Хотя модуль http и дает нам возможность писать веб-приложения, этот способ нельзя назвать удобным. Сильно помешает отсутствие роутинга и удобных механизмов расширения функциональности. И это мы еще не копнули вглубь.
Разработка веб-приложений это, в основном, стандартный процесс с понятным набором “хотелок”, многие из которых будут пройдены в рамках данного курса. Центральной частью проекта курса является микрофреймворк express .
import Express from 'express';
const app = new Express();
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!');
});
Удивительное дело: курсы, которые вы прошли до этого, гораздо сложнее для понимания и освоения, чем курсы по конкретным инструментам, таким как express . И, скорее всего, тенденция будет продолжаться. Связано это с тем, что умение программировать требует от вас хорошо развитого computation thinking (вычислительного мышления), включающего в себя много пунктов, помимо абстрактного и логического мышления. А работа с конкретным инструментарием больше похожа на монотонный труд в стиле “делай раз, делай два”. Вся сложность в инструментах, обычно, сосредоточена в количестве используемых концепций. Поэтому для новичков документация по express может показаться нереально сложной без шансов на понимание. Как вы скоро убедитесь, это дело наживное, и к концу курса вы сможете уверенно ориентироваться в возможностях фреймворка и сможете создавать свои приложения уже совсем по взрослому.
Фреймворк
Программная платформа, определяющая способ структурирования кода приложения
Фреймворк противопоставляют понятию библиотека. С библиотеками мы уже хорошо знакомы и писали их не раз. В программировании библиотека это код, который может быть использован в программном продукте для выполнения различных подзадач, важно, что при этом библиотека не влияет на архитектуру приложения и не накладывает на нее ограничений.
Фреймворк это, как ни странно, тоже код, который диктует правила построения архитектуры приложения, задавая на начальном этапе разработки поведение по умолчанию — “каркас”, который нужно будет расширять и изменять согласно указанным требованиям.
Может показаться, что фреймворк — это штука, которая только мешает, но это не так. Большинство приложений укладывается в некоторые стандартные рамки, соблюдая которые можно автоматизировать очень много задач и писать намного меньше кода. А еще это возможность создавать и переиспользовать библиотеки, ориентированные на работу с фреймворками. В современном мире популярный каркас идет в нагрузку с сотнями полезных расширений, которые за вас делают все, что только можно вообразить, за пивом только не ходят.
Микрофреймворк
Устоявшееся название для минималистичных веб-фреймворков.
- Представляет из себя набор
middlewares(описываются позже) - Определяет прямую связь между маршрутом и обработчиком
- Не определяет файловую структуру
- Содержит минимальное количество встроенных возможностей
// HTTP Verb + Route + Handler.
app.get('/', (req, res) => {
res.send('Hello World!');
});
Express как раз относится к классу микрофреймворков. Очень популярное направление, родоначальником которого считается Sinatra , Ruby-микрофреймворк, появившийся в далеком 2007 году. С тех пор в каждом языке появились десятки подобных решений, среди которых есть минимум один-два очень популярных. Получается, что зная express вам будет несложно начать работать с подобным микрофреймворком на любом другом языке.
Проект
Поскольку мы метим в веб-разработчики, то будет грехом не написать свой блог  В процессе создания блога мы рассмотрим следующие темы:
В процессе создания блога мы рассмотрим следующие темы:
- Express JS (Middlewares)
- Роутинг
- Логгирование
- Функциональное тестирование
- Шаблонизация
- REST
- Session
- Twitter Bootstrap
- Авторизация/Аутентификация
- Flash
Веб-доступ
В этом курсе, почти в каждом задании будет открыт веб-доступ, через который можно и нужно смотреть на то, что вы сделали. Веб-сервер по умолчанию не запущен. Для запуска наберите make start в терминале, убедитесь, что сервер нормально запустился, и пробуйте пользоваться. Это справедливо для любого задания курса, в котором есть веб-доступ.
JS: Express → Маршруты
Любое приложение на express состоит минимум из трех элементов:
- Создание объекта приложения
- Определение обработчиков маршрутов
- Запуск приложения на определенном порту
import Express from 'express';
const app = new Express();
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!');
});
С первым и последним пунктом все более-менее понятно, а вот обработчики — это уже интересно. Напомню, что микрофреймворки строятся по схеме: http verb + path + callback . В случае express глагол определяется функцией, которая вызывается на объекте app . Например если мы хотим определить маршрут GET / , то для этого необходимо вызывать функцию get и первым параметром передать в нее строку / . Таким же образом нужно поступать для любого другого маршрута. Вот список глаголов, которые нас будут интересовать в процессе этого курса:
// И - Идемпотентный
app.get // И
app.post
app.delete // И
// Полное обновление
app.put // И
// Частичное обновление
app.patch // И
Семантика http подразумевает, что все эти глаголы, за исключением post , являются идемпотентными. Это должно обеспечиваться программистом, который реализует обработчики.
Динамические маршруты
Самая главная и мощная функциональность системы роутинга — это работа с динамическими маршрутами.
Route path: /users/:userId/books/:id
Request URL: http://localhost:3000/users/34/books/8989
req.params: { "userId": "34", "id": "8989" }
app.get('/users/:userId/books/:id', (req, res) => {
const { userId, id } = req.params;
});
Для динамических частей используется заполнитель :name , который состоит из двоеточия и произвольного имени. Express производит сопоставление актуального запроса со всеми шаблонами в порядке определения и выполняет соответствующие обработчики. Все динамические части маршрута попадают в объект req.params .
Кроме этого, express позволяет использовать регулярные выражения прямо в шаблоне:
// abcd, abxcd, abRANDOMcd, ab123cd
app.get('/ab*cd', (req, res) => {
res.send('ab*cd');
});
Честно говоря, за свой многолетний опыт я не припомню ситуацию, когда мне это могло понадобится. Всегда, если у вас есть возможность управлять урлами, можно сделать хороший вариант на одних плейсхолдерах (заполнителях), без прямого использования регулярных выражений.
Именованные маршруты
У системы маршрутизации есть еще одна важная задача - генерация ссылок. В стандартной поставке express такого механизма нет. Это приводит к тому, что люди, незнакомые с концепцией, генерируют адреса в html , используя строки. Даже существует специальный термин, который называется хардкодинг, при котором прописываются конкретные значения вместо генерации.
<a href=`/posts/${post.id}`>edit</a>
На любом веб-фреймворке, в любом языке так делать нельзя. Если вы измените свои маршруты, то без полной проверки сайта будет невозможно понять что и где сломалось, ведь все ссылки остались старыми. Кроме помощи при отладке и рефакторинге, такой механизм убирает дублирование и позволяет (работает не всегда) изменять маршруты без необходимости переписывать генерацию адресов в html .
import Express from 'express';
import Router from 'named-routes';
const app = new Express();
const router = new Router();
router.extendExpress(app);
router.registerAppHelpers(app);
app.get('/admin/users/:id', 'admin.user', (req, res, next) => {
//... implementation
// the names can also be accessed here:
const path = app.namedRoutes.build('admin.user', { id: 2 }); // /admin/users/2
// the name of the current route can be found at req.route.name
});
В примере выше был создан именованный маршрут admin.user . Теперь, где-то в другом обработчике можно строить ссылки используя имя маршрута:
app.get('/users', 'users', (req, res, next) => {
const path = app.namedRoutes.build('admin.user', { id: 2 }); // /admin/users/2
// path содержит путь с которым можно сделать что-то полезное
});
Преимущества:
- Если удалится маршрут, то при генерации ссылки мы получим исключение. И тесты его поймают.
- Если изменится маршрут, то везде будут автоматически подставлены новые адреса.
После долгих раздумий я решил, что в этом курсе, все же, мы будем хардкодить ссылки. Это связано с тем, что использование соответствующего механизма в express сильно меняет стандартные интерфейсы, а цель этого курса изучить чистые концепции. В реальной жизни используйте соответствующие расширения.
Request/Response
Каждый определяемый обработчик принимает на вход два параметра: req и res . В этом смысле, все очень похоже на ситуацию с http модулем с той лишь разницей, что там подобный обработчик один, а здесь на каждый маршрут свой. Request и Response предоставляют упрощенный интерфейс. Больше нет необходимости, по крайней мере в простых случаях, пользоваться ими как eventEmitter . На каждую задачу эти объекты предоставляют метод или свойство.
