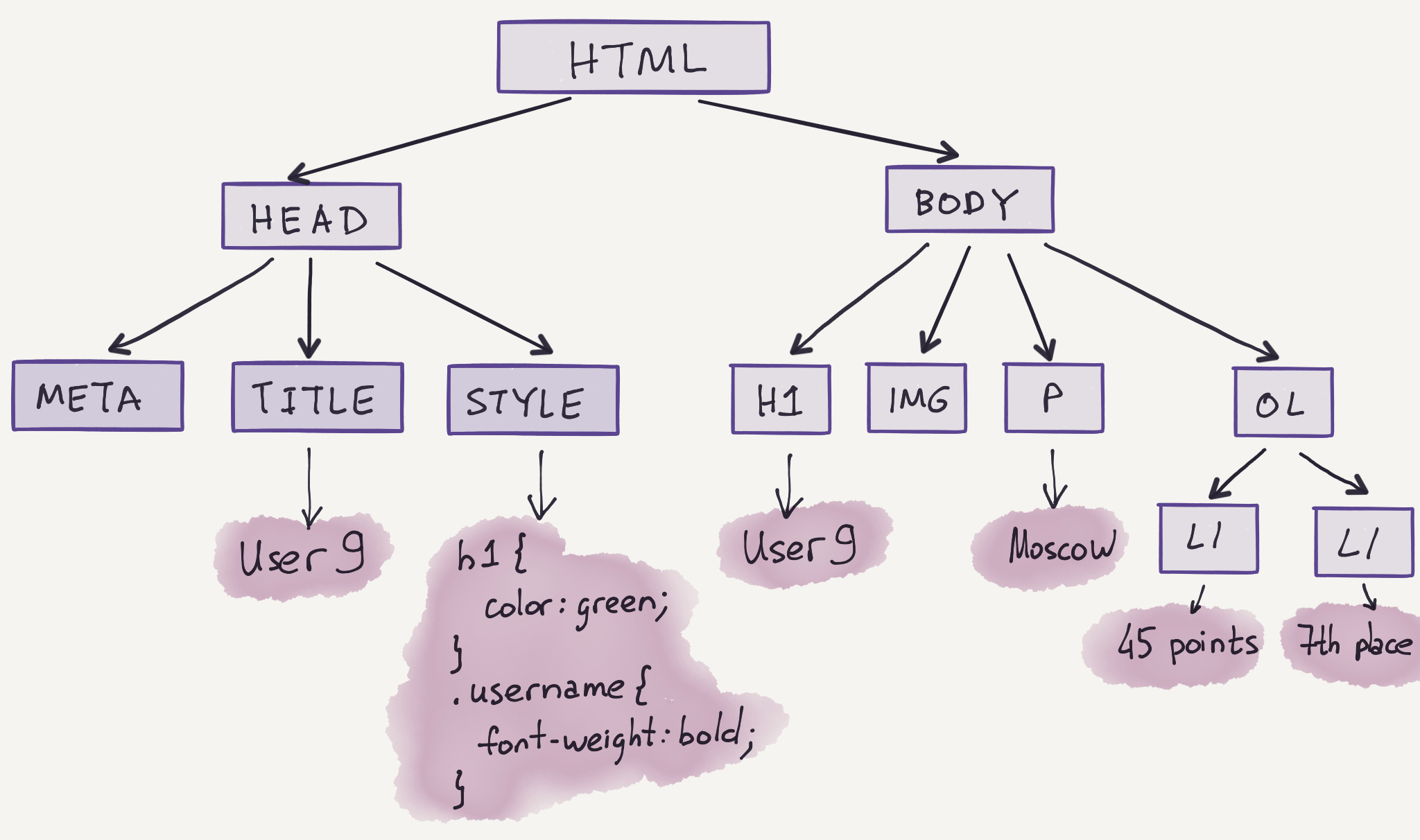
Каждый html-тег становится узлом этого дерева, а теги, вложенные в него, становятся дочерними узлами. Для представления текста создаются специальные текстовые узлы.
Важно то, что в DOM дерево попадают все элементы, представленные в html, включая пробелы и переводы строк.
С DOM tree разобрались, теперь попробуем разобраться с тем, что же, собственно, такое DOM.
Объектная модель документа (Document Object Model) - это не зависящий от платформы и языка программный интерфейс, позволяющий программам и скриптам получить доступ к содержимому HTML-, XHTML- и XML-документов, а также изменять содержимое, структуру и оформление таких документов.
На практике, во фронтенд разработке это сводится к тому, что браузер предоставляет специальный объект document , который содержит внутри себя DOM tree и который наполнен большим количеством методов (согласно спецификации DOM) для манипулирования этим деревом. Любые изменения, которые производятся с ним, сразу же отображаются браузером на странице.
Подавляющее число возможностей, связанных с DOM, описаны в спецификациях раз и два и, по идее, должны работать одинаково во всех браузерах. К сожалению, это не так. DOM развивается, но браузеры двигаются медленнее. Кроме того, существует множество исторических решений, которые приводят к проблемам.
В более поздних уроках мы поговорим о том, как современные разработчики справляются с этими проблемами, используя полифиллы.
Восстановление
Те, кто сталкивались с html в реальной жизни, прекрасно знают, что если подать на вход браузеру невалидный html с незакрытыми тегами, нарушенной вложенностью и другими проблемами, то мы не получим сообщений об ошибках. Браузер переварит этот html и что-то отобразит на экране. Возможно, вам не понравится то, что вы увидите, но, по крайней мере, оно будет работать.
Браузер действительно восстанавливает структуру и делает это по очень хитрым правилам. И это логично, иначе было бы невозможно произвести парсинг в принципе. Но есть и другая причина: даже если сам html будет валидным, браузер при создании DOM tree добавляет в него узлы (представленные тегами в html), которые вы, возможно, пропустили, но стандарт требует их наличия. Например, в таблицы добавляется tbody .
Именно DOM открывает практически безграничные возможности по изменению страниц. Все библиотеки (jquery и другие) и фреймворки (angular, react) внутри себя манипулируют DOM. Это та база, вокруг которой построено всё во фронтенд разработке.
Как вы увидите позже, манипулировать DOM напрямую доставляет серьезные неудобства. Этого вопроса мы коснемся подробнее в следующих курсах, посвященных фронтенд фреймворкам.
JS: DOM API → DOM Дерево
Знакомство с DOM деревом проще всего начать с изучения структуры этого дерева.

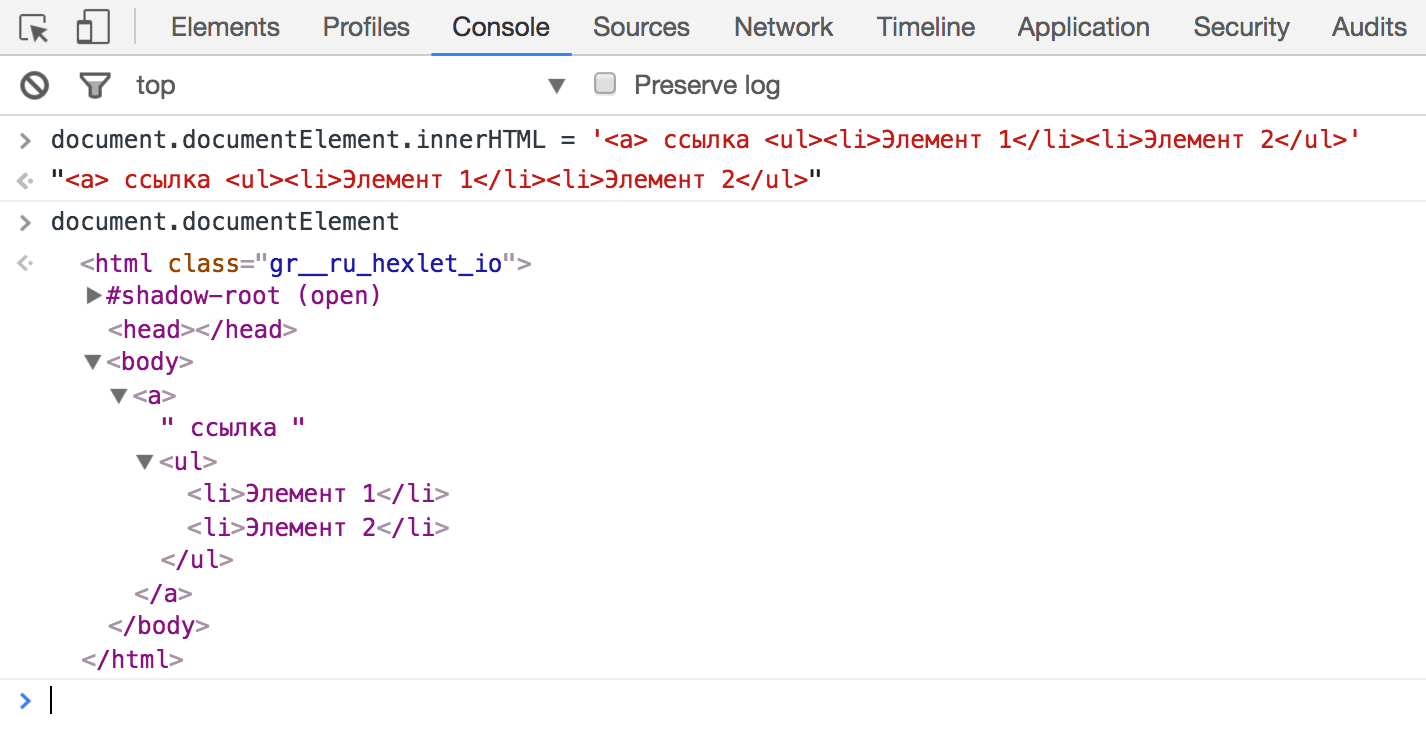
Корневым элементом в DOM дереве считается элемент html . Доступ к нему можно получить так: document.documentElement .
Навигация по дереву достаточно интуитивная, поэтому можно смело экспериментировать в браузере:
const html = document.documentElement;
// Read-only
html.childNodes; // [head, text, body]
html.firstChild; // <head>...</head>
html.lastChild; // <body>...</body>
html.childNodes[1]; // #text
Из-за того, что body и head всегда присутствуют внутри документа, их вынесли на уровень объекта document для более простого доступа:
document.head;
document.body;
Кроме того, что можно идти вглубь дерева, так же можно идти и наружу:
document.documentElement === document.body.parentNode;
document.body === document.body.childNodes[2].parentNode;
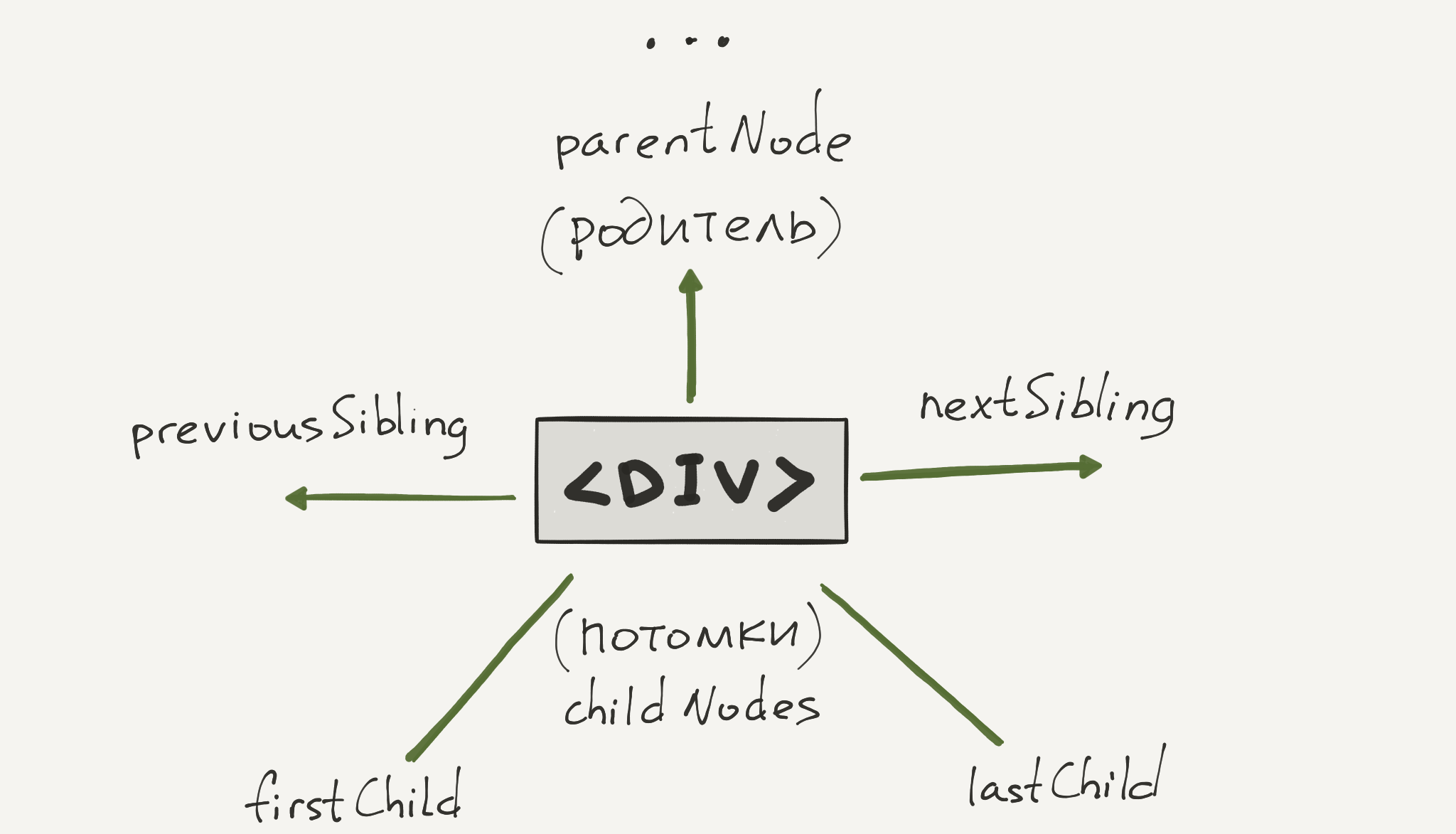
childNodes
В работе с childNodes есть несколько интересных моментов.
