Обычно во вступлении мы рассказываем то, что ожидает вас внутри курса, но здесь я решил рассказать кое-что важное. Попробуйте самостоятельно ответить на вопрос. Какая основная задача программиста?
Вероятно, вы ответите “писать код” и будете не правы. Писать код это всего лишь средство, причем не единственное. Так же, часто решением задачи является удаление кода или, вообще, отсутствие кода, и все это тоже область компетенции программиста.
Начать нужно с того, что программирование, как таковое, это не цель, это всего лишь средство достижения бизнес целей той компании, которая вас нанимает. В конечном итоге все программное обеспечение так или иначе служит удовлетворению потребностям бизнеса: увеличению прибыли, снижению издержек. Хорошая статья об этом есть в нашем блоге.
На практике это означает очень простую вещь, перед тем как бросаться писать код, нужно понять цель того, что вам нужно сделать. Хочу еще раз акцентировать ваше внимание, на том, что цель это зачем мы это делаем, а не что нужно сделать. У меня есть хорошая аналогия, которую мы постоянно наблюдаем в своей жизни. Вспомните приходы к доктору. Многие люди пытаются рассказывать доктору не только симптомы, но и выдвигают гипотезы, а некоторые прямо утверждают, что у них конкретная болезнь и, более того, они знают как лечиться. Доктора, обычно, пропускают это мимо ушей, потому что его задача понять истинную причину. Тоже самое часто происходит в разработке. К вам приходит заказчик и говорит что нужно сделать. Например: “Вася, добавь две колонки в базу”. Возникает парадоксальная ситуация, чем более технически подкован заказчик тем, как правило, он больше пытается продавливать конкретные решения, вместо того, чтобы описывать свою бизнес задачу (цель), оставляя вам маневр для решения.
Избежать этого невозможно, никто и никогда не будет давать идеальных задач, которые созданы исходя из бизнес-целей. Такое, конечно же, бывает, но гораздо реже, чем вам может показаться. В итоге бизнес-аналитикой занимается разработчик (кроме сложных случаев) и это нормально. Докопавшись до сути, может оказаться так, что кода писать не надо вообще и достаточно поменять правила игры.
Дальше по курсу мы будем исходить из того, что все цели уже определены и нужно именно писать код, но перед тем, как мы двинемся дальше, я расскажу о том, как смотреть на мир глазами бизнеса и почему это полезно.
Подумайте вот о чем. Откуда бизнес узнает что нужно делать? Работая на дядю может сложиться впечатление что там наверху умные люди, которые знают, что делают. На самом деле они не знают. Представьте, что вы начинаете с нуля свой стартап. После непродолжительного анализа станет понятно, что основная сложность не в том, чтобы понять “что делать”, а в том, чтобы понять “что не делать”. На эту тему есть обязательная книга к прочтению, которая поменяет ваше мировоззрение: “Бизнес с нуля. Метод Lean Startup.”
Lean Startup

Не обращайте внимание на слово “стартап” в заголовке, эта методология одинаково хорошо работает и для больших бизнесов и для молодых проектов. Удивительно, но основная идея этого подхода пришла из научного мира и называется “научный метод”:
Нау́чный ме́тод — совокупность основных способов получения новых знаний и методов решения
задач в рамках любой науки.
Метод включает в себя способы исследования феноменов, систематизацию, корректировку новых
и полученных ранее знаний. Умозаключения и выводы делаются с помощью правил и принципов
рассуждения на основе эмпирических (наблюдаемых и измеряемых) данных об объекте. Базой
получения данных являются наблюдения и эксперименты. Для объяснения наблюдаемых фактов
выдвигаются гипотезы и строятся теории, на основании которых в свою очередь строится
математическое описание — модель изучаемого объекта.