// GET /users?page=3
app.get('/users', (req, res) => {
console.log(req.query); // { page: 3 }
res.status(200);
res.send(users);
// res.json(users);
});
Пройдемся по базовым возможностям:
-
req.queryготовый к обработкеquery string, другими словами вам не придется парсить эти параметры, они уже поступают в виде объекта - Установка статуса работает через метод
res.status(code) - Отправка данных выполняется функцией
res.send(data). Все необходимые заголовки выставляются автоматически - Если необходимо отдавать данные в виде
json, тоexpressпозволяет это делать без использования дополнительных механизмов. Все что нужно сделать это вызвать методres.json(data), и данные будут автоматически сериализованы и отправлены клиенту.
Дополнительные материалы
JS: Express → Тесты
Функциональное тестирование — это тестирование ПО в целях проверки реализуемости функциональных требований, то есть способности ПО в определённых условиях решать задачи, нужные пользователям.
В отношении сайтов такое тестирование можно провести, делая http запросы к соответствующим обработчикам и проверяя их ответ. Чтобы это было возможно, требуется небольшая дисциплина кода. В случае express она выражается в том, что определение приложения отделяется от его запуска.
// src/app.js
import Express from 'express';
const app = new Express();
app.get('/', (req, res) => res.send('hello'));
export default app;
// bin/app
#!/usr/bin/env node
import app from '../src/app';
app.listen(4000);
Такое разделение позволяет библиотекам для тестирования самостоятельно запускать приложение и останавливать его при выполнении запросов. Что, в свою очередь, позволяет легко этими тестами управлять. Вам не придется следить за тем, чтобы поднять сервер или выключить, вы просто будете запускать тесты и проверять результат.
Supertest
Supertest — это библиотека, созданная исключительно с целью проводить функциональное тестирование http интерфейса.
// __tests__/app.test.js
import request from 'supertest';
import app from '../src/app';
test('request', async () => {
const res = await request(app).get('/');
if (res.error) {
throw error;
}
expect(res.status).toBe(200);
});
После выполнения запроса она возвращает response , который содержит параметры ответа, а так же объект error , в случае если произошла ошибка. Все тесты этого курса написаны с помощью данной библиотеки. При этом важно отметить, что эта библиотека не позволяет проверить генерируемый html , поэтому возможны ситуации, при которых ваш http интерфейс работает, а формы на сайте сделаны неправильно, что означает невозможность использования сайта. На данном этапе в бой вступает приемочное тестирование, которое не рассматривается в рамках данного курса.
Superagent
В основе библиотeки supertest лежит другая библиотека - superagent . Именно она позволяет формировать произвольные запросы к серверу.
import request from 'superagent';
const res = await request
.post('/api/pet')
.type('form')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json');
JS: Express → Логирование
Запущенный веб-сервер должен как-то сигнализировать о том, что он работает и принимает запросы. Express по умолчанию этого не делает, и единственное, что хоть немного успокаивает, это то, что запущенный сервер заблокировал терминал. В такой ситуации очень сложно понимать, происходит ли вообще что-то.
Как вы уже догадались, решается это добавлением базового логирования. В сильно урезанном виде такой лог выглядит следующим образом:
[19/Nov/2016:17:30:59 +0000] GET / HTTP/1.1 304 - "-" "Chrome/54.0.2840.71"
[19/Nov/2016:17:30:59 +0000] GET /assets/bootstrap.css HTTP/1.1 304 - "http://localhost:8080/" "Chrome/54.0.2840.71"
[19/Nov/2016:17:30:59 +0000] GET /posts/new HTTP/1.1 200 1076 "http://localhost:8080/" "Chrome/54.0.2840.71"
На запрос каждого ресурса, а одна страница может содержать множество ресурсов, например, картинки или стили, в лог пишется строчка. Строчка состоит из следующих элементов:
- Время запроса
- Параметры: verb, pathname, protocol, response, host, user agent
Возможно и больше, зависит от настроек логера. Главное, что это нужно делать обязательно. Очень сильно помогает в отладке.
Morgan
В javascript особой популярностью пользуется библиотека morgan .
import Express from 'express';
import morgan from 'morgan';
const app = new Express();
const logger = morgan('combined');
app.use(logger);
Использование morgan сводится к, буквально, паре строк. По умолчанию весь вывод идет в stdout , а не в файл. Это не просто удобно, но и правильно. С одной стороны, легко видеть вывод сразу после старта, что удобно при разработке. С другой, в продакшене запуск любых сервисов должен происходить посредством супервизора. Супервизор, в свою очередь, сам занимается централизованным логированием, а от наблюдаемых процессов как раз и требуется вывод в stdout . Это позволяет супервизору перехватывать логи веб-сервера и складывать их в правильное место.
Если вам понадобится по какой-то причине изменить формат лога, то сделать это крайне просто. Достаточно создать логер с указанием формата: morgan(':id :method :url :response-time') . Morgan в поставке идет с набором готовых параметров для логирования. В терминологии библиотеки они называются токенами. Каждый токен — это имя вида :url , и на месте каждого токена в заданном формате появляется значение, соответствующее текущему запросу. Подробнее о том, какие есть токены, можно посмотреть в официальной документации библиотеки. При необходимости вы даже можете создавать свои токены.
JS: Express → Отладка
Настало время серьезно поговорить про отладку. На протяжении многих курсов вы постоянно занимались отладкой, иногда часами, а иногда и днями, не могли понять почему все работает не так как должно работать. Это норма! © В повседневной практике такое случается не редко.
Обычно все еще хуже. Бага произошла на продакшене, и у вас уже нет возможности воспроизвести ситуацию. Чем сложнее система, тем меньше шансов что это возможно. Каким образом отлаживать код в такой ситуации? Здесь мы приходим к главной идее отладки. Правильная отладка — это хорошо настроенное логирование.
Есть общие практики, принятые во всех экосистемах, о которых мы сейчас поговорим. В этой истории немного особняком стоит именно js . Основной способ логирования, принятый в js , идет своим путем, который, на мой взгляд, достаточно неплох.
Классическое логирование выглядит так. Подключается специальная библиотека со следующим интерфейсом:
logger.debug("I'm a debug message!");
logger.info("OMG! Check this window out!");
logger.error("HOLY SHI... no carrier.");
Как правило, вызовы приводят к одному и тому же результату за исключением одного. У них разный уровень логирования. В самом логе вывод будет скорее всего таким:
[debug] I'm a debug message!
[info] OMG! Check this window out!
[error] HOLY SHI... no carrier.
Уровни логирования имеют следующую семантику:
- TRACE - дебаговые сообщения для определения flow
- DEBUG - дебаговые сообщения для определения conditions
- INFO - этапы нормального flow
- WARN - некритичные ошибки (но результат должен быть верным)
- ERR - ошибки, могущие привести к неверному результату
- FATAL - “ща грохнусь!”
Чем ближе к началу списка, тем более подробный (говорят “verbose”) лог. Важно, что в коде присутствуют все уровни, и вызовы проставляются самим программистом на основе его понимания работы программы. А вот дальше, уже во время эксплуатации программы, на уровне конфигурации, задается, какой уровень логирования необходимо поддерживать для данного запуска. Предположим, что стоит уровень info , что типично для production систем. Это значит, что в лог будут выводиться только те строчки, которые предназначены для уровней с info по fatal . Во время разработки уровень обычно debug , на этом уровне выводится много отладочной информации, позволяющей понять как идут и преобразуются данные. А так же по каким частям кода идет flow.
Логи — настолько важная часть всего программного продукта, что существует множество решений для сбора, агрегации, анализа логов, в том числе облачных.
Debug
А теперь забудьте все, что я вам говорил до этого :D. Шутка. Но суровая правда в том, что в js доминирует немного другой подход, что не отрицает возможности комбинирования.