- Это свойство доступно только для чтения. Попытка что то записать в конкретный элемент не приведет к успеху:
document.body.childNodes[0] = 'hey';
Изменение DOM дерева осуществляется специальным набором методов, которые будут рассмотрены в соответствующем уроке.
- Хотя
childNodesи является коллекцией, это все же не массив. В нем отсутствует привычные методы, такие какmap,filterи другие. Для перебора элементов можно воспользоваться итератором или сделать так:
const elements = document.documentElement.childNodes;
elements.toString()
"[object NodeList]"
[...elements]; // теперь это массив
// либо так
elements.forEach(el => console.log(el));
Иерархия
Хотя каждый узел дерева и представлен типом Node, но в реальности это базовый тип. А каждый конкретный элемент имеет свой. Другими словами, у нас есть определенная иерархия типов:
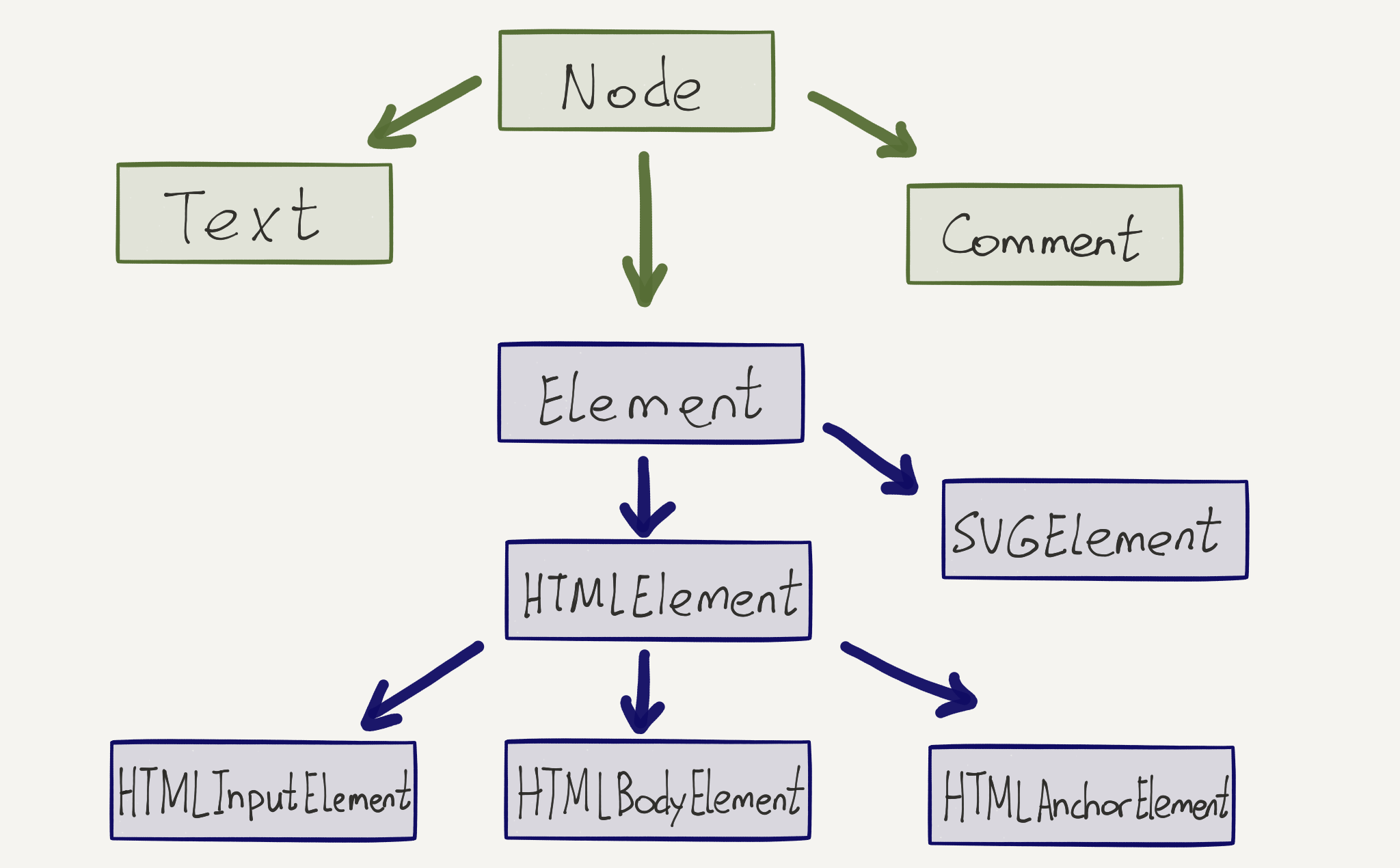
Ноды с типами Text и Comment являются листовыми, то есть они не могут иметь детей. А вот элементы — это то, с чем приходится иметь дело чаще всего. Как видите, в DOM HTMLElement — это отдельное направление, потому что DOM также может представлять и xml документы.
На практике чаще всего нас интересуют не ноды, а элементы. Именно ими мы манипулируем, перемещаемся сквозь них. Это настолько важно, что в DOM есть альтернативный способ обхода дерева, который построен только на элементах:

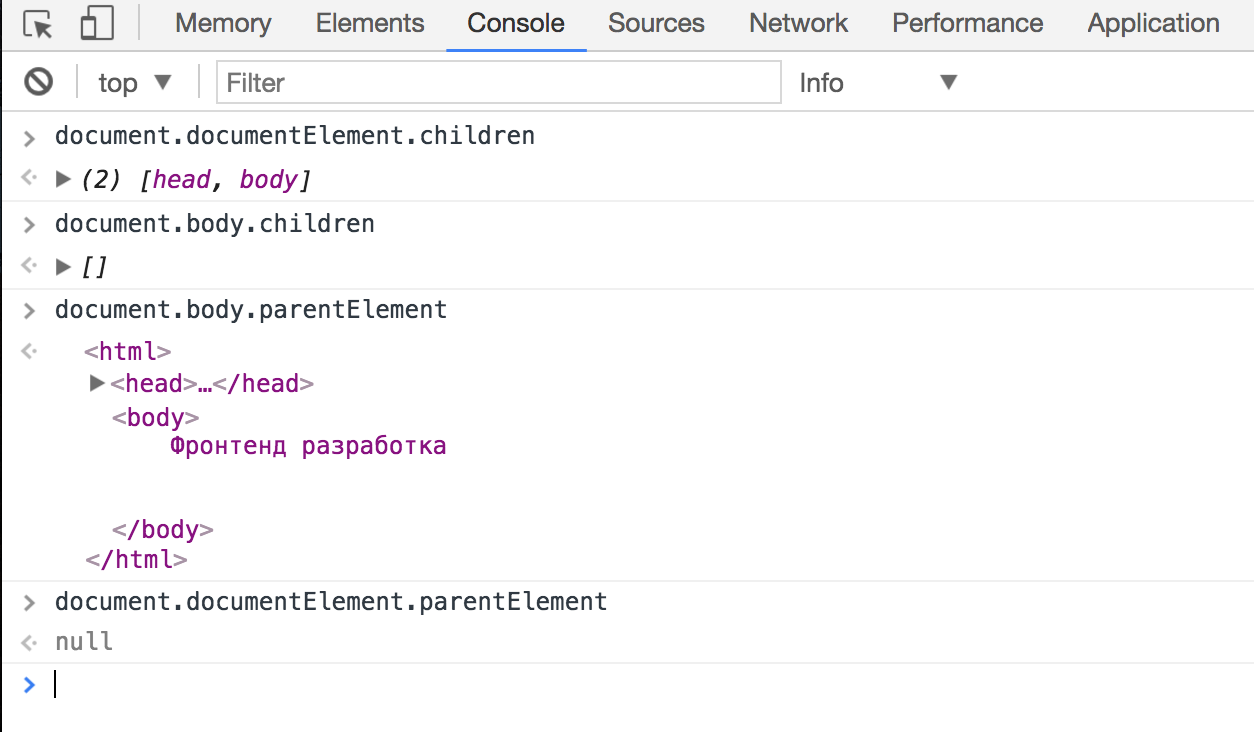
Специальная навигация
Некоторые элементы обладают специальными свойствами для навигации по ним, к таким элементам относятся, например, формы и таблицы.
<table>
<tr>
<td>1.1</td>
<td>1.2</td>
<td>1.3</td>
</tr>
<tr>
<td>2.1</td>
<td>2.2</td>
<td>2.3</td>
</tr>
</table>
const table = document.body.firstElementChild
table.rows[0].cells[2];
Этот способ навигации не заменяет основные. Он сделан исключительно для удобства в тех местах где это имеет смысл.
JS: DOM API → Поиск по дереву
Как правило, в реальных фронтенд-задачах нужно манипулировать наборами элементов (или одним), находящимися где-то глубоко в ДОМе. Причем, зачастую, эти элементы разбросаны по его разным частям. Например, мы можем отметить список файлов на удаление и выполнить это действие. С точки зрения изменения DOM Tree эта задача сводится к выборке всех элементов, которые представляют файлы (с точки зрения визуализации), и их последующему удалению.
Специализированные поисковые методы
В такой ситуации ручной проход по дереву окажется крайне утомительным занятием. DOM предлагает сразу несколько способов решения этой задачи. Самый простой вариант поиска — это поиск по идентификатору:
<p id="content">Это параграф</p>
const el = document.getElementById('content');
Так как id в соответствии со спецификацией обязан быть уникальным на странице, то и метод getElementByid всегда возвращает один элемент. С другой стороны, по случайности, в html может оказаться несколько тегов с одним id . В такой ситуации браузер может вернуть всё что угодно.
Если нужна обработка сразу нескольких элементов, то тут лучше подойдет поиск по классу:
// Будет возвращена коллекция!
const collection = document.getElementsByClassName('row');
// поиск среди потомков el
el.getElementsByClassName('row');
Как видите, этот метод позволяет искать не только в целом документе, но и среди потомков любого элемента.
При необходимости можно искать по тегу:
document.getElementsByTagName('span');
// поиск всех элементов
document.getElementsByTagName('*');
// поиск среди потомков el
el.getElementsByTagName('span');
Поиск по селектору
Наиболее универсальным способом поиска является поиск по селектору. Напомню, что селектор — это правило, позволяющее описать набор элементов в DOM Tree.
<ul id="menu">
<li class="even"><span>Первый</span> пункт</li>
<li>Второй</li>
<li class="even"><span>Третий</span> пункт</li>
</ul>
// Возвращает первый элемент
const ul = document.querySelector('#menu');
const spans = ul.querySelectorAll('.even > span');
Оба метода querySelector и querySelectorAll могут применяться как ко всему документу, так и к конкретному элементу. Поиск, как обычно, будет вестись среди всех потомков.
Полезные методы
matches
Предикат el.matches(css) проверяет, удовлетворяет ли el селектору css .
closest
Метод el.closest(css) ищет ближайший элемент выше по иерархии удовлетворяющий селектору. Сам элемент тоже анализируется. Если такой элемент найден, то он возвращается.
XPath
Язык запросов, изначально разработанный для навигации по DOM в XML. Поддерживается браузерами.
<html>
<body>
<div>Первый слой
<span>блок текста в первом слое</span>
</div>
<div>Второй слой</div>
<div>Третий слой
<span class="text">первый блок в третьем слое</span>
<span class="text">второй блок в третьем слое</span>
<span>третий блок в третьем слое</span>
</div>
<span>четвёртый слой</span>
<img />
</body>
</html>
XPath-путь /html/body/*/span/@class (полный синтаксис имеет вид /child::html/child::body/child::*/child::span/attribute::class ) будет соответствовать в нём двум элементам исходного документа — <span class="text">первый блок в третьем слое</span> и <span class="text">второй блок в третьем слое</span> .
В повседневной практике он практически не встречается при работе с DOM, поэтому здесь я его описал только для общего понимания.