Первое. Логика контринтуитивна. Понять, что нужно вашим пользователям заранее и без общения с ними, практически невозможно. Используя lean startup мы выдвигаем гипотезы, а не продумываем конкретные решения. Пример гипотез:
Пользователи хотят заказывать такси без необходимости звонить оператору и диктовать адрес
Пользователю удобнее оплачивать такси с карты чем наличными
Проницательный читатель увидит, что при таком подходе, нет цели реализовать сразу все, от и до продумав все части программы. Задачей станет реализовать только то, что может помочь подтвердить или опровергнуть гипотезу. Ведь если гипотеза не верна, это автоматически означает, что нужно корректировать все дальнейшие планы. В противном случае будут большие потери.
После того, как гипотеза готова, делается все необходимое для ее проверки. Многие гипотезы, по факту, не требуют написания кода вообще. Например гипотеза про удобство оплаты такси картой проверяется звонками друзьям/постами в соц сети. Согласитесь, что это сильно дешевле, проще и быстрее, чем месяцами писать приложение, а потом увидеть, что это никому не нужно.
На выходе получается цепочка: Гипотеза -> Реализация (если нужно) -> Анализ данных. Повторяя эту цепочку снова и снова, мы получаем продукт, который действительно работает и отвечает бизнес целям.
Ключевые слова для самообразования:
- Customer development
- Business Model Canvas
- Minimum Viable Product
- Pivot
SMART
Когда речь идет про уже существующий бизнес или, даже, личные цели, то подойдет такой подход как SMART:
Это мнемоническая аббревиатура, используемая в менеджменте и проектном управлении для
определения целей и постановки задач:
* конкретный (specific);
* измеримый (measurable);
* достижимый (attainable);
* значимый (relevant);
* соотносимый с конкретным сроком (time-bounded)
Этот подход хорошо расписан в вики, поэтому не буду заниматься копипастой.
Impact mapping
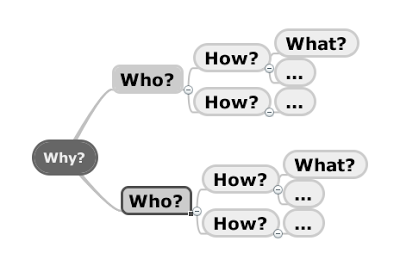
Impact Mapping простая и эффективная техника для определения целей заказчика и передача этих целей разработчикам.
Impact Mapping — это mind map по целям проекта с картой влияний, которые должны подтолкнуть бизнес заказчика к достижению целей.
Why?
Центральный элемент нашей карты, который отвечает на ключевой вопрос: Зачем мы это делаем? Это цель, которую бизнес пытается достичь.
Who?
На первом уровне мы отвечаем на вопросы: Кто поможет достичь желаемого результата? Кто может помешать? Кто пользователи нашего продукта? Сюда войдут все заинтересованные стороны, которые могут повлиять на цели бизнеса.
How?
На втором уровне мы должны описать воздействия, которые должны оказать заинтересованные стороны, чтобы бизнес достиг целей. Мы ищем ответ на вопросы: Как они помогут бизнесу достичь целей? Как они могут помешать успеху проекта?
What?
После ответа на основные вопросы можно обсудить конкретные задачи. Третий уровень отвечает на вопросы: Что мы можем сделать как организация или команда разработки, чтобы создать необходимые воздействия? Здесь будет описан конечный результат нашей работы.
Подробнее об этом подходе можно прочитать в замечательной статье Александра Бындю на хабре.
User Story Mapping
После определения карты влияний на цели можно определить роли пользователей, как они будут взаимодействовать с системой, важность задач, план релизов и т.д.
Цель user story mapping в том, чтобы приоритизировать пользовательские истории по важности.
Пример пользовательской истории:
Я, как сейлз, хочу видеть отчет по интересам клиентов в курсах, для того,
чтобы принять решение о создании нового курса и приглашения этих клиентов принять в нем участие.
Об этой полезной технике можно найти много статей на просторах сети. Подробнее на ней останавливаться не будем, пора переходить к самому курсу).