Подход js по сути завязан на конкретную библиотеку, которая предложила нестандартный способ работы.
import debug from 'debug';
const log = debug('http');
const name = 'App';
log('booting %s', name);
// http booting App
Первое, что бросается в глаза, это отсутствие уровней логирования. Второе: перед использованием логера импортируется специальная функция, которая вызывается так debug('http') . Передаваемая строчка представляет из себя namespace . Имя, которое, подобно уровню логирования, отделяет логи друг от друга. В отличие от уровней логирования, неймспейсы не имеют никаких ограничений, их может быть столько, сколько нужно, и называть их можно как угодно. Неймспейсы, по сути, отвечают за некоторую подсистему, по которой мы хотим логировать. На практике это оказывается крайне удобным подходом. Обычно мы примерно понимаем на каком уровне и в какой подсистеме произошла ошибка, и хочется выводить лог (подробный) только по этой подсистеме. В случае использования уровней логирования это сделать невозможно, и приходится выискивать нужные строчки в массе других. С использованием неймспейсов это естественный способ работы.
import debug from 'debug';
const httpRequestLog = debug('http:request');
const rpcLog = debug('rpc');
httpRequestLog('request');
rpcLog('action');
Но это еще не все. Неймспейсы могут быть вложенными. Это тоже крайне полезная фича. Обычно на верхнем уровне каждая библиотека определяет неймспейсом свое имя, а внутри уже идет разделение на конкретные подисистемы. Кроме того, в любой файл можно наимпортировать сколько угодно логов и использовать их в любых комбинациях.
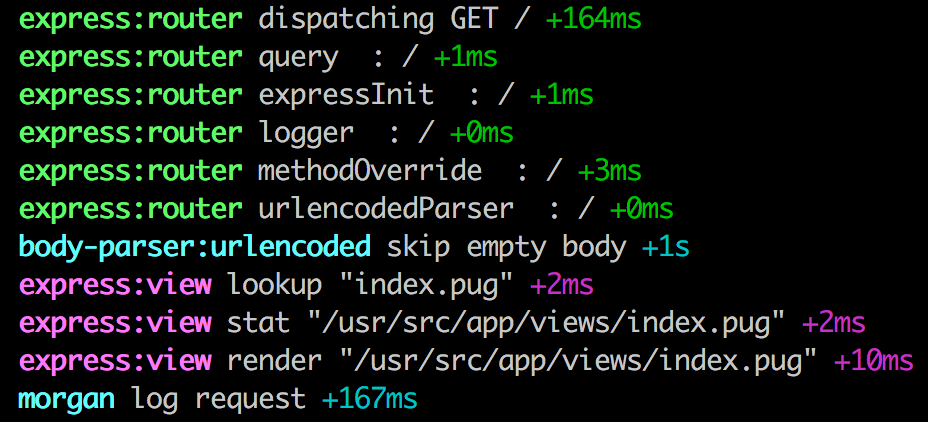
А теперь самое главное. Так сложилось, что 99% самых популярных библиотек на js уже поставляются со встроенным логированием через debug . По сути, нам не очень-то и оставили выбор. На картинке выше как раз видно кусок лога express .
Последний вопрос касается того, как управлять этим выводом. По умолчанию debug ничего не печатает. Чтобы это изменить, нужно передать переменную окружения DEBUG следующим образом:
DEBUG=* bin/server.js
DEBUG=http:* bin/server.js
DEBUG=*,-not-this bin/server.js
Пример демонстрирует три разных варианта использования:
- Вывести все логи (это коснется не только вашего приложения, будут выведены логи всех библиотек входящих в ваше приложение)
- Вывести все логи внутри неймспейса
http - Вывести все логи за исключением
not-thisнеймспейса
JS: Express → Шаблоны
Если проанализировать http запросы к типичному сайту, то можно заметить, что большая часть этих запросов направлена на получение контента, а не его модификацию. Другими словами, основная работа обработчиков состоит в том, чтобы сформировать правильный html и отправить его клиенту (браузеру). Единственный способ для генерации html , с которым мы знакомы, это ручной сбор строчки, содержащей разметку, и отправка посредством метода send .
app.get('/', (req, res) => {
res.send('<div>Hello World!</div>');
});
Сказать, что этот способ плох, это ничего не сказать. Кроме того, что это крайне неудобно, существует масса других недостатков в таком подходе. Если заглянуть в историю развития web, то выяснится интересный факт: php появился как средство решения описанной выше задачи, а не как язык программирования.
Задачу по формированию разметки называют шаблонизацией, а конкретные библиотеки для шаблонизации называют шаблонизаторами. Общий принцип работы такой: описываются файлы с разметкой, а библиотека предоставляет функции для загрузки этих шаблонов в код. Во время загрузки происходят необходимые подстановки и шаблон заполняется конкретными данными.
Jinja Like
Классическим примером может служить шаблонизатор jinja из мира питона. Его популярность привела к тому, что в каждом языке есть множество шаблонизаторов, очень похожих и даже работающих так же, как jinja . Поэтому можно говорить о целом классе jinja-like шаблонизаторов.
<h1 class="header">{{ pagename | title }}</h1>
<div class="small">authors</div>
<ul>
{% for author in authors %}
<li{% if loop.first %} class="first"{% endif %}>
{{ author }}
</li>
{% endfor %}
</ul>
По сути jinja — это хоть и примитивный, но полноценный язык программирования, который вкрапливается в файл с разметкой и расширяет его во время обработки. Несмотря на очевидность этого решения, оно обладает рядом недостатков. Первое — это сложность редактирования такого рода шаблонов. Из-за перемешивания кода с версткой приходится скакать вверх-вниз чтобы добавить/удалить/изменить теги, и тоже самое нужно делать с конструкциями самого языка. Этот недостаток может быть не очевиден тем, кто никогда не видел альтернативных решений, и как мы увидим позже, они есть. Второе: в подобных шаблонизаторах текст вне конструкций шаблонизатора, то есть та самая верстка, никак не анализируется. Это легко приводит к проблемам типа “незакрытый тег”, или семантическому нарушению html , когда неправильно друг в друга вкладываются теги, используются несуществующие атрибуты и тому подобное. И третий немаловажный момент: оформление шаблонов не проверяется автоматическими инструментами, и поэтому стиль будет сильно зависеть от человека.
Pug (Haml Like)
Существует и совершенно другой подход к организации шаблонов. Когда я в первый раз увидел такое, то был немало удивлен. Кажется, что самостоятельно дойти до этого решения очень сложно. Чтобы не томить, сразу покажу пример:
h1.header= pagename
.small authors
ul
each author, index in authors
li(class= index === 0 && "first")= author
Этот пример почти идентичен тому, что было выше с использованием jinja-like шаблонизатора. Обратите внимание насколько чище шаблон во втором примере и на то, что он почти в два раза короче.
История таких шаблонизаторов берет свое начало с haml , руби шаблонизатора, который в мире rails является решением номер один уже очень много лет. После этого оно было скопировано во многие языки, как и jinja . В js мире haml-like шаблонизатор был долгое время известен как jade , и лишь недавно его переименовали в pug .
Попробуем разобраться с основными принципами работы таких шаблонизаторов. Во-первых, это так же язык программирования, но в отличие от jinja-like шаблонизаторов, то что не является кодом, на самом деле не является версткой. Все, что пишется в pug -шаблонах, будет обрабатываться парсером, другими словами, в haml-like шаблонизаторах вы не можете писать все что угодно вне управляющих конструкций. Во-вторых, шаблон строится с помощью особого синтаксиса, который задает теги в виде имен, а вложенность определяется отступом на следующем уровне.
И, с одной стороны, у вас появляется новый язык и новый способ построения html . Что требует некоторого привыкания, но с другой, преимущества оказываются настолько сильными, что человек, распробовавший подобные шаблонизаторы, врядли добровольно вернется на jinja-like библиотеки. Ниже перечислены основные преимущества:
- Шаблон чище и гораздо короче (и Уже)
- Отсутствует проблема незакрытых тегов (т.к. их просто нет)
- Писать и модифицировать такие шаблоны гораздо проще
- Стиль задается грамматикой (писать по разному практически невозможно)
- Шаблоны валидируются, и соответствующая библиотека не даст делать совсем злые вещи
- Вставляемые данные по умолчанию всегда экранируются (привет php!)
Интеграция pug с express выглядит очень просто:
// npm install pug
app.set('view engine', 'pug');
app.get('/', (req, res) => {
const data = { title: 'Hey', message: 'Hello there!' };
res.render('index', data);
})
// index.pug
html
head
title= title
body
h1= message
Все сводится к установке зависимости и установке pug в качестве движка для рендеринга шаблонов. После этого, внутри обработчиков можно начинать использовать метод render . Первый параметр которого - это путь до шаблона, второй - набор параметров для подстановок внутри шаблона.