JS: DOM API → Консоль разработчика
Скриншоты из DevTools я показываю с самых первых курсов и надеюсь, что вы им уже пользуетесь. Если нет, то самое время начать, ведь это главный помощник фронтенд-разработчика.
Современные браузеры поголовно оснащены этим полезным инструментом, его нужно только найти в меню и активировать. А дальше стоит потратить время и изучить возможности DevTools. Сейчас они настолько широки, что не хватит и одного дня. В интернете полным полно статей (в том числе на русском), которые рассказывают про самые интересные способы использования и скрытые возможности.
Анализ ошибок
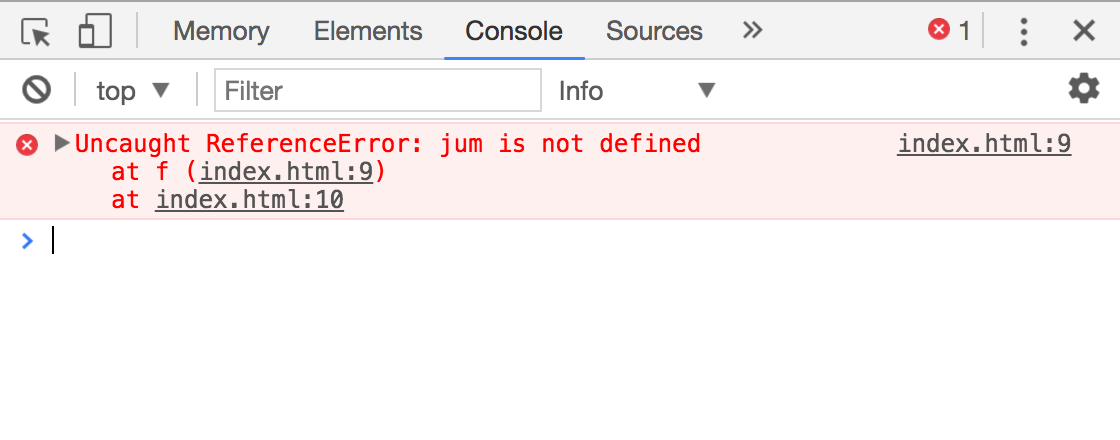
Все ошибки, которые происходят в браузерном js, выводятся в консоль. Их можно не только посмотреть, но так же и открыть исходник, чтобы изучить место возникновения ошибки. Кликать можно по всему что подчеркнуто на скриншоте.
Выбранный элемент
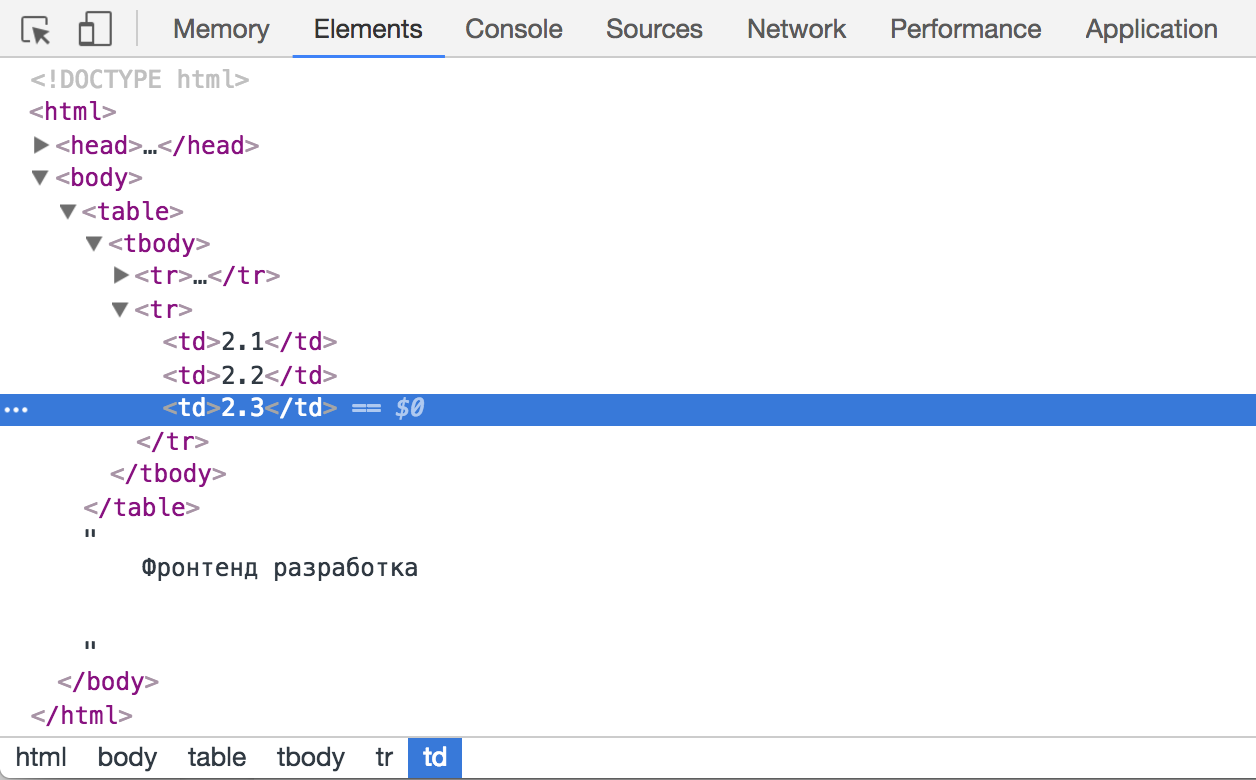
Выбрав таким образом элемент, можно переключиться на вкладку console и набрать $0 . Так вы получите доступ к этому элементу.
Поиск
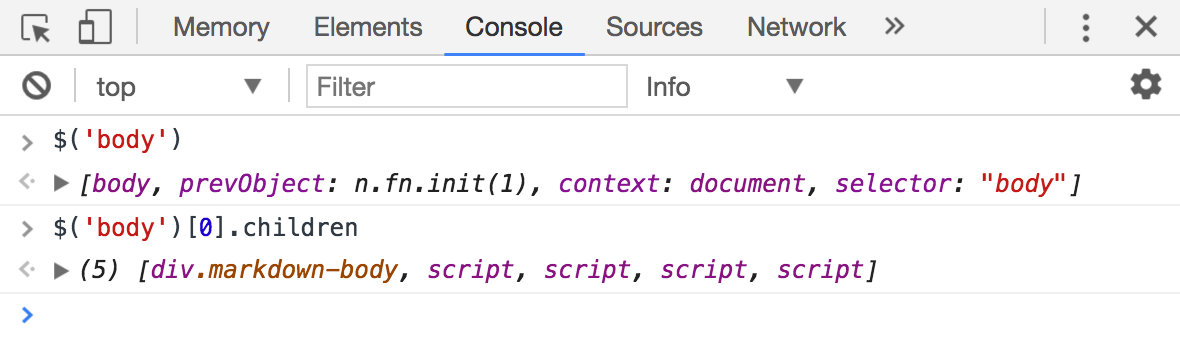
Используя функцию $ можно упростить поиск элементов по селектору.
console.dir
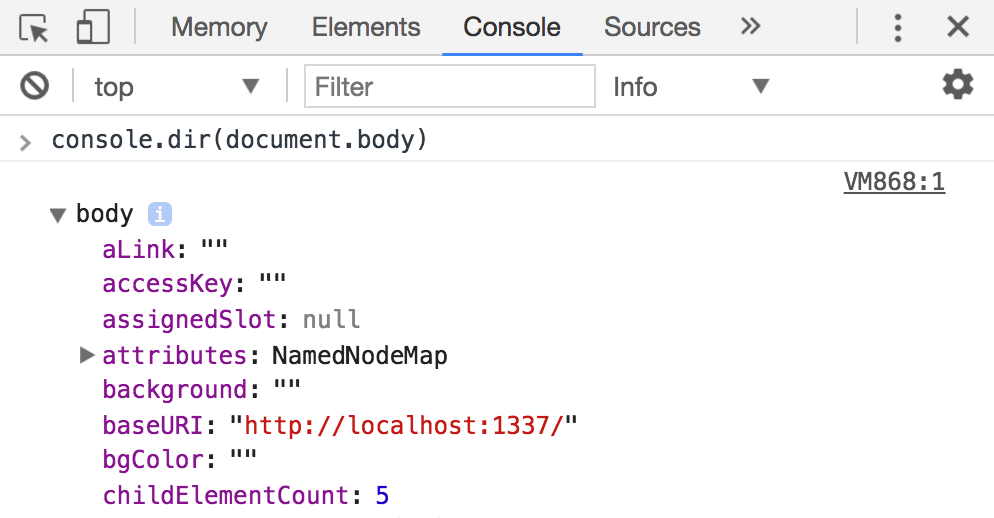
Функция console.dir выводит узлы DOM в формате, удобном для интроспекции.
JS: DOM API → Тесты
Тесты, с которыми мы имели дело до этого курса, сильно отличаются от тех тестов, которые используются при проверке фронтенда.
Типичный тест выглядел так: импортируется необходимая функция, а затем вызывается с разными аргументами.
import sum from '../sum';
test('adds 1 + 2 to equal 3', () => {
expect(sum(1, 2)).toBe(3);
});
Все просто и понятно. Конечно, если функция не чистая, то тест будет сложнее, но в любом случае с этим можно разобраться.
Такие тесты называются юнит и интеграционными, в зависимости от того сколько подсистем вовлечено в проверку. Причем, невозможно провести четкую границу между этими видами тестирования, лучше воспринимать их названия как шкалу, где слева - юниты, а справа интеграционные, а ваши тесты где-то между ними.
А как тестировать поведение кода в браузере? Ведь, по сути, основные действия, выполняемые таким кодом, это манипуляция домом.
Системные тесты
Тестировать такой код действительно можно. Для этого используется специальный софт, webdriver, который посылает команды из теста в браузер и возвращает результат обратно. То есть код теста имитирует настоящие действия пользователей и смотрит то, как изменился дом. Такой вид тестов называется системным.
import Nightmare from 'nightmare';
const nightmare = new Nightmare({ show: true });
test('duckduckgo', async () => {
const link = await nightmare
.goto('https://duckduckgo.com')
.type('#search_form_input_homepage', 'github nightmare')
.click('#search_button_homepage')
.wait('#zero_click_wrapper .c-info__title a')
.evaluate(() => document.querySelector('.c-info__title a').href);
expect(link).toBe('www.nightmarejs.org');
});
В примере выше много тонких моментов, которые стоит разобрать.
Nightmare — это библиотека для системного тестирования. Внутри себя она использует конкретный драйвер, но для нас сейчас это не принципиально. Таких библиотек достаточно много, особенно в мире js. Конкретно nightmare , с одной, стороны популярная библиотека, с другой — позволяет запускаться в среде без графической оболочки, что важно при разработке.
В тесте, первым делом, мы указываем адрес страницы, которую необходимо открыть. Затем начинаем манипулировать этой страницей. type функция, которая вводит текст по указанному селектору, click , очевидно, выполняет клик по элементу.
А вот что такое wait ? Как вы знаете, браузер работает асинхронно. После клика на элемент не происходит блокирования, мы можем продолжать работать дальше. Как только код выполнится, то возможно произойдут изменения на странице. А вот то, когда это произойдет, никто сказать не сможет. Все, что мы можем делать, это постоянно опрашивать дом на наличие требуемого изменения. wait упрощает эту задачу. Эта функция принимает на вход селектор, за которым надо следить, и ждет его появления. Если он появился, то управление передается дальше, если нет, то происходит ошибка.
Дальше мы видим функцию evaluate . Эта функция позволяет выполнить произвольный код внутри браузера. Подчеркну, тот код, который будет описан внутри функции, передающейся в evaluate , выполняется не в том месте, где запустились тесты, а внутри браузера, с которым работает драйвер. Как правило, в этом месте извлекают данные, которые нужно проверить в тесте. evaluate возвращает промис, из которого можно извлечь результат, используя async/await .
Плюсы и минусы
Системные тесты, как правило, дают гораздо бОльшие гарантии того, что ваша система работает. Поэтому их писать полезно на особо критические участки. Но покрывать ими все от и до, занятие не для слабонервных. Минусов у этого вида тестирования вагон и маленькая тележка:
Тесты очень хрупкие
Это значит что незначительные изменения в верстке, приводят к тому что они ломаются. Так как они завязаны на селекторы. Эту проблему частично можно невелировать, используя, так называемый, паттерн Page Object. Его идея крайне проста. Давайте сделаем абстракцию над каждой страницей и будем работать через нее:
test('LoginPage', () => {
LoginPage.open();
LoginPage.username.setValue('foo');
LoginPage.password.setValue('bar');
LoginPage.submit();
expect(LoginPage.flash.getText()).toBe('Your username is invalid!');
});
Такой подход важен и позволяет снизить хрупкость, но все равно эти тесты ломаются часто тогда, когда все работает и дело не только в верстке. Например увеличение времени ответа может приводить к таймаутам, а иногда вообще происходят странные флуктуации и один запуск приводит к прохождению теста, а другой падает. В общем занятие не для слабонервных.
Сложно писать
В системных тестах нужно полностью имитировать действия пользователей, а значит активно взаимодействовать с домом. Во время их написания, приходится постоянно шариться по исходному коду страницы, чтобы понять как выбирать те или иные элементы. Особенно этот процесс осложняется при использовании внешних компонентов, которые генерируют с помощью js сложную верстку.
Так же сложности добавляет невозможность легко писать в стиле TDD. По сути, тесты всегда пишутся после отладки кода через браузер.
Ну и одна их самых больших проблем, это подготовка необходимых данных в проекте для конкретного теста, а так же очистка после. В таких тестах, обычно, нет прямого доступа к базе, а значит придется искать другие пути.
Сложно отлаживать.
Типичный вывод провалившегося теста выглядит так:
Селектор “.title” на странице не найден
За этим выражением может скрываться все что угодно, начиная от ошибки 500, заканчивая тем что у элемента стоит стиль display: none .
Долгое время выполнения
Просто как факт. Эти тесты выполняются крайне долго и большой тестовый набор может лопатить сайт часами и даже днями.
Разновидности системных тестов
Существуют и альтернативные подходы к системному тестированию. В основе тот же dom, но проверки строятся по другому.
Screenshot Testing
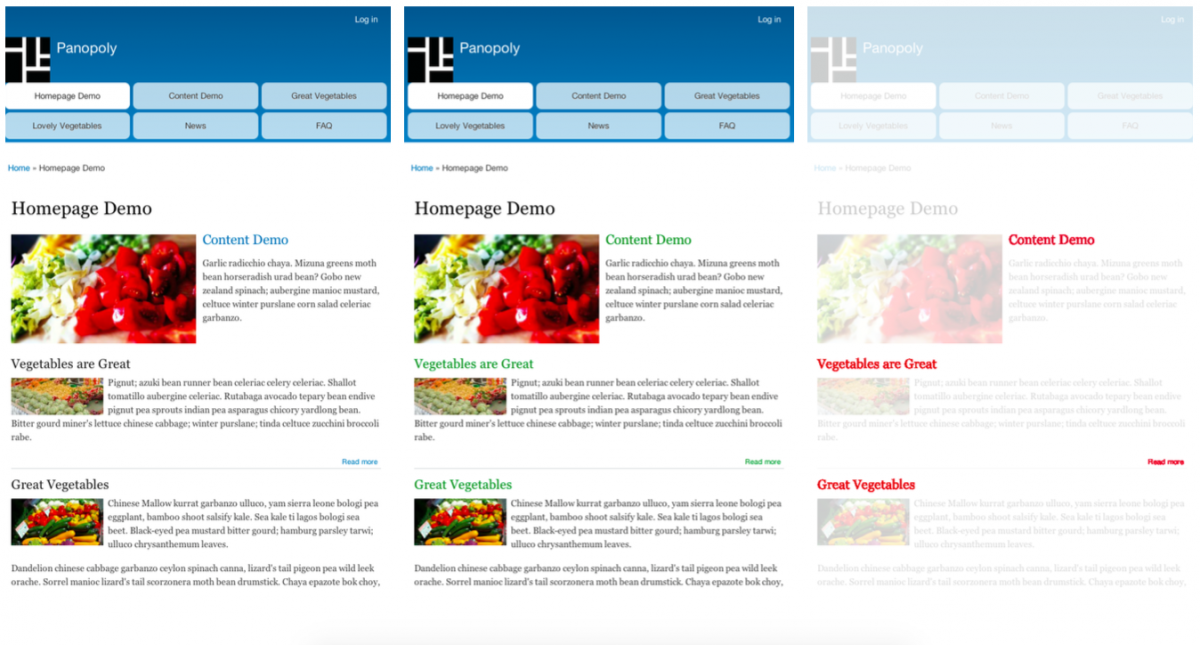
Такой тест при первом запуске создает скриншот страницы, а при последующих сравнивает результаты новых запусков с исходным скриншотом. На рисунке выше слева это исходный скриншот (получаемый автоматически), по середине результат очередного прогона, а справа дифф.
Snapshot Testing
Еще один способ тестирования, популяризированный компанией facebook в их фреймворке jest . Он похож на предыдущий способ, с той разницей, что сравниваются не скриншоты, а результирующий dom.
test('application', () => {
const element = document.querySelector('a[href="#profile"]');
element.click();
expect(getTree()).toMatchSnapshot();
const element2 = document.querySelector('a[href="#settings"]');
element2.click();
expect(getTree()).toMatchSnapshot();
const element3 = document.querySelector('a[href="#profile"]');
element3.click();
expect(getTree()).toMatchSnapshot();
});
Как видите, в тесте выше, нет точечных проверок. Есть только функции toMatchSnapshot . Вызов этой функции в первый раз (когда снепшота нет), создает снепшот в отдельной папке, а повторные вызовы будут сравнивать результирующий снепшот с тем эталонным.
Самое прекрасное в этой технике, то что она сильно упрощает анализ результата проверки. Ниже реальный пример из заданий хекслета:
Received value does not match stored snapshot 3.
- Snapshot
+ Received
@@ -18,11 +18,11 @@
<!-- Tab panes -->
<div class="tab-content m-3">
<div class="tab-pane" id="home" role="tabpanel">
Home
</div>
- <div class="tab-pane active" id="profile" role="tabpanel">
+ <div class="tab-pane" id="profile" role="tabpanel">
Profile
</div>
at Object.<anonymous> (__tests__/application.test.js:43:21)
Вывод почти такой же как и у git diff . Видно что было не так и как должно было быть. Такой подход практически идеален для задач на хекслете, так как сильно облегчает анализ для неподготовленных людей. Но за него приходится платить определенную цену. Так как снепшот содержит в себе всю страницу, то любое малейшее изменение dom, приводит к тому что все ломается. По этой причине, крайне важно, чтобы верстка была практически неизменяема. Банально классы добавленные в элемент не в той последовательности, приведут к тому что тесты упадут.
Другими словами, snapshot testing не панацея. Он отлично подходит для ситуаций где дом меняется редко и предсказуемо, например при разработке виджетов или в обучающих курсах.
JS: DOM API → Манипулирование DOM деревом
То, что DOM может меняться уже будучи отрисованным в браузере, и есть ключевая возможность для создания интерактивных приложений.
innerHTML
Самый простой способ обновить часть DOM — это функция innerHTML
<ul>
<li>item 1</li>
<li>item 2</li>
</ul>
const body = document.body;
console.log(body);
// <ul><li>item 1</li><li>item 2</li></ul>
body.innerHTML = '<b>make</b> love';
console.log(body);
// <b>make</b> love
console.log(body.childNodes);
// [b, text]
Эта функция целиком заменяет потомков элемента, на котором она была вызвана. Весь встречающийся внутри html парсится и становится частью дерева. Если вы пытаетесь вставить обычный текст, который потенциально может содержать html , то лучше воспользоваться другой, безопасной функцией textContent .
document.body.textContent = '<b>make</b> love';
console.log(document.body.innerHTML);
// "<b>make</b> love"
innerHTML работает со строками, такой подход удобен только в том случае, если мы работаем со статическим представлением DOM. Для динамического формирования хорошо подходят специальные функции.
Создание узлов
// Создаем текстовый узел
const textNode = document.createTextNode('life is life');
// Создаем элемент p
const pEl = document.createElement('p');
// Добавляем textNode в конце списка childNodes элемента pEl
pEl.append(textNode);
// pEl.textContent = 'life is life';
const el = document.createElement('div');
el.append(pEl);
console.log(el);
// <div><p>life is life</p></div>
Код, создающий DOM динамически, похож на матрешку. После создания одни элементы все время вкладываются в другие. Так выглядит код, который конструирует деревья в любом языке. Утомительное занятие, скажу я вам.
Вставка
const el = document.createElement('p');
document.body.prepend(el);
// автоматически удаляется из старого места
const elFromDom = document.querySelector('.col');
document.body.append(elFromDom);
append/prepend — не единственный способ добавить элементы в DOM:
-
node.prepend(...nodes)– вставляет nodes в начало node, -
node.after(...nodes)– вставляет nodes после узла node, -
node.before(...nodes)– вставляет nodes перед узлом node, -
node.replaceWith(...nodes)– вставляет nodes вместо node. -
node.remove()- удаляетnode
Как видите, разница между ними в том, что append/prepend с childNodes , а before/after с siblings .
Старый API
Описанные выше функции появились не так давно. Большая часть кода написана с использованием других функций, список которых ниже:
-
parent.appendChild(el)- добавляетelв конец списка детей -
parent.insertBefore(el, nextElSibling)- добавляетelв список детейparentпередnextElSibling -
parent.removeChild(el)- удаляетelиз детейparent -
parent.replaceChild(newEl, el)- заменяетelнаnewEl
Клонирование
Иногда требуется создать элемент, подобный уже существующему. Можно, конечно, это сделать полностью руками, копируя свойства одного в свойства другого, но есть способ проще:
const newEl = el.cloneNode(true);
true говорит о том, что нужно сделать “глубокую” копию, другими словами, вы получите копию не только этого элемента, но и всех его потомков.
JS: DOM API → Управление элементами DOM
Самая серьезная часть DOM API сосредоточена в свойствах конкретных элементов. В этом уроке мы рассмотрим только самые базовые свойства, исключительно с целью показать то, как это делается в принципе. В повседневной практике программисты постоянно обращаются к документации, чтобы узнать, как можно поменять то или иное поведение.
Атрибуты
Как правило, атрибуты, используемые в html , становятся свойствами элементов в DOM дереве под тем же именем.
<a id="aboutPage" href="/pages/about" class="simple">About</a>
const el = document.querySelector('#aboutPage');
el.className; // simple
el.id; // aboutPage
el.href; // /pages/about
Существуют и исключения, например, атрибуту class соответствует имя className . Более того, для удобной работы с классами предусмотрены дополнительные API. Оно нужно по той причине, что классов может быть много, и задаются они обычной текстовой строкой. Соответственно, если возникает задача изменения этого списка, то придется оперировать строчками, что совсем неудобно. А вот как можно это делать используя DOM API:
const el = document.querySelector('#aboutPage');
el.classList.add('page');
el.classList.remove('simple');
el.className; // page
Дополнительные методы:
-
el.classList.contains("class")– возвращает true/false -
el.classList.toggle("class")– если класс есть, удаляет его, и наоборот
С одной стороны атрибуты отображаются на свойства, но с другой есть множество нюансов.
- Атрибут всегда строка, а свойство — не всегда. Например:
<textarea rows="5"></textarea>
А значение свойства rows соответствующего элемента в DOM дереве будет числом.
2. Атрибуты не чувствительны к регистру
<a Id="aboutPage" hrEf="/pages/about" CLASS="simple">About</a>
Так писать, конечно же, не стоит, но по крайней мере знать о том, что оно работает - полезно.
3. Аттрибут всегда присутствует в html (а значит innerHTML )Это довольно логично. А вот огромное количество свойств не присутствует в html . Причем, для некоторых вообще нет аналогов, а другие получают значение по умолчанию, если атрибут не проставлен.
Как мы увидели выше, атрибут и свойство, в общем случае — не одно и то же. Поэтому существует набор методов для управления атрибутами:
el.hasAttribute(name) – проверяет наличие атрибута el.getAttribute(name) – получает значение атрибута el.setAttribute(name, value) – устанавливает атрибут el.removeAttribute(name) – удаляет атрибут el.attributes - список html атрибутов
// Методы работают с атрибутами html
el.getAttribute('class');
Обратите внимание на то, что они работают именно с атрибутами (их именами), а не свойствами. И позволяют не только их извлекать, но и менять. Возникает закономерный вопрос: поменяется ли атрибут если поменять свойство и наоборот?
В основном синхронизация осуществляется только в сторону свойств. То есть, меняется атрибут и автоматически обновляется свойство. Но существуют и исключения. Из этих тезисов не следует делать вывод, что нужно стараться работать через аттрибуты. Наоборот, по возможности, всегда работайте со свойствами дом дерева, а аттрибуты используйте только для чтения, чтобы получить то состояние, которое было в доме на момент инициализации (парсинга html).
<a id="aboutPage" href="/pages/about" class="simple">About</a>
const el = document.querySelector('#aboutPage');
el.setAttribute('class', 'page');
el.className; // page
el.getAttribute('class'); // page
В отличие от свойств, значение атрибута всегда совпадает с тем, что мы видим в html , а вот для свойства иногда приводятся в нормализованный вид:
<!-- В этот момент браузер открыт на https://ru.hexlet.io -->
<a id="link-to-courses" href="/courses">Курсы</a>
const el = document.querySelector('#link-to-courses');
el.href; // https://ru.hexlet.io/courses
el.getAttribute('href'); // /courses
Нестандартные атрибуты никогда не превращаются в свойства соответствующих элементов DOM дерева. То есть, если мы добавим в тег p свойство href то оно будет проигнорировано. Хотя это не отменяет возможность его извлечения через getAttribute .
Для работы с произвольными свойствами в html зарезервирован специальный атрибут data-* , где на месте звездочки может стоять любое слово.