Это не единственный способ передачи параметров в шаблон. В большинстве случаев они передаются именно вторым параметром в render , но иногда возможны ситуации, в которых у нас есть сквозная функциональность, и было бы крайне неудобно прокидывать их в шаблон в каждом обработчике. Реализуется это через установку свойств в объект res.locals , а в шаблоне эти свойства становятся доступны как переменные. Эту особенность мы будем использовать позже, когда начнем работать с сессиями и аутентификацией. Помните, что злоупотреблять этим способом не стоит, явное лучше неявного. Стремитесь к тому, чтобы код был чистый (использовал чистые функции).
Наследование шаблонов
На практике сайт не всегда состоит из уникальных страниц. Обычно меняется только контентная часть, а вокруг одно и тоже. Часть, которая не меняется, принято называть макетом или лейаутом (layout). Это настолько распространенный кейс, что большинство шаблонизаторов поддерживают механизм для выделения лейаутов. В pug он называется наследованием шаблонов. Ниже приведен пример такого наследования.
//- layout.pug
html
head
title My Site - #{title}
block scripts
script(src='/jquery.js')
body
block content
block foot
#footer
p some footer content
//- page-a.pug
extends layout.pug
append scripts
script(src='/pets.js')
block content
h1= title
- const pets = ['cat', 'dog']
each petName in pets
h2= petName
В шаблоне, который мы используем для рендеринга нашей страницы, пишется специальная директива extends ... . В нее передается имя окружающего шаблона, который чаще является макетом. В макете определяется блок (или блоки), в которые будет происходить подстановка кусков шаблона. Далее необходимо в шаблоне (не макете) определить такие же блоки и наполнить их контентом. Синтаксис задания блоков в обоих местах одинаковый, только в одном случае блок не содержит тела, а в другом содержит.
Включения
Так же бывает полезным механизм включения, позволяющий выделять из шаблонов общие части и переиспользовать их.

Чистота
На просторах интернета постоянно спорят о том, что может быть в шаблоне, а чего нет. Что является логикой вывода, а что нет. При этом есть ряд правил, которые объективно нарушать не стоит.
- Ни в коем случае шаблон не должен порождать побочных эффектов. В шаблоне нельзя писать в базу, изменять данные на диске и вообще любым способом пытаться влиять на окружающую среду. Шаблон это исключительно чтение .
- Шаблоны должны быть декларативны, никакой мутации состояний, другими словами, если вы начинаете внутри шаблона вводить переменные и изменять их, то, по сути, шаблон превращается в полноценный скрипт, который вы программируете. Не допускайте этого.
- Использовать логику, влияющую на вывод внутри шаблона — это нормально. Если у вас, с точки зрения
ui, блок показывается по определенному условию, то вы не сможете этого избежать, единственное о чем нужно помнить, это создавать вовремя правильные абстракции (функции) для избежания дублирования, а так же для выделения бизнес-правил.
Перезагрузка кода
В отличие от js кода, express автоматически перечитывает файлы с шаблонами после каждого запроса, другими словами вам не требуется помощь nodemon для рестарта приложения при обновлении шаблонов.
JS: Express → Assets
Сайт — это не только динамически генерируемые страницы, но так же и различные статические файлы (ресурсы), такие как картинки, файлы стилей, шрифты. Раздача статики — это работа, которую на себя берут фреймворки и веб-сервера.
В Express это работает следующим образом. Определяется специальный маршрут, который связывается с обработчиком Express.static(path) . Обработчик в свою очередь принимает на вход путь, по которому он будет просматривать файлы на диске.
import path from 'path';
import Express from 'express';
const app = new Express();
const path = path.join(__dirname, 'public');
app.use('/assets', Express.static(path));
// http://localhost:3000/assets/images/kitten.jpg
// http://localhost:3000/assets/css/style.css
// http://localhost:3000/assets/js/app.js
// http://localhost:3000/assets/images/bg.png
// http://localhost:3000/assets/hello.html
Важно отметить, что указанный маршрут /assets не участвует в поиске файла на диске, другими словами, он используется только для http адресов.
Bootstrap
Представьте себе ситуацию: вы решили сделать сайт любителей игры “Мафия”. И сразу же стало понятно, что вы не представляете себе, как он будет выглядеть. Дизайнер из вас так себе, да и нет времени и возможности делать дизайн самостоятельно, а следовательно, потом его нарезать, верстать и интегрировать в сайт. Современная верстка тоже не самое простое занятие, как может показаться на первый взгляд. Не говоря уже про то, что сверстать сайт так, чтобы он везде выглядел хорошо, еще та история, особенно если под “везде” мы понимаем не только разные браузеры, но и разные устройства, в том числе мобильные. Что делать?
- Заплатить дизайнеру/верстальщику -)
- Попробовать найти готовый сверстанный макет. В целом, это возможно, но чаще всего такие макеты готовят под конкретные cms, что накладывает на них определенный отпечаток. Так же эти макеты практически не расширяемы. Они не позволяют делать больше того, что заложено в них.
Даже если макет будет найден, встает вопрос о том, как оформлять административный интерфейс. И на этом этапе должна появится мысль о том, что неплохо было бы автоматизировать этот процесс. Каждый сайт содержит административный интерфейс, причем все они более-менее одинаковые.
В какой-то момент появилось направление так называемых css фреймворков. Наборы стилей и, возможно, js файлов, которые предоставляют базовые классы для формирования макетов, а так же готовые компоненты для наиболее часто встречающихся задач.
Самым популярным фреймворком является Bootstrap. Более того, Bootstrap является одним из самых популярных проектов на всем гитхабе! Он позволяет очень быстро накидать внешний вид сайта и дает множество механизмов для его кастомизации. Например hexlet.io полностью построен на Bootstrap. Такой подход позволяет нам очень быстро внедрять фичи и не тратить время на цикл дизайна/верстки. И мы почти не пишем своих стилей.
Во всех уроках этого курса в шаблонах используется Bootstrap. С одной стороны, мы хотим показать преимущества его использования на стадии прототипирования. С другой, надеемся на то что вы немного поизучаете его возможности и начнете использовать.
JS: Express → REST
REST это магическая аббревиатура, которую так любят все использовать по любому случаю. Причем, чаще всего, не к месту. Чтобы ее понять, нужно немного отмотать назад и поговорить о том, как все начиналось.
Одним из способов межпроцессной коммуникации (IPC) является удаленный вызов процедур (RPC). Идея этого подхода достаточно проста. В одной программе вызывается функция, которая на самом деле находится на другом компьютере (не всегда, но всегда в другом процессе). Прозрачно для программиста происходит синхронный запрос на удаленный компьютер, а затем результат возвращается в текущее место вызова, другими словами, RPC — это клиент-серверное взаимодействие.
Существует множество технологий и протоколов, построенных на идеях RPC, например soap , json-rpc , xml-rpc , CORBA , D-Bus и другие. Многие из них достаточно сложны в использовании и реализации.
С появлением интернета стали набирать обороты веб-сервисы, сайты, предоставляющие api для взаимодействия с ними. Попытки стандартизировать это взаимодействие привели к тому, что идеи RPC стали применяться и в вебе.
Попробую на примерах раскрыть суть этого подхода с использованием http . Он состоит в том, что определяется единая точка входа в приложение, например, /myapi через которую, как ожидается, будут передаваться команды для управления сервисом. Можем предположить, что в простейшем случае действие определяется ассоциативным массивом из трех значений type , action , data . Посмотрим, как в таком случае будет выглядеть работа с сервисом (обратите внимание, что ниже описаны запросы к сервису со стороны клиента).
// Создать пользователя
const response1 = await axios.post('/myapi', {
type: 'user',
action: 'create',
data: {
nickname: 'malloc',
},
});
// Выполнить рассылку писем
const response2 = await axios.post('/myapi', {
type: 'maillist',
action: 'send',
data: {
id: 244,
},
});
// Удалить проект
const response3 = await axios.post('/myapi', {
type: 'project',
action: 'delete',
data: {
id: 11,
},
});
Как видно из примеров выше, http участвует в процессе только как способ передать данные на сервер. Это и называется транспортный протокол (хотя с точки зрения osi http не является транспортным протоколом, но это не важно, реальная жизнь не всегда совпадает с теоретическими моделями). А сама структура сообщений должна напоминать вам вызовы обычных функций, только расположенных на другом сервисе. В этом и есть вся суть удаленного вызова процедур .