<a href="#" data-toggle="tab">Мои проекты</a>
Такие атрибуты активно используются в js плагинах и позволяют не завязываться на классы. В элементах DOM они доступны через специальное свойство dataset :
console.log(el.dataset.toggle); // tab
Внутри объекта dataset имя каждого свойства — это строка после data- в атрибуте. Если имя содержит дефис, то он удаляется, а следующее за ним буква становится заглавной:
<a href="#" data-nav-toggle="tab">Мои проекты</a>
console.log(el.dataset.navToggle); // tab
Свойства
В зависимости от типа элемента меняется и набор свойств. Кроме, конечно, тех что достались в наследство от Node и Element .
Чтобы узнать список этих свойств, можно обращаться к спецификации. Они описаны в специальном формате, который интуитивно понятен:
interface HTMLLinkElement : HTMLElement {
attribute USVString href;
attribute DOMString? crossOrigin;
attribute DOMString rel;
attribute RequestDestination as; // (default "")
readonly attribute DOMTokenList relList;
attribute DOMString media;
attribute DOMString nonce;
attribute DOMString integrity;
attribute DOMString hreflang;
attribute DOMString type;
}
Кроме всего прочего, так как элементы являются обычными js объектами, мы можем добавлять в них любые свойства. Лучше такой подход не практиковать, но в теории вы можете на него наткнуться в реальных приложениях.
Правильный подход при работе с DOM состоит в том, что данные хранятся отдельно от DOM дерева.
JS: DOM API → Полифиллы
Как я уже неоднократно упоминал, DOM не везде одинаковый, к тому же он непрерывно развивается. Какие-то браузеры его адаптируют быстрее, какие-то медленнее. Все это не позволяет легко и непринужденно пользоваться последними новинками.
Впрочем, как мы уже знаем, то же самое относится и к самому js в браузере. С js нам помогает babeljs, а вот кто поможет с DOM?
Библиотеки, которые добавляют в DOM (вы ведь помните, что это просто объект?) необходимые свойства и методы, называются полифиллами.
Общий принцип работы этих библиотек следующий:
- Проверяем наличие возможности
- Если ее нет, то добавляем
Добавление метода
(function(constructor) {
const p = constructor.prototype;
if (!p.matches) {
p.matches = p.matchesSelector ||
p.mozMatchesSelector ||
p.msMatchesSelector ||
p.oMatchesSelector ||
p.webkitMatchesSelector;
};
})(window.Element);
Добавление свойства
(function(constructor) {
const p = constructor.prototype;
if (p.lastElementChild == null) {
Object.defineProperty(p, 'lastElementChild', {
get: function() {
const nodes = this.childNodes;
let i = nodes.length - 1;
let node;
while (node = nodes[i--]) {
if (node.nodeType === 1) {
return node;
}
}
return null;
}
});
}
})(window.Element);
Примеры выше не являются полными. Если посмотреть исходники соответствующих библиотек, то хочется их быстрее закрыть. Количество кода иногда зашкаливает до неприличия. Обратите внимание на то, что добавление свойства производится особым образом, таким, который позволяет сделать свойство динамическим и ленивым. То есть его значение будет вычислять только в момент обращения.
Чтобы узнать поддержку определенных фич в разных браузерах, можно воспользоваться прекрасным ресурсом https://caniuse.com/
Иногда бывает нужно просто проверить наличие определенной фичи, и в зависимости от результата выполнять разный код. В такой ситуации поможет библиотека modernizr .
Modernizr.on('flash', function( result ) {
if (result) {
// the browser has flash
} else {
// the browser does not have flash
}
});
А самый простой способ добавить полифиллы на свой сайт — это воспользоваться проектом https://polyfill.io/v2/docs/. Все что вам нужно будет сделать, это вставить следующий тег:
<script src="https://cdn.polyfill.io/v2/polyfill.min.js"></script>
Этот файл формируется динамически под конкретный браузер и на страницу закачивается только то, что нужно полифиллить.
JS: DOM API → Введение в события
Интерактивные системы, такие как сайты в браузере или, даже, терминал, устроены по одному и тому же принципу. После загрузки, они находятся в режиме “ожидания” действий от пользователя. К таким действиям относятся клики, набор текста, перемещение мышки, горячие клавиши и многое другое.
С точки зрения кода, все действия представлены событиями. События в браузере, являются частью стандарта DOM. Вот некоторые из них:
- click
- submit
- keyup/keydown
- focus
- contextmenu
- mouseover
- mousedown/mouseup
Как видите, их гранулярность достаточно высокая, набор текста раскладывается на два события: кнопка зажата и кнопка отпущена. Кроме этого, есть специальное событие keypress , которое позволяет отличать горячие клавиши от нормального ввода.
Самый простой способ попробовать события в действии, это использование специализированных атрибутов:
<button onclick="alert('Бум!')"></button>
<div onclick="alert(this.innerHTML)">Бум!</div>
Нажмите эту
, для демонстрации.
Обратите внимание на следующие моменты:
- js, при таком использовании, задается как строка текста, а значит вы, никаким образом, не отследите возникающие внутри ошибки, до тех пор пока не инициируете событие.
- В этой строке должен быть вызов функции, то есть так
onclick="alert"не заработает. - Внутри подобных атрибутов доступен
this, который ссылается на текущий элемент.
Обработчик события можно определить и снаружи:
<script>
const getBoom = () => alert('Boom!');
<script>
<button onclick="getBoom()"></button>
Ну и конечно через свойство элемента в DOM:
<button id="myButton"></button>
const button = document.getElementById('myButton');
button.onclick = () => alert('Boom!');
В такой ситуации мы не вызываем обработчик, а только устанавливаем его в свойство onclick .
У этого способа есть один недостаток, который актуален там, где на странице есть множство скриптов, работающих независимо на одних и тех же элементах. Он заключается в том, что невозможно повесить одновременно несколько обработчиков. Перезаписав свойство onclick старый обработчик будет потерян безвозвратно.
На уровне аттрибутов эта проблема не решаема, но в DOM есть метод, позволяющий повесить множество обработчиков.
<button id="myButton"></button>
const button = document.getElementById('myButton');
button.addEventListener('click', () => alert('Boom 1!'));
button.addEventListener('click', () => alert('Boom 2!'));
Каждый обработчик события, представляет собой функцию, которая будет вызвана в момент наступления события. Обработчики вызываются один за другим, в том же порядке, в котором они были определены. Подчеркну что обработчик это функция, а не вызов функции. Вот так делать неверно:
const button = document.getElementById('myButton');
const handler = () => alert('Boom 1!');
button.addEventListener('click', handler()); // передается не сама функция, а ее результат
При необходимости, можно удалить обработчик:
const button = document.getElementById('myButton');
const handler = () => alert('Boom 1!');
button.addEventListener('click', handler);
button.removeEventListener('click', handler);
Обратите внимание на то, что удаление сработает только в том случае, если вы передадите в функцию removeEventListener ту же самую функцию. Не “такую же по структуре”, а именно ту же самую, другими словами такой код не удалит нужный обработчик:
const button = document.getElementById('myButton');
button.addEventListener('click', () => alert('Boom 1!'));
button.removeEventListener('click', () => alert('Boom 1!'));
В процессе выполнения обработчиков могут возникать новые события, как от действий пользователя, так и программно, в самих обработчиках, а некоторые события всегда возникают целым блоком, например mouseup и click . Но это не означает что выполнение кода сразу переключается на обработку этих событий. Вместо этого, события складываются в очередь и будут выполнены строго последовательно.
Но некоторые события, все же, берутся в обработку сразу. Это касается тех событий, которые генерируются программно, например onfocus .
Возникает закономерный вопрос, что происходит со страницей во время выполнения обработчика? И здесь возможны варианты. Если обработчик выполняет некоторый код синхронно, например занимается вычислениями, то в этот момент, блокируется все остальное (не считая webworkers) и страница замирает (говорят фризится).
Если такое поведение длится слишком долго, то некоторые браузеры зависают, а другие предлагат закрыть вкладку. Отсюда вывод, обработчики должны выполнять свою задачу максимально быстро. Если задача долгая и синхронная, то ее можно вынести либо в webworker, либо разбить на этапы, фактически реализовав кооперативную многозадачность (основы операционных систем, в любой книге). Самый простой способ сделать это, переодически прерывать выполнение и продолжать выполнять через setTimeout . Это позволит выполниться остальным событиям.
А что если задача асинхронная, например выполняется запрос к серверу? В таком случае все продолжает прекрасно работать.
Вообще говоря, из этого урока должно стать понятно, почему js именно такой, какой есть. Событийная система возможна только в асинхронном коде. По сути, при загрузке страницы происходит инициализация и установка обработчиков, а дальше, как правило, не выполняется никакой код, вся страница находится в ожидании действий от пользователя.
Объект события
С каждым возникающим событием связана информация, зависящяя от типа события. Например событие click это не только факт сам по себе, но так же и координаты точки на экране, где был совершен клик. Эта информация доступна через специальный объект-событие.
<div id="myElement">Бум!</div>
const button = document.getElementById('myElement');
button.addEventListener('click', e => alert(e.currentTarget.textContent));
По умолчанию этот объект передается всегда, в любой обработчик, как единственный параметр. Если он вам не нужен, то его можно проигнорировать.
Базовые свойства объекта Event :
-
event.currentTarget- элемент на котором сработал обработчик события -
event.type- тип события
У каждого типа событий свой набор свойств, подробнее о них смотрите в документации.
Действие по умолчанию
Некоторые элементы в DOM обладают действиями по умолчанию. Например если повесить обработчик на клик по ссылке, то выполнив этот клик, мы внезапно перейдем на другую страницу, ту которая была указана в href . Здесь мы видим пример того самого действия по умолчанию, на которое никак не влияет наличие обработчиков. Чтобы отменить это действие, а такое бывает нужно часто, необходимо вызвать метод event.preventDefault() внутри обработчика.
<a href="#" id="myElement">Бум!</a>
const button = document.getElementById('myElement');
button.addEventListener('click', (e) => {
e.preventDefault();
alert(e.currentTarget.textContent);
});
Иногда вы можете встретить такой код:
<a href="#" id="myElement" onclick="alert('hey'); return false;">Бум!</a>
Возврат false внутри значения аттрибута, приводит к такому же эффекту.
Действиями по умолчанию обладают следующие элементы:
- Клик по ссылке приводит к переходу на страницу указанную в
hrefаттрибуте. - Клик на кнопку с типом
submitначинает отправку формы на сервер. - Вращение колесом мышки в
textareaпередвигает текст если он не помещается - Вызов контекстного меню с помощью правого клика мышки
Оживление страницы
В промышленной разработке, как правило, в первую очередь используются уже написанные кем-то компоненты, и только в крайнем случае используются свои. Большая часть этих компонентов реализована таким образом, что может работать с любым сайтом и с минимальным уровнем конфигурирования. Вплоть до того, что вам даже не придется вызвать js для его работы.
Существует несколько подходов, которые используются для подключения компонентов на странице:
Через класс
Здесь все очень просто. Для работы компонента требуется наличие определенного класса у тега. Иногда есть класс по умолчанию, который описан в документации, но его можно и поменять.
<select class="style-select">
<option>1</option>
<option>2</option>
</select>
<script>
styleSelect('select.style-select');
</script>
Через data-* аттрибуты
Этот подход более гибкий и, например, активно используется в Bootstrap. Вместо указания классов, каждый компонент определяет свой data-* аттрибут (или набор таких аттрибутов). Одно из преимуществ перед классами заключается в том, что, в отличие от класса, аттрибут имеет значение и это можно использовать.
Библиотека jquery-ujs , изначально написанная для rails (но подходит для всего), позволяет очень легко получать разные возможности в html без прямого использования js. Например мы можем захотеть сделать отправку по ссылке используя глагол POST . С этой библиотекой достаточно написать следующее:
<a href="page/url" data-method="post">Submit</a>
Возможно мы хотим подтверждение действия перед выполнением. Делается это крайне просто:
<a href="page/url" data-confirm="Are you sure?">Submit</a>
Точно так же в Bootstrap работают почти все компоненты. Например выпадающее меню:
<div class="dropdown">
<button class="btn btn-secondary dropdown-toggle" type="button" data-toggle="dropdown">
Dropdown button
</button>
<div class="dropdown-menu">
<a class="dropdown-item" href="#">Action</a>
<a class="dropdown-item" href="#">Another action</a>
<a class="dropdown-item" href="#">Something else here</a>
</div>
</div>
JS: DOM API → Перехват и всплытие
Начнем этот урок с демонстрации. Вызовите контекстное меню на вашем компьютере и кликните вне этого меню в любой части экрана. Вы увидите что окно закроется. Здравый смысл подсказывает, что невозможно повесить обработчик на абсолютно все элементы на экране, который бы закрывал это меню.
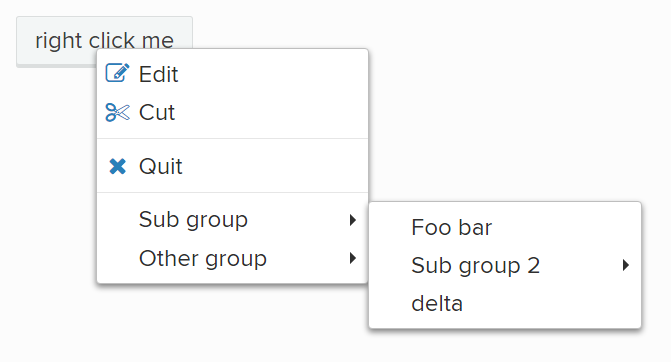
Это правда, обработчик на закрытие ровно один, и висит он на корневом элементе. А работает это так, когда происходит событие, то проверяется наличие соответствующего обработчика на элементе связанного с событием. Если такой обработчик не найден, то он ищется среди его предков и так до самого верха. Этот механизм называется “всплытие” (bubbling).
Но всплывают не все события, к таким относится focus . А фреймфорки подобные React исправляют это поведение, упрощая работу с событиями.
<body onclick="alert('это был не я')">
<button>Нажми меня</button>
</body>
Поэтому внутри объекта события, различают две цели:
-
event.currentTarget- элемент на котором сработал обработчик -
event.target- элемент на котором произошло событие
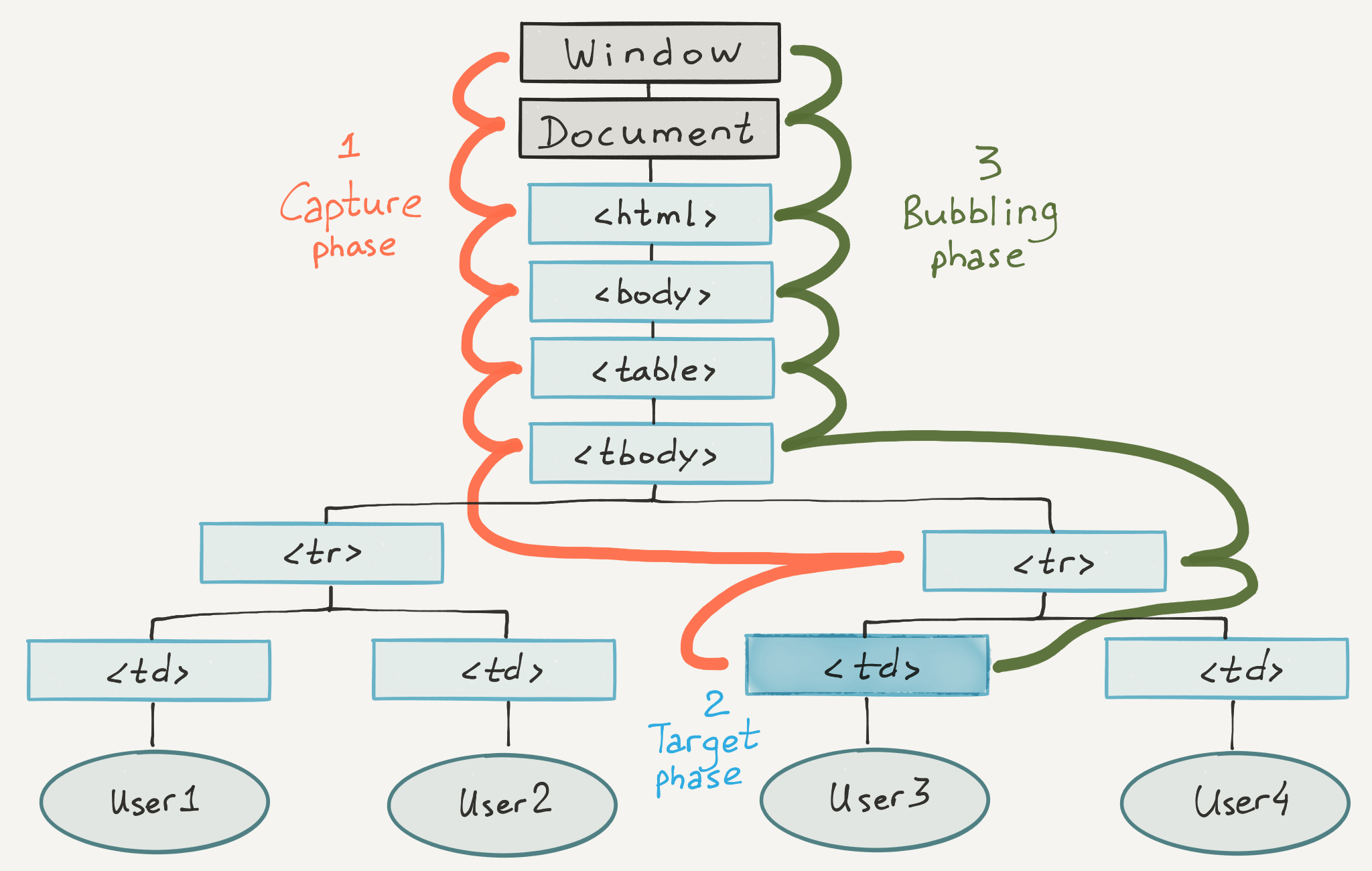
Как видно из картинки, кроме стадии всплытия, существует и стадия перехвата (погружения). Чтобы поймать событие в этой стадии, нужно в функцию element.addEventListener , третьим параметром передать флаг true .
Остановка всплытия
Как правило, событие должно всплывать до конца, но иногда могут возникать ситуации, при которых нужно остановить всплытие.
Сделать это можно двумя способами:
event.stopPropagation()event.stopImmediatePropagation()
Первый останавливает всплытие, но дает возможность доработать всем обработчикам, которые висят на текущем элементе, второй же, не дает выполнится больше ни одному обработчику.
JS: DOM API → События документа
Кроме событий, которые возникают в ответ на действия пользователей, существует ряд событий, которые живут своей жизнью. К таким событиям относятся события на загрузку и выгрузку страницы:
-
DOMContentLoaded– DOM-дерево построено -
load– все ресурсы загружены (картинки, стили, скрипты, …) -
beforeunload- уйти со страницы
DOMContentLoaded возникает в тот момент, когда DOM дерево полностью построено и готово к работе, но, при этом, стили, скрипты и картинки могут находится в процессе загрузки.
Это событие происходит на document :
<script>
document.addEventListener('DOMContentLoaded', () => {
const coll = document.querySelectorAll('.help');
[...coll].forEach(el => el.classList.add('hidden'));
});
</script>
Скорость построения DOM дерева, очень зависима от тегов script в html . По стандарту, любой script встреченный в html будет выполняться до полного построения дерева. Следовательно скорость отработки кода в этом блоке script будет сильно влиять на то, когда пользователь увидит сам сайт и то, когда сработает событие DOMContentLoaded .
Поскольку DOM полностью готов только тогда, когда срабатывает событие DOMContentLoaded , многие механизмы активизируются именно на нем, например, браузерная подстановка значений в поля форм. По этой же причине, большинство сайтов, инициализируют интерфейсы также на этом событии.
Тема оптимизации загрузки скриптов и быстрой инициализации достаточно сложна. Это связано не только с большим количеством факторов влияющих на порядок и скорость, но так же и с тем, что в разных браузерах этот механизм работает по разному. Здесь мы не будем его разбирать, это тема продвинутого уровня и на нее написано множество статей.
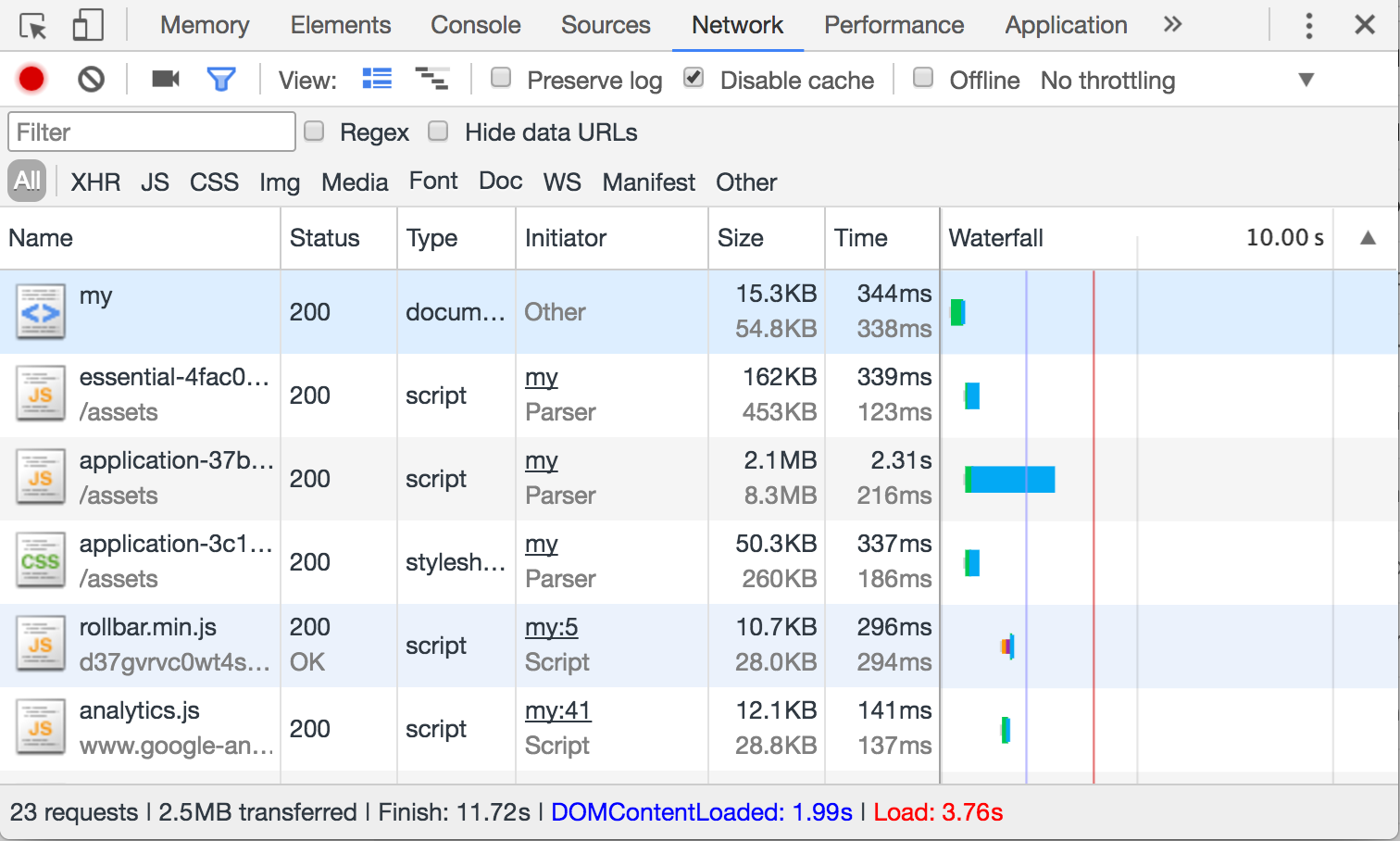
Обратите внимание на красную и синюю полоску. Красная показывает момент когда сработало событие load , а синяя - DOMContentLoaded . Внизу картинки указано время срабатывания каждого события, от начала загрузки страницы.
Из картинки видно, что браузер сначала скачивает саму страницу (ее html), а затем начинает скачивать ресурсы (картинки, стили и скрипты), причем делает это параллельно.
JS: DOM API → AJAX
Манипуляции с dom деревом помогают сделать наши сайты более живыми, но их все же недостаточно для создания автономных виджетов или полноценных (имеющих бекенд) Single Page Application (SPA).
Рассмотрим конкретный пример. Многие сервисы дают возможность использовать разные виджеты, например, погода или курсы валют. Работает это так, вы вставляете в свой html код предоставленный сервисом. Далее это код подгружает сам виджет и периодически обращается за необходимыми данными на сервера сервиса. Это может происходит в тот момент когда пользователь виджета нажимает кнопки требующие новых данных, например, показать погоду за следующую неделю.
Кстати подобный виджет используется на Хекслете. В уроке в правом нижнем углу есть пункт “Техподдержка”, а вне уроков в углу висит синий кружочек. По нажатию появляется специальная форма обратной связи. Она предоставлена специальным сервисом, который помогает нам обрабатывать фидбек от пользователей, причем работа этой формы никак не связана с бекендом Хекслета.
Ключевая технология в этой истории, это механизм для выполнения http запросов прямо из браузера. Именно его называют AJAX, что расшифровывается как “Asynchronous JavaScript and XML”. Несмотря на название, эта технология работает не только с xml.
XMLHttpRequest
До появления html5, браузеры предоставляли (и сейчас предоставляют) специальный объект XMLHttpRequest :
const request = new XMLHttpRequest();
const request.onreadystatechange = () => {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = this.responseText;
}
};
request.open("GET", "/api/v1/articles/152.json", true);
request.setRequestHeader('X-Requested-With', 'XMLHttpRequest');
request.send();
Работать с ним крайне неудобно и, по сути, все использовали обертку созданную в рамках библиотеки JQuery. Подробнее об этом будет в уроке посвященному JQuery.
Fetch
С появлением стандарта HTML5, появился новый механизм для http запросов:
// const promise = fetch(url[, options]);
fetch('/api/v1/articles/152.json')
.then((response) => {
console.log(response.status); // 200
console.log(response.headers.get('Content-Type'));
return response.json();
})
.then((article) => {
console.log(article.title); // Как использовать fetch?