Широко известной и используемой технологией считается SOAP . Навороченный протокол не только для RPC , но и для обмена любыми произвольными сообщениями.
Запрос:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<getProductDetails xmlns="http://warehouse.example.com/ws">
<productID>12345</productID>
</getProductDetails>
</soap:Body>
</soap:Envelope>
Ответ:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<getProductDetailsResponse xmlns="http://warehouse.example.com/ws">
<getProductDetailsResult>
<productID>12345</productID>
<productName>Стакан граненый</productName>
<description>Стакан граненый. 250 мл.</description>
<price>9.95</price>
<currency>
<code>840</code>
<alpha3>USD</alpha3>
<sign>$</sign>
<name>US dollar</name>
<accuracy>2</accuracy>
</currency>
<inStock>true</inStock>
</getProductDetailsResult>
</getProductDetailsResponse>
</soap:Body>
</soap:Envelope>
Принцип точно такой же, как и в примере выше. Структура тела запроса целиком описывает то, что нужно делать, и http к этому никак не причастен, его задача доставить сообщение и вернуть ответ.
Ирония судьбы в том, что изначально SOAP расшифровывался как Simple Object Access Protocol , что являлось прямой противоположностью тому, чем он являлся. Сложность SOAP , многословность, медленная работа — все это привело к тому, что использовать его стали сильно меньше, и современные web приложения часто выбирают REST -like подход.
Перед тем, как перейти к REST , нельзя не упомянуть о хаотичном rpc подходе. Это подход (имя которому я сейчас придумал) уже частично использует http как прикладной протокол, но все так же ориентирован на вызов удаленных процедур, то есть на действия.
Запросы в этом стиле выполняются так:
// URI в этих запросах не идентифицируют ресурсы, они говорят только о действии
axios.post('/removeUser', { id: 5 });
axios.get('/getCountriesCount');
axios.post('/setProjectName', { name: 'new name' });
Его хаотичность выражается в том, что сервисы, построенные таким образом, не используют никаких стандартных реализаций, а все придумали самостоятельно. Что плохо со всех сторон. Во-первых, вы не сможете использовать стандартные библиотеки для популярных решений, во-вторых, вам придется изучать особенности поведения, которые, к тому же, будут несогласованными (неконсистентными).
Representational State Transfer (REST)
Термин “REST” был введён Роем Филдингом, одним из создателей протокола “HTTP”, лишь в 2000 году. В своей диссертации “Архитектурные стили и дизайн сетевых программных архитектур” (“Architectural Styles and the Design of Network-based Software Architectures”) в Калифорнийском университете в Ирвайне он подвёл теоретическую основу под способ взаимодействия клиентов и серверов во Всемирной паутине, абстрагировав его и назвав “передачей представительного состояния”.
В отличие от веб-сервисов на основе SOAP , не существует “официального” стандарта для RESTful веб-API. Дело в том, что REST является архитектурным стилем (я бы даже сказал набором практик), в то время как SOAP является протоколом.
Чтобы протокол взаимодействия соответствовал REST -стилю, необходимо соблюсти, как минимум, 5 требований. Если сервис соблюдает только часть из них, то про такой протокол говорят, что он REST -like. Если соблюдаются все требования, то протокол является RESTful . На практике, есть ситуации, в которых невозможно следовать REST требованиям, поэтому большинство протоколов являются REST -like, даже если они утверждают другое.
Единообразие интерфейса
- Идентификация. В отличие от
RPC, в котором протоколы ориентированы на действия (глагол), вRESTстиле подразумевается ориентация на ресурсы (существительное). Взаимодействие с каждым ресурсом происходит посредством представлений ресурса, запрашиваемых поURI, который идентифицирует конкретный ресурс. То есть, мы никогда не взаимодействуем с самим ресурсом напрямую, а получаем лишь его представление, которых может быть много. Сервер может отдать данные в форматеjsonилиhtml, хотя при этом ни один из них не является реальным типом хранения внутри сервера. - Манипуляция ресурсами через представление. Если клиент хранит представление ресурса, включая метаданные - он имеет достаточно данных для модификации или удаления ресурса.
- “Самоописываемые” сообщения. Каждое сообщение содержит достаточно информации, чтобы описать каким образом его обрабатывать. К примеру, какой парсер необходимо применить для извлечения данных, может быть описано в Internet медиа-типе, другими словами, посылая на сервер
jsonв телеhttpзапроса,RESTдиктует обязательную установку типа контента в заголовке. В общем случае для обработки сообщения должно быть достаточно информации из самого сообщения (все, что может передаваться поhttp).
По таблице ниже видно, что каждый URI является идентификатором либо одиночного ресурса, либо коллекции ресурсов (это тоже ресурс), а необходимые действия задаются посредством использования подходящего http глагола. И все это должно происходит в строгом соответствии семантике http , другими словами, REST использует то, что заложено в http , а не меняет это или добавляет свое.
| GET | /photos | display a list of all photos |
| GET | /photos/new | return an HTML form for creating a new photo |
| POST | /photos | create a new photo |
| GET | /photos/:id | display a specific photo |
| GET | /photos/:id/edit | return an HTML form for editing a photo |
| PATCH/PUT | /photos/:id | update a specific photo |
| DELETE | /photos/:id | delete a specific photo |
Кэширование
Как и во Всемирной паутине, каждый из клиентов, а также промежуточные узлы между сервером и клиентами могут кэшировать ответы сервера. В каждом запросе клиента должно явно содержаться указание о возможности кэширования ответа и получения ответа из существующего кэша. В свою очередь, ответы могут явно или неявно определяться как кэшируемые или некэшируемые для предотвращения повторного использования клиентами в последующих запросах сохранённой информации. Правильное использование кэширования в REST -архитектуре устраняет избыточные клиент-серверные взаимодействия, что улучшает скорость и расширяемость системы.
Отсутствие состояния
Протокол взаимодействия между клиентом и сервером не сохраняет какого-либо сессионного состояния после запроса и ответа (Stateless protocol). В случае необходимости, такое состояние должно сохраняться на клиенте. Только тогда пользователь отвязан от конкретного сервера, что, в свою очередь, позволяет масштабироваться и безболезненно переносить (балансировать) запросы между серверами.
Примером такого состояния является корзина в интернет магазине. Если она привязана к пользовательской сессии и хранится на конкретном сервере (а не в браузере клиента), то отправить запрос пользователя на другой сервер станет невозможно. Он просто не увидит своей корзины. Эту проблему можно решить двумя способами. Первый - хранить ее на клиенте используя, например, cookie. Вторая - изменением способа хранения корзины на сервере и помещением ее в базу данных, которая доступна со всех серверов.
На практике сайты активно используют понятие “сессии”, при котором данные могут храниться на стороне сервера, что является нарушением REST .
Клиент-серверная архитектура
Разграничение потребностей является принципом, лежащим в основе данного накладываемого ограничения. Отделяя потребности интерфейса клиента от потребностей сервера, хранящего данные, повышается переносимость кода клиентского интерфейса на другие платформы, а упрощая серверную часть, улучшается масштабируемость.
Слои
Клиент может взаимодействовать не напрямую с сервером, а через промежуточные узлы (слои). При этом клиент может не знать об их существовании, за исключением случаев передачи конфиденциальной информации. Промежуточные серверы выполняют балансировку нагрузки и могут использовать дополнительное кэширование.
Код по требованию (необязательное ограничение)
REST может позволить расширить функциональность клиента за счёт загрузки кода с сервера в виде апплетов или сценариев. Филдинг утверждает, что дополнительное ограничение позволяет проектировать архитектуру, поддерживающую желаемую функциональность в общем случае, но возможно за исключением некоторых контекстов.
Преимущества REST
Филдинг указывал, что приложения, не соответствующие приведённым условиям, не могут называться REST-приложениями. Если же все условия соблюдены, то, по его мнению, приложение получит следующие преимущества:
- Надёжность (за счёт отсутствия необходимости сохранять информацию о состоянии клиента, которая может быть утеряна)
- Производительность (за счёт использования кэша)
- Масштабируемость
- Прозрачность системы взаимодействия (особенно необходимая для приложений обслуживания сети)
- Простота интерфейсов
- Портативность компонентов
- Лёгкость внесения изменений
- Способность эволюционировать, приспосабливаясь к новым требованиям (на примере Всемирной паутины)
По-простому
Грубо говоря, REST это набор рекомендаций о том, как лучше сделать для получения преимуществ, описанных абзацем выше. Чем больше рекомендаций вы выполните, тем более REST получается приложение. А поскольку жизнь сложна, то это нормально, что REST ориентированными сервисы являются только отчасти. Использования REST как догмы ни к чему хорошему не приведет. И REST никоим образом не заменяет собой rpc . Выбор решения зависит от ситуации и предъявляемых требований.
JSONAPI
Хотя REST и выглядит хорошо, он все же слишком далек от конкретных реализаций и описывает только фундаментальные аспекты взаимодействия. Конкретные способы организации урлов, передаваемые данные, поведение в случае ошибок и многое другое, придется продумывать самостоятельно.
Есть и другой путь. В 2013 году появился стандарт под названием jsonapi, в котором очень подробно описано как создавать REST -like сервисы. Для его реализации написано множество библиотек под все популярные языки программирования. Как минимум, я рекомендую с ним ознакомиться, а еще лучше - взять на вооружение. Использование открытых стандартов в промышленном программировании делает нашу жизнь проще, бизнес богаче, а волосы шелковистее.
JS: Express → Middlewares
До сих пор мы пользовались фреймворком express как черным ящиком. Что, кстати, характеризует его как хорошую абстракцию. Но помимо очевидного внешнего поведения у микрофреймворков есть еще одно интересное сходство. Давайте зададим себе вопрос: какими качествами должен обладать хороший фреймворк?
Самое очевидное и важное — это концептуальный дизайн, который определяет то, с какими абстракциями мы имеем дело. Бывают фреймворки, в которых абстракции не очень удачные, и разработка на нем обрастает случайной сложностью . С другой стороны, в вебе более-менее выработан единый подход к организации серверных фреймворков. Доминирующей является архитектура MVC , с которой мы и работаем. Controller - контроллеры это наши обработчики, View - это шаблоны, а Model - это наши сущности и бизнес-логика.
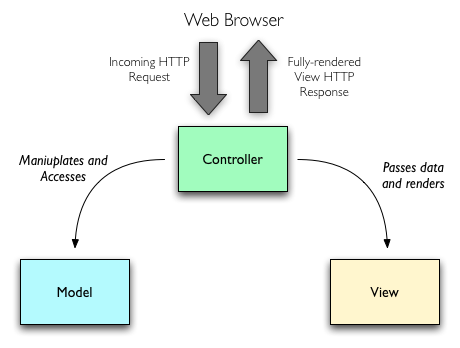
Замечание. Исторически MVC, который принят в вебе, сильно отличается от первоначального MVC, основное применение которого было толстые клиенты. В литературе можно встретить обозначение “MVC v2” для веб версии.
Если предположить, что с дизайном все в порядке, то на сцену выходят более утилитарные качества:
- Гибкость
- Расширяемость
- Модульность
В этом месте мы поговорим о расширяемости, которая в свою очередь приводит к модульности. Рассмотрим самый простой пример - функции. Как можно расширить поведение функции?
Wrapping
const f1 = x => x + 5;
const f2 = x => f1(x * 2);
const f3 = x => f2(x - 10) - 3;
f3(20); // ((((20 - 10) * 2) + 5) - 3) = 22
const nextF = (/* args */) => {
// preprocessing
const result = prevF(/* updatedArgs */);
// afterprocessing
return /* newResult */;
};
Нет ничего проще, чем расширять поведение функции. Нужно написать новую функцию, в которой используется первоначальная. Единственное условие, которое нужно соблюсти, это совпадение входов этих функций (количество и тип аргументов) и выходов (тип выхода). В таком случае код, использующий вашу обернутую функцию, даже не сможет догадаться о том, что она обернута, ну а главное, что его не нужно переписывать, ведь интерфейс функции не поменялся, хотя и появилось новое поведение. Такой способ так же называют декорированием, и в справочниках по шаблонам проектирования описывают как “паттерн декоратор”.
По похожей идее устроен express , а точнее connect , который является ядром микрофреймворка express .
Connect
import Connect from 'connect';
const app = new Connect();
const logger = morgan('combined');
app.use(methodOverride('_method'));
app.use(logger);
app.use(bodyParser.urlencoded({ extended: false }));
// respond to all requests
app.use((req, res) => {
res.end('Hello from Connect!');
});
Middleware
Connect представляет из себя механизм, который расширяется функциями, называемыми middleware . Каждый раз, когда мы используем use , очередная middleware добавляется в общую очередь. В конечном счете получается объект, наполненный мидлварами. Каждый запрос, отправляемый на обработку в connect , проходит через цепочку этих middleware пока не наткнется на терминальную мидлвару.
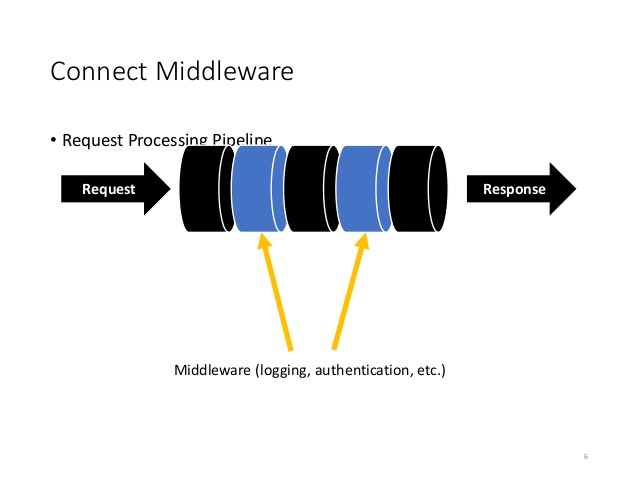
В свою очередь каждая мидлвара принимает на вход три параметра: request , response и next . Она может поменять их и в конце должна вызвать next для передачи управления следующей по списку мидлваре. В этом и заключается вся мощь микрофреймворков. Удачный дизайн позволяет легко разбивать систему на модули-мидлвары и расширять за счет мидлвар, которые, в большом количестве, пишут сторонние разработчики.
app.use((req, res, next) => {
req.newProperty = 'hello from my middleware';
next();
});
// вызов methodOverride возвращает функцию вида (req, res, next) => ...
app.use(methodOverride('_method'));
В Connect нет ничего кроме метода use добавляющего очередную мидлвару в стек.
Mount middleware
Самое интересное в Connect, что обработчики конкретных маршрутов — это тоже, всего навсего, мидлвары. Их особенностью является привязка к конкретному маршруту, в отличие от мидлвар, которые выполняются для всех запросов.
app.use('/foo', (req, res, next) => {
// req.url starts with "/foo"
next();
});
app.use('/bar', (req, res, next) => {
// req.url starts with "/bar"
next();
});
Такие мидлвары позволяют реализовывать базовый роутинг без привязки к конкретному глаголу http и без поддержки динамических маршрутов. В Express роутинг реализован без привязки к Mount Middlewares.
Terminate
Но далеко не всегда мы хотим двигаться вглубь. Боле того, в какой-то момент одна из мидлвар должна взять обработку на себя.
// connect
app.use((req, res) => {
res.end('Hello from Connect!');
});
// express
app.use((req, res) => {
res.send('Hello from Express!');
});
У такого поведения, когда есть цепочка функций и любая из них в процессе обработки может принять решение остановки цепочки и возврата ответа, есть имя. Такие цепочки называют chain responsibility , и это тоже паттерн.
Дополнительные материалы
JS: Express → Ошибки
Разговор о мидлварах был бы не полным, если бы мы не обсудили обработку ошибок. Если запрашиваемый урл соответствует одному из определенных маршрутов express , то вызывается соответствующий обработчик (как теперь мы знаем мидлвара). Но ведь к сайтам можно обращаться по любому адресу, даже такому, который в роутинге не описан. С точки зрения http такая ситуация должна приводить к ошибке 404 и, возможно, ответом будет специальная страница.
Для реализации подобного поведения не нужны специальные механизмы. Все, что нужно для этого, мы уже изучили. Если хорошо подумать, то можно дойти до мысли, что 404 — это ситуация, при которой express не смог сопоставить ни один маршрут с запрошенным адресом, а значит мы можем определить мидлвару после определения всех маршрутов. Эта мидлвара и будет обработчиком ситуации 404 .
app.get('/', (req, res) => {
res.send('hello');
});
app.use((req, res) => {
res.status(404);
res.render('404');
});
С этой точки зрения все отлично, но часто возникает потребность вернуть ответ 404 даже в том случае, если маршрут был найден. Такое происходит, например, при обращении к удаленному/несуществующему ресурсу: /users/5 .
app.get('/posts/:id', (req, res) => {
const post = posts.find(post =>
post.id.toString() === req.params.id);
if (post) {
res.render('posts/show', { post });
} else {
// ?