})
.catch(console.error);
Как видно, fetch это функция возвращающая промис, а значит работать с ней удобно и приятно. А благодаря наличию полифиллов можно не переживать о том что какой-то браузер не поддерживает этот механизм.
Обратите внимание на то что response.json тоже возвращает промис. Кроме json данные можно получать используя функции blob , text , formData и arrayBuffer .
Отправка формы POST запросом:
const form = document.querySelector('form');
fetch('/users', {
method: 'POST',
body: new FormData(form),
});
–
Отправка формы как json:
fetch('/users', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
name: 'Hubot',
login: 'hubot',
})
})
При всех своих преимуществах, fetch довольно низкоуровневый механизм. Например работая с json (очень частый вариант), придется самостоятельно выставлять заголовки и делать разные манипуляции с данными, которые можно было бы автоматизировать.
На практике, это привело к созданию различных библиотек, которые работают схожим образом, но дают гораздо больше возможностей. Причем многие из этих библиотек изоморфные, то есть работают одинаково и в браузере и на сервере. Одна из самых популярных библиотек на момент создания курса - axios.
URL
Как мы знаем из предыдущих курсов, клеить строчки для работы с путями или урлами это плохая идея. Можно легко ошибиться и, в целом, приходится выполнять работу, которую может выполнять машина. В node.js с этим никаких проблем, у нас есть соответствующие модули, а вот в браузере это всегда вызывало сложности. Распарсить url или собрать легко и просто не получалось.
С одной стороны, можно всегда воспользоваться сторонними библиотеками, которых достаточно много, но с другой, в браузерах уже есть встроенный для этого механизм (как обычно добавляется полифиллами).
const url = new URL('../cats', 'http://www.example.com/dogs');
console.log(url.hostname); // www.example.com
console.log(url.pathname); // /cats
url.hash = 'tabby';
console.log(url.href); // http://www.example.com/cats#tabby
url.pathname = 'démonstration.html';
console.log(url.href); // http://www.example.com/d%C3%A9monstration.html
Что особенно приятно, fetch умеет работать с объектом URL напрямую:
const response = await fetch(new URL('http://www.example.com/démonstration.html'));
А вот как можно работать с query параметрами:
// https://some.site/?id=123
const parsedUrl = new URL(window.location.href);
console.log(parsedUrl.searchParams.get('id')); // 123
parsedUrl.searchParams.append('key', 'value')
console.log(parsedUrl); // https://some.site/?id=123&key=value
HTTP access control (CORS)
В отличие от бекенда, http запросы на клиенте могут использоваться злоумышленниками, для кражи данных. Поэтому браузеры контролируют то куда и как делаются запросы.
Подробно об этом механизме можно прочитать тут
JS: DOM API → JQuery
В августе 2006 года Джон Резиг выпустил библиотеку JQuery . За короткое время эта библиотека завоевала огромную популярность и стала стандартом де-факто при разработке интерактивных элементов на сайтах.
// Знак $ — это функция JQuery, через которую все и делается
$(() => {
// Эта функция выполнится на событие DOMContentLoaded
});
Во многом, это случилось, потому что JQuery появилась в нужное время в нужном месте. В те года шел переход к верстке без использования таблиц, и css использовался все активнее и разнообразнее. JQuery позволил переиспользовать те же самые селекторы для добавления поведения.
К тому же в JQuery был реализован CSS3 гораздо раньше, чем он появился нативно в самих браузерах. Более того, JQuery в принципе позволила практически не думать о разных браузерах, так как ее задачей было, в том числе, обеспечить работоспособность на всех платформах.
// Работает так же, как и document.querySelectorAll
const spans = $('.section span');
Еще одной причиной успеха стало то, что JQuery популяризовал отделение верстки от поведения. Такую технику называют “ненавязчивый javascript”. Ее идея в том, что обработчики событий описываются не в самих тегах, а отдельно:
$('button').click(() => {
alert('hey!');
});
Вместо:
<button onclick="alert('hey!')">
Сам JQuery при этом является прекрасным примером DSL (предменто-ориентированный язык), с очень натуральным api . Как правило, код на JQuery выражает задачу в тех же терминах, в которых эта задача формулируется:
$('container.main').hide();
$('#address').remove();
// Fluent interface
$('#p1').css('color', 'red').slideUp(2000).slideDown(2000);
И это еще не все. JQuery долгое время предоставляла единственный нормальный способ делать AJAX запросы и анимацию на страницах. А благодаря расширяемости, за счет плагинов, экосистема библиотеки за десяток лет стала фантастических размеров. В какой-то период времени любая библиотека для фронтенда появлялась как плагин к JQuery. Вплоть до того, что некоторые люди вообще не догадываются о существовании javascript и DOM. Они сразу начали с JQuery и видят мир только сквозь него.
Манипуляции
Функция $ — это единая точка входа для всего. Если ее вызвать и передать внутрь строчку, то JQuery считает, что строка — это селектор, и нужно сделать выборку элементов DOM. Этот вызов аналогичен вызову querySelectorAll , с тем лишь отличием, что возвращается специализированная коллекция.
Более того, JQuery, в принципе, работает с элементами как с коллекциями, даже если это один элемент. И любые изменения применяются сразу ко всем элементам коллекции без необходимости итерирования.
// Selecting all <h1> tags.
const headings = $('h1');
const firstHeader = headings.get(0); // извлечение DOM элемента
// Ниже два эквивалентных примера
headings.addClass('header');
headings.each((i, header) => $(header).addClass('header'));
В последнем примере, во время итерации, в функцию передается именно DOM нода. Чтобы сделать из нее JQuery коллекцию, придется делать оборачивание: $(domNode) .
// Если был найден один заголовок
const link = $('#home');
link.html('link to home'); // val(), text()
link.attr('href', '/about'); // prop(), css()
console.log(link.attr('href')); // /about
Выше приведено несколько примеров функций, изменяющих дом элемент и его потомков. Главная особенность JQuery здесь в том, что если вызвать эти функции без параметров, то они возвращают значение, если вызвать с параметрами, то изменяют.
События
$('button').click(() => {
$('#w3s').attr('href', (i, origValue) => `${origValue}/jquery`);
});
Либо так:
$('button').on('click', () => {
$('#w3s').attr('href', (i, origValue) => `${origValue}/jquery`);
});
AJAX
const jqxhr = $.get('/api/v1/companies.json', (data) => {
console.log('success');
})
.done(() => {
console.log('success');
})
.fail(() => {
console.log('fail');
})
.always(() => {
console.log('finished');
});
Как видно из примера выше, интерфейс промисов JQuery не совпадает с принятым стандартом.
Анимация
<div id="clickme">
Click here
</div>
<img id="book" src="book.png" alt="" width="100" height="123">
<script>
// With the element initially hidden, we can show it slowly:
$('#clickme').click(() => {
$('#book').show('slow', () => {
// Animation complete.
});
});
</script>
JQuery, с одной стороны, дает набор готовых анимаций, с другой — представляет механизм для создания более сложных эффектов, основанных на изменении css свойств.
JQuery UI
Это группа плагинов к JQuery, которая реализует типичную функциональность, необходимую при разработке интерактивных сайтов, например, перетаскивание, автокомплит, изменение размеров, сортировка и многое другое.
Перспективы
В свое время JQuery была прекрасным выбором, но это время уходит. С момента выхода библиотеки веб ушел вперед. Стандарт DOM развился настолько, что многие вещи делать напрямую удобнее, чем через JQuery, а поддержка самого стандарта браузерами достаточно высока. В тех местах, где поддержки не хватает, всегда есть полифиллы. К тому же появились новые стандарты, в которые JQuery не вписывается. Ярким примером служат промисы и тот же AJAX.
Все это приводит к тому, что постепенно происходит отказ от JQuery. Для любых задач на фронтенде можно найти множество популярных библиотек, которые в своей нише будут лучше, чем то, что предлагает JQuery.
Есть еще один очень важный аспект. Хотя JQuery и позволила упростить работу с DOM (когда он был плох), этого недостаточно для создания по-настоящему сложных интерактивных сайтов. В 2015 году я делал доклад на эту тему, где подробно объяснял, почему прямое манипулирование домом (пусть даже через JQuery) — концептульно неверный путь. Такой подход срабатывает в тривиальных ситуациях, а дальше все становится очень быстро слишком сложно.
Поэтому современные проекты строят с использованием React, Vue, Angular и других фреймворков, а JQuery не используют совсем.
С другой стороны, на JQuery уже столько понаписано, что его требуют знать в любой вакансии, связанной с фронтендом. Как вы могли убедиться исходя из примеров выше, ничего сложного и фантастического в JQuery нет. Более того, в первую очередь надо знать DOM, а остальное — это просто внимательное чтение документации и примеров использования.
JS: DOM API → Состояние приложения
Манипулирование домом - задача простая только в самых примитивных ситуациях. Как только понадобится реализовать полноценное, пусть и небольшое, приложение, код моментально превращается в тыкву. Десятка обработчиков достаточно для того чтобы потеряться. С каждым новым событием сложность кода растет еще быстрее, а, ведь, в реальных приложениях событий сотни. Почему так происходит?
Хотя подобная проблема касается не только фронтенда, именно в нем, она достигает своего апогея. Событийная архитектура и дом, без должного внимания, порождают запутанный код буквально сразу. Понятно что где-то здесь появляется Архитектура, но где конкретно и как, это вопрос.
Подойдем к правильной архитектуре со стороны бекенда. Как вы уже знаете или догадываетесь, в бекенде приложения состоят минимум из двух частей - базы данных и собственно самого кода. Формы отправляемые на сервер, изменяют состояние приложения, которое хранится в базе, далее, на основе этого состояния формируется ответ в виде HTML страницы.
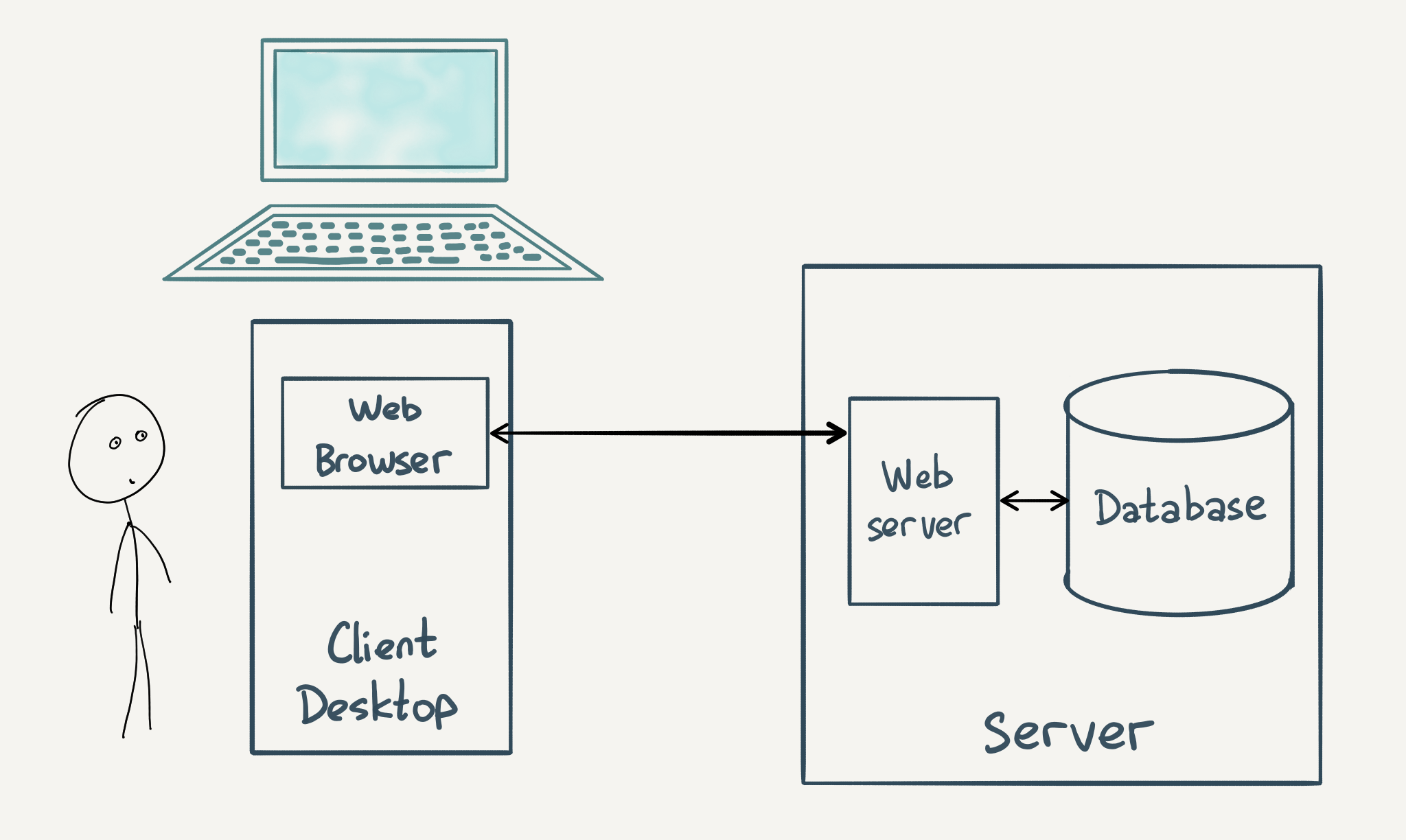
По сути, в типичных веб проектах, приложение занимается двумя вещами, либо обновляет данные в базе, либо извлекает эти данные и на основе них формирует HTML. Необходимость базы данных довольно очевидна и понятна для всех, но тоже самое не очевидно во фронтенде, DOM позволяет хранить состояние внутри себя и более того, провоцирует так делать. На протяжении курса мы встречались с этой ситуацией не раз, когда нужно выполнить некоторое действие, а оно зависит от того что сейчас на экране. Для анализа приходилось лезть в DOM и смотреть что же там происходит. Первый шаг в построении правильной архитектуры, состоит в выделении состояния из дома, в некое подобие базы данных, основанной на обычном объекте js. При такой организации кода, вырисовывается следующая схема работы:
- Возникает событие
- Меняется состояние
- Обновляется DOM
Ниже реализация этой идеи на примере простого счетчика. Состояние, в данном случае, одно число. Кнопка инкремента увеличивает его на единицу, кнопка декремента соответственно уменьшает.
https://codepen.io/hexlet/pen/pOpMgy
Главная особенность кода выше, в том как идет работа с состоянием. Здесь нет никаких обращений к дому для извлечения текущего значения, оно хранится в переменной и доступно для всех обработчиков.