}
});
Интуиция подсказывает нам, что мы должны каким-то образом передать управление дальше, но не следующей по списку мидлваре, а мидлваре, отвечающей за ошибки. И это, действительно, делается так:
// regular middleware
app.use((req, res, next) => {
// i had an error
next(new Error('boom!'));
});
В данном примере, в отличие от всего, что мы видели раньше, в next передается ошибка. Это приводит к изменению поведения вызова последующих мидлвар. Все обычные мидлвары будут пропущены, а те, которые предназначены для обработки ошибок, будут вызваны.
// error middleware for errors that occurred in middleware
// declared before this
app.use((err, req, res, next) => {
// an error occurred!
});
Мидлвары для обработки ошибок отличаются от обычных тем, что они принимают на вход четыре параметра, а первый, при этом — ошибка, полученная от предыдущей мидлвары. Expess сам внутри себя определяет, что это мидлвара для обработки ошибок. Делается это посредством проверки количества аргументов у функции после вызова use . Кстати, этот прием называется “метапрограммирование”, когда программа пользуется информацией о самой себе для принятия решений.
JS: Express → Сессии
В информатике, а конкретно в сетях, сессия — это интерактивный обмен информацией, так же известный, как диалог между двумя или более общающимися устройствами, или между компьютером и пользователем. Сессия (cеанс) устанавливается в определенный момент времени и позже завершается.
HTTP session
Так как HTTP — это клиент-серверный протокол, HTTP сессия состоит из трёх фаз:
- Клиент устанавливает TCP соединение (или другое соединение, если не используется TCP транспорт).
- Клиент отправляет запрос и ждёт ответа.
- Сервер обрабатывает запрос и посылает ответ, в котором содержится код статуса и соответствующие данные.
Начиная с версии HTTP/1.1, после третьей фазы соединение не закрывается, так как клиенту позволяется инициировать другой запрос. То есть, вторая и третья фазы могут повторяться.
User session
Пользовательская сессия является более высокоуровневой абстракцией, чем HTTP-сессия. С помощью нее можно не только идентифицировать разных пользователей, но также хранить произвольные данные на каждого пользователя в рамках его сессии. Типичный пример это корзина товаров в интернет-магазине. Обратите внимание на то, что для пользовательской сессии не обязательно логиниться (выполнять аутентификацию) на сайте.
Поддержка сессий обычно реализуется с помощью специальных библиотек в рамках используемого фреймворка. В задачи этих библиотек входит:
- Установка соединения, то есть отправка специальной куки, которая содержит идентификатор сессии. Имя этой куки фиксированно и задается на этапе старта приложения.
- Сохранение и извлечение данных из сессии. Этот пункт сильно зависит от используемого фреймворка. В случае
expressпредоставляется специальный объектreq.session, в который можно записывать необходимую информацию и читать ее в следующих запросах. Отдельный интерес представляет хранилище данных сессии. Это можно делать в памяти, прямо в куках (в зашифрованном виде), или в различных серверных хранилищах начиная от файлов, заканчивая базами данных. - Завершение сессии.
import session from 'express-session';
app.use(session({
resave: false,
saveUninitialized: false,
}));
У библиотеки express-session очень много параметров, влияющих на работу сессии, и большое количество дополнений, позволяющих использовать различные хранилища. За подробностями обращайтесь к официальной документации.
К счастью, использовать сессии гораздо проще чем их настраивать.
app.get('/increment', (req, res) => {
req.session.counter = req.session.counter || 0;
req.session.counter += 1;
});
В примере выше в сессии инициализируется свойство counter значением 0 , а затем, при каждом обновлении страницы, счетчик увеличивается на единицу. Это будет происходить для каждого браузера независимо, потому что кука устанавливается в браузер, и браузер является “пользователем”.
Для удаления сессии нужно вызывать асинхронный метод destroy .
req.session.destroy(err => {
// cannot access session here
})
Аутентификация
Аутентификация это процедура проверки подлинности, например:
- Проверка подлинности пользователя путём сравнения введённого им пароля с паролем, сохранённым в базе данных пользователей
- Подтверждение подлинности электронного письма путём проверки цифровой подписи письма по открытому ключу отправителя
- Проверка контрольной суммы файла на соответствие сумме, заявленной автором этого файла
Аутентификацию не следует путать с авторизацией (процедурой предоставления субъекту определённых прав) и идентификацией (процедурой распознавания субъекта по его идентификатору).
Вот как может выглядеть процесс аутентификации в express :
app.post('/session', (req, res) => {
// ...
if (user.passwordDigest === encrypt(password)) {
req.session.userId = user.id;
// ...
}
// ...
});
При совпадении паролей в сессию устанавливается идентификатор пользователя под ключем, который потом будет использоваться для проверки, аутентифицирован ли пользователь.
Обратите внимание на то, что в примере выше используется не сам пароль, а его хешированная версия. С точки зрения безопасности ни в коем случае нельзя хранить пароли в открытом виде. Поэтому при создании пользователя пароль специальным образом хешируется, и в хранилище уже сохраняется этот хеш. Во время процедуры аутентификации пароль, вводимый пользователем, хешируется тем же способом, что и при регистрации, а затем происходит сравнение хешей.
// encrypt.js
import crypto from 'crypto';
export default text => {
const hash = crypto.createHmac('sha512', 'salt');
hash.update(text);
return hash.digest('hex');
};
JS: Express → Авторизация
Авторизация - это предоставление определённому лицу или группе лиц прав на выполнение определённых действий; а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Ситуация, в которой термины используются неправильно, довольно распространена. Авторизация относится к списку таких терминов. Обычно ей называют аутентификацию. Об этом всегда стоит помнить, но мир (как минимум русскоязычный) уже не изменить.
Рассмотрим простой пример с использованием авторизации, удаление поста.
app.delete('/posts/:id', (req, res, next) => {
if (res.locals.currentUser.isGuest()) {
const error = new AccessDeniedError();
return next(error);
}
state.posts = state.posts.filter(post =>
!(post.id.toString() === req.params.id));
res.redirect('/posts');
});
Удалить пост может только залогиненный пользователь. Все остальные (гости) должны получить в ответ 403 forbidden , код, который означает, что произошел отказ в доступе. В более сложных случаях нужно проверять, что пост может удалить только его автор. Любой сайт, сложнее чем сайт-визитка, содержит в себе множество проверок на допустимость тех или иных действий, что может привести к очень большому дублированию проверок по всем обработчикам. Разберем, как этого можно избежать.
Route Middlewares
// a middleware sub-stack shows request info for any
// type of HTTP request to the /user/:id path
router.use('/user/:id', (req, res, next) => {
console.log('Request URL:', req.originalUrl);
next();
}, (req, res, next) => {
console.log('Request Type:', req.method);
next();
});
Express позволяет указывать любое количество мидлвар для одного и того же маршрута. Для этого можно передать любое количество аргументов (являющихся мидлварами) в функцию use . Этим фактом мы и воспользуемся.
const requiredAuth = (req, res, next) => {
if (res.locals.currentUser.isGuest()) {
return next(new AccessDeniedError());
}
next();
};
app.delete('/posts/:id', requiredAuth, (req, res) => {
state.posts = state.posts.filter(post =>
!(post.id.toString() === req.params.id));
res.redirect('/posts');
});
В примере выше определена мидлвара requiredAuth , которую можно подключать к любому маршруту. Она проверяет, залогинен ли пользователь или нет, если нет, то дальше по цепочке передается ошибка. Как мы уже знаем, это приводит к тому, что начинают выполняться только мидлвары, обрабатывающие ошибки. Этот механизм полезен не только для контроля доступа, таким образом можно выполнять любые подготовительные действия, которые используются разными маршрутами.
JS: Express → Flash
В веб-фреймворках есть один очень простой и полезный механизм, который называется flash . Этот механизм не имеет ничего общего с технологией flash , как можно было бы подумать. Он используется в ситуациях, когда пользователя надо оповестить об успешном/не успешном выполнении какого-либо действия, например, после аутентификации показать сообщение “Вы вошли!”. Такая задача возникает, почти всегда, после отправки форм на сайте.
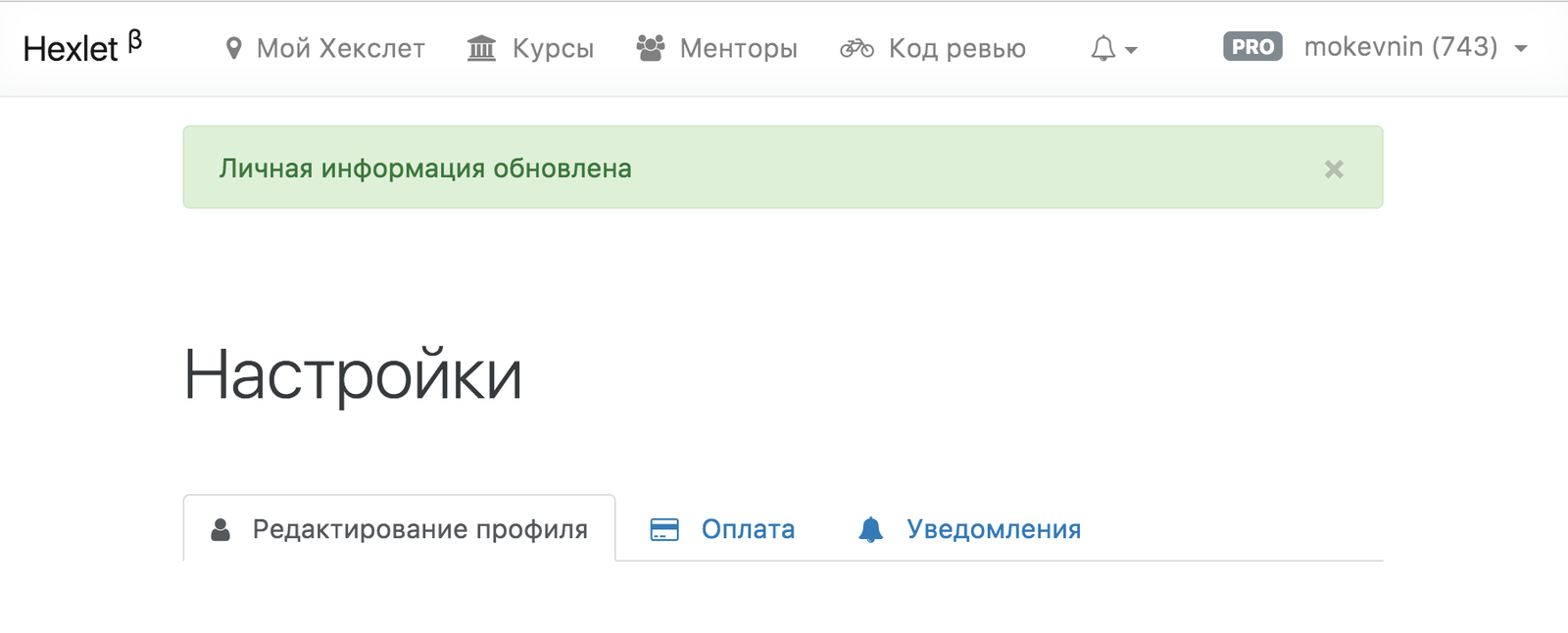
Особенность этого механизма в том, что он должен запомнить сообщение в рамках одного запроса, а вывести его на другой http запрос, обычно это связано с редиректом после выполнения какой-либо операции пользователем. Например, если мы регистрируемся, то создание флеш сообщения происходит в момент POST /users , а вывод уже после редиректа на главную страницу. Способ, который для этого используется - записать данные в сессию пользователя, для того чтобы извлечь их при следующем запросе.
app.delete('/session', (req, res) => {
res.flash('info', `Good bye`);
delete req.session.nickname;
res.redirect('/');
});
Обратите внимание что потенциально можно вызывать функцию flash много раз.
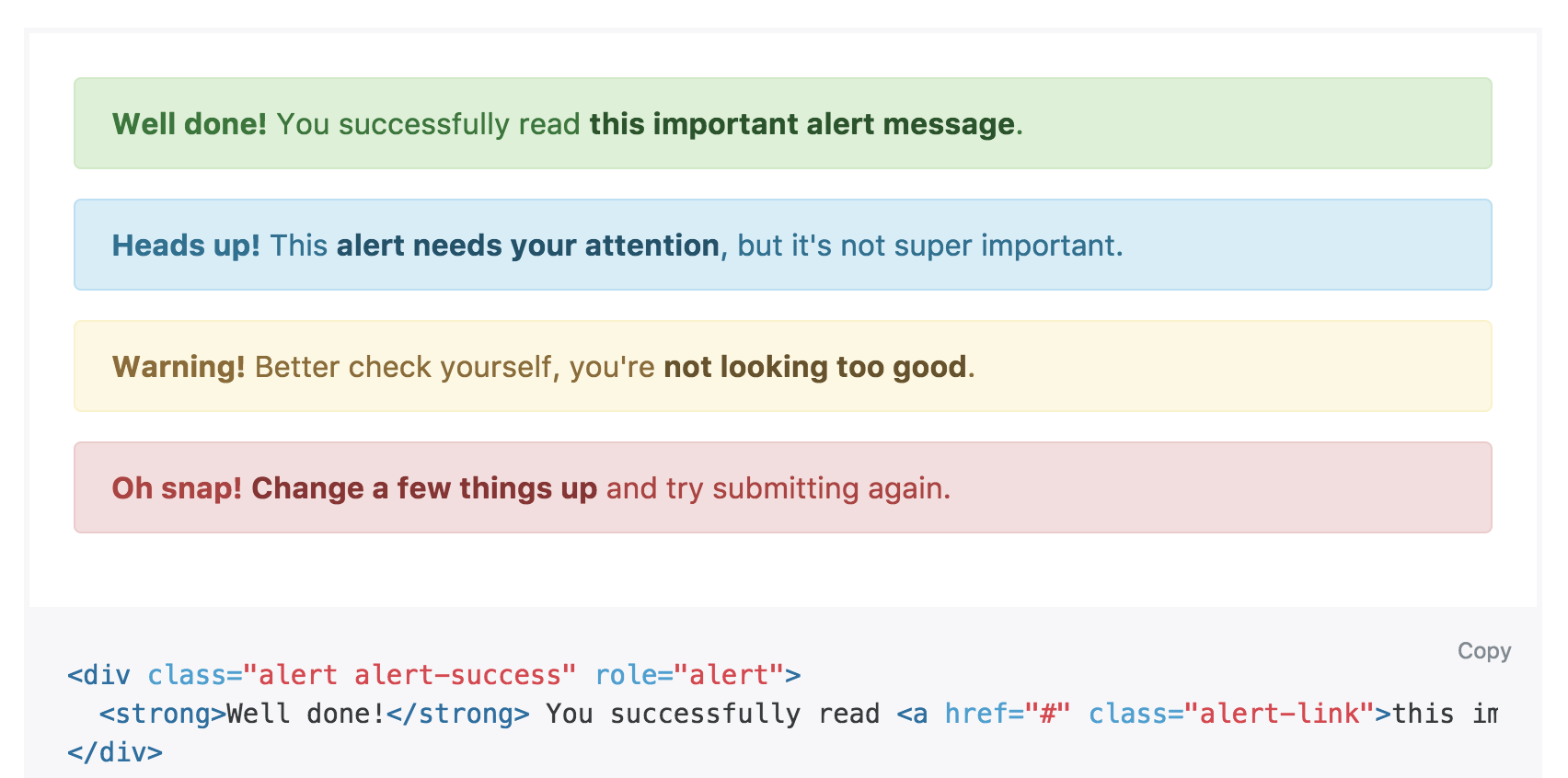
Обычно флеш сообщения делят на уровни: info , success , warning , которые при выводе различаются цветовой схемой, чтобы обозначать и разделять типы сообщений.
Ниже приведен пример подключения соответствующей библиотеки и вывод сообщений в шаблоне:
// npm: flash
import flash from 'flash';
app.use(flash());
for message in flash
.alert(class=`alert-${message.type}`)
= message.message
На сайте Хекслета можно увидеть множество таких флеш сообщений в разных местах. Внешний вид и типы сообщений целиком взяты из Bootstrap.