Перед тем как смотреть более сложный пример, в котором состояние представлено объектом, давайте разберемся с тем, что включает в себя понятие состояние . Если коротко, то состояние это данные нашего приложения в любой момент времени, например, открытые вкладки в редакторе или браузере. Их количество и содержимое меняются в зависимости от того, какие кнопки мы нажимаем и что пытаемся загрузить. В общем случае, любое визуальное изменение в приложении или на странице, это всегда изменение состояния и никак иначе. Невозможна ситуация при которой на странице сайта меняется какая-то деталь, но состояние при этом остается тем же. Изменение представления возможно только на основе изменения состояния. Вы можете возразить, что анимация через CSS не меняет ничего в нашем приложении и будете правы лишь на половину. Да, анимация в css не связана с нашим приложением, но внутри браузера это состояние есть и оно меняется.
Отличным примером неочевидного, для начинающего фронтенд специалиста, состояния, служит состояние формы. Представьте себе поле для ввода телефона, которое отслеживает ошибки при вводе и сразу их показывает. Если ошибок нет, то оно позволяет выполнить сабмит формы, иначе кнопка заблокирована. Что в данном случае является состоянием? Однозначно состояние валидности данных формы: “валидно” и “не валидно”. На основе этого состояния определяется обводить красной рамкой поле для ввода или нет. Ну и конечно состоянием является заблокированность кнопки.
https://codepen.io/hexlet/pen/BOYyLX
Как видно из примера, состояние описывается обычным js объектом, который создается при старте приложения:
const state = {
registrationProcess: {
valid: true,
submitDisabled: true,
}
};
Нет никаких правил по формированию его структуры, как удобно так и делайте. Главное не привязывайте структуру состояния к визуальному оформлению, оформление зависит от состояние, но никак не наоборот. Пример того как делать не стоит ниже:
const state = {
centralBlock: {
valid: true,
submitDisabled: true,
},
sideBar: {
formValue: 'value'
},
};
Проблема такой структуры в том, что если поменяется дизайн (даже небольшое расположение элементов), то объект состояния перестанет отражать реальность и его придется править.
Далее обработчики событий. Они должны иметь доступ к состоянию, так как оно меняется именно в обработчиках. Поэтому обработчики определяются в той же функции где и создается состояние (главное не делать это на уровне модуля, состояние должно быть локально относительно приложения). Кроме того, обработчики это то место где выполняются ajax запросы. В нашем примере их нет, но на будущее не забывайте.
input.addEventListener('keyup', () => {
if (input.value === '') {
state.registrationProcess.valid = true;
state.registrationProcess.submitDisabled = true;
} else if (!input.value.match(/^\d+$/)) {
state.registrationProcess.valid = false;
state.registrationProcess.submitDisabled = true;
} else {
state.registrationProcess.valid = true;
state.registrationProcess.submitDisabled = false;
}
render(state);
});
Последнее что делается в обработчиках, в нашем примере, вызывается функция render , которая принимает на вход состояние и меняет DOM на его основе. Этот момент ключевой. Изменение DOM может происходит только внутри функции render . Весь остальной код может менять только состояние.
Теперь наше приложение разделено на три независимых части: состояние, обработчики и рендеринг. Эта модель работы на тривиальных приложениях (в пару тройку обработчиков) смотрится избыточной, но если обработчиков станет, хотя бы, 10, то вы увидите что с приложением достаточно удобно работать. Виден поток данных, всегда можно отследить что изменилось и как одни части приложения зависят от других. К тому же сокращается дублирование. Например изменение состояние может идти из разных частей приложения, но логика отрисовки, при этом, остается неизменной. В такой ситуации достаточно описать новый способ изменения уже существующего состояния, а рендеринг сделает все остальное.
const render = (state) => {
const input = document.querySelector('.phone');
const submit = document.querySelector('.submit');
submit.disabled = state.registrationProcess.submitDisabled;
if (state.registrationProcess.valid) {
input.style.border = null;
} else {
input.style.border = "thick solid red";
}
}
Кроме наличия разделения на три части, не менее важно то как они друг с другом взаимодействуют, более того, это основа модульности:
- Состояние не знает ничего про остальные части системы, оно ядро.
- Рендеринг ничего не знает про существование обработчиков, но пользуется состоянием для отрисовки
- Обработчики знают про состояние, так как обновляют его и инициируют рендеринг
Этот способ разделения по прежнему обладает одним важным недостатком, который мы устраним в следующем уроке, когда поговорим про MVC.
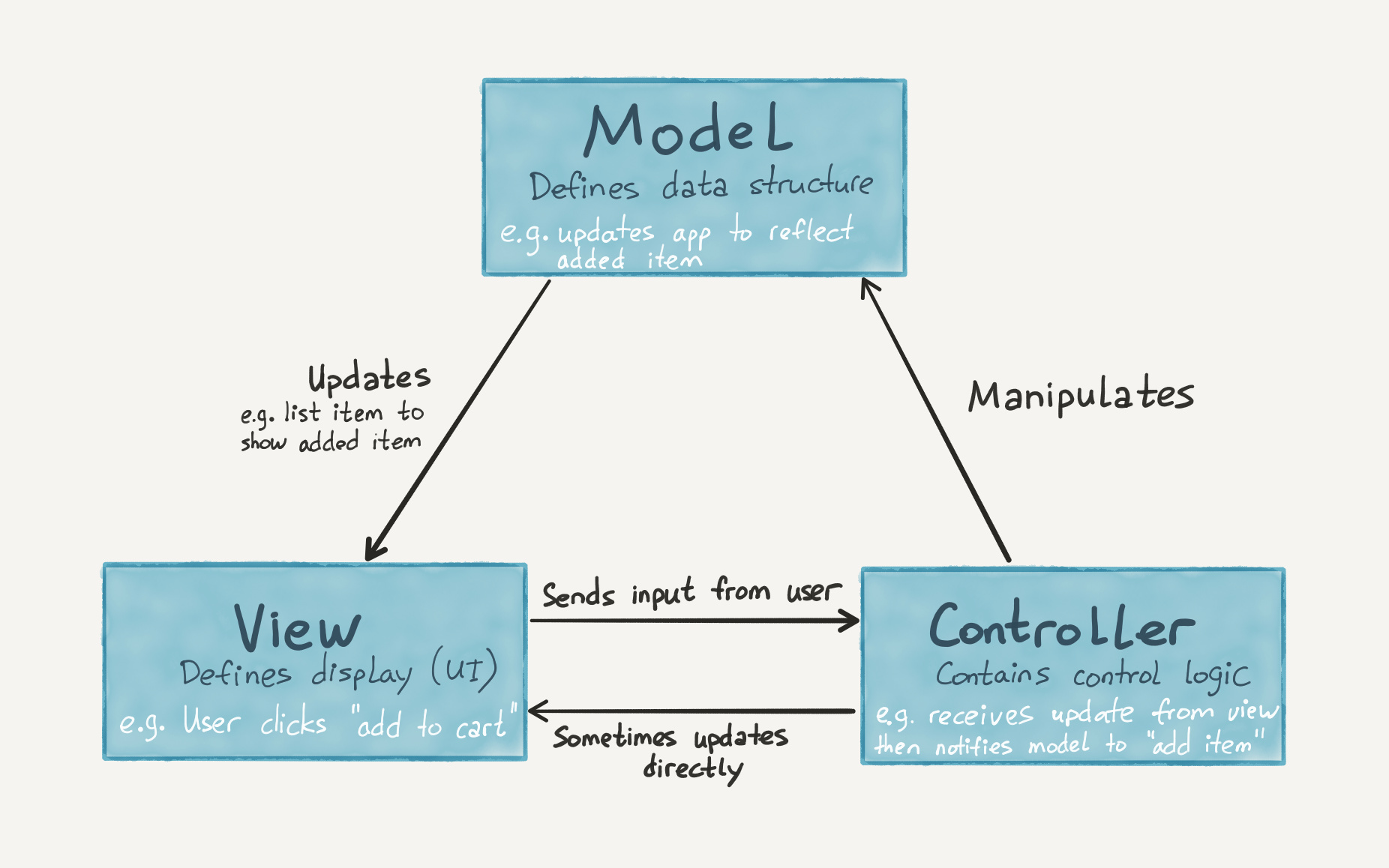
JS: DOM API → MVC
Как я говорил в прошлом уроке, наша схема работы с состоянием имеет один существенный недостаток - за вызов отрисовки отвечают обработчики. Ниже приведен, уже знакомый нам, пример демонстрирующий вызов render .
input.addEventListener('keyup', () => {
if (input.value === '') {
state.registrationProcess.valid = true;
state.registrationProcess.submitDisabled = true;
} else if (!input.value.match(/^\d+$/)) {
state.registrationProcess.valid = false;
state.registrationProcess.submitDisabled = true;
} else {
state.registrationProcess.valid = true;
state.registrationProcess.submitDisabled = false;
}
render(state);
});
Какие проблемы могут возникнуть при таком подходе?
Здесь стоит сказать, что на бекенде такой подход, как раз, оправдан. Бекенд работает в рамках другой парадигмы, а именно клиент-серверной архитектуры. Обработчик на бекенде, по своей сути, это функция которая либо меняет состояние (что не приводит ни к каким перерисовкам, так как выполняется редирект), либо извлекает данные из базы для формирования ответа, например, в виде HTML. Во фронтенде изменение данных тут же влияет на экран.
Пример который мы видим выше очень упрощен, в нем вызывается только одна функция render принимающая на вход все состояние. Теперь представьте что у нас в приложении десятки обработчиков (что немного) и большое состояние (что типично). В такой ситуации перерисовывать все на каждое изменение довольно затратная операция. С другой стороны, можно вставить проверку внутри render на каждый кусок стейта и отслеживать изменился ли он. Такой подход очень быстро станет проблемой сам по себе. Можно легко забыть что-то проверить, можно ошибиться в проверке, можно, просто, забыть поправить проверку после изменения структуры состояния.
Существует другой способ выполнить эту задачу. Он основан на такой концепции (говорят шаблон проектирования), как Наблюдатель (Observer). Его идея очень проста, одна часть системы наблюдает за изменением другой части системы. Если наблюдаемый изменился, то наблюдатель может сделать что-то полезное.
В JS подобный механизм можно реализовать через Proxy, но это довольно муторно. Более простым решением будет использование готовой библиотеки Watch.js.
import { watch } from 'melanke-watchjs';
const state = {
value: "hello",
};
watch(state, 'value', () => alert('value changed!'));
// После изменения аттрибута возникнет алерт
state.value = 'other value';
Watch.js позволяет “слушать” нужные части состояния и вызывать функции рендеринга при их изменении.
https://codepen.io/hexlet/pen/dqdJmg
Теперь, обработчики ничего не знают про рендеринг и отвечают только за взаимодействие с состоянием. В свою очередь рендеринг следит за состоянием и меняет дом только там где нужно и так как нужно. Этот способ организации приложения считается уже классическим и носит имя MVC (Model View Controller). Каждое слово обозначает слой приложения со своей зоной ответственности. Model - состояние приложения и бизнес-логика, View - слой отвечающий за взаимодействие с DOM, Controller - обработчики.
Обратите внимание на то что Model, Controller или View это не файлы, не классы, ни что-либо еще конкретное. Это логические слои, которые выполняют свою задачу и определенным образом взаимодействуют друг с другом.
Понимание MVC дает ответ на то как структурировать приложение, но самостоятельно его реализуют редко. Современные фреймворки построены на различных модификациях MVC и за нас определили правила взаимодействия. Остается только разобраться и следовать им.