Проект: Электронная продажа билетов

На протяжении курса мы будем создавать систему для продажи билетов в кинотеатре через интернет. Бизнес-анализ тоже будет присутствовать, но в очень ограниченном варианте. Основной упор на то, как писать код.
Основные темы
По пути разберем много страшных слов, и я понимаю, что многие вещи, о которых будет говориться, вызовут еще больше вопросов, чем ответов. Цель этого курса показать новые горизонты, а не дать всеобъемлющее руководство к действию. Этим курсом ваш путь только начинается.
- Domain-Driven Design
- Entity, Value-Object
- Repository
- Service Layer
- Inversion Of Control
- Dependency Inversion Principle
- Dependency Injection Container
- FSM
Дополнительные темы
В процессе используем множество разных библиотек, таких как:
- bottlejs
- uuid-js/validate.js
- lodash/date-fns
JS: Предметно-ориентированное проектирование → Use cases
Существует очень высокоуровневый способ увидеть возможности проекта с высоты птичьего полета. Это use case диаграмма из стандарта UML.
Unified Modeling Language (UML)
Язык графического описания для объектного моделирования в области разработки программного обеспечения, моделирования бизнес-процессов, системного проектирования и отображения организационных структур.
Мы уже встречались с ним в курсе автоматного программирования, когда использовали диаграмму состояний. UML включает в себя множество различных диаграмм на все случаи жизни. Некоторые из них очень полезны, другие менее. Как минимум, нужно научиться понимать диаграммы на базовом уровне, ведь большинство книг по проектированию так или иначе их используют. Особенно это касается диаграмм классов (все книги по паттернам), последовательностей и других.
Но не советую слишком закапываться, очень легко увлечься и забыть о целях.
Диаграмма последовательностей
В данном примере диаграмма прямо отражает то, как работает код, но так бывает не всегда.
Электронная продажа билетов
На специальном сервисе я накидал диаграмму вариантов использования для нашего проекта. Ниже можно посмотреть на то, что получилось. Правда симпатично?
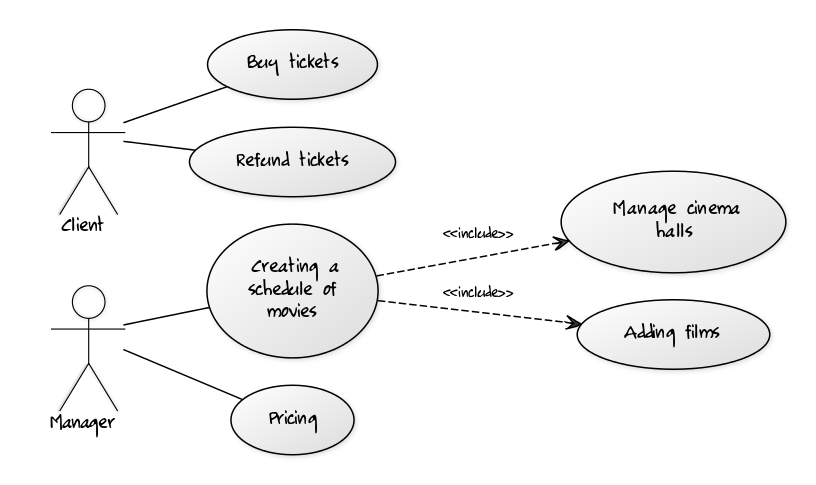
Как видно из картинки, подразумевается, что у нас две роли. Клиент кинотеатра и менеджер. Роль != Человек, то есть менеджеров может быть много, в данном случае это не важно.
Клиент может делать две вещи:
- Купить билет
- Вернуть билет
Менеджер:
- Добавить залы в кинотеатре
- Добавить фильмы
- Добавить показы фильмов
В реальном приложении таких вариантов использования было бы значительно больше. Практика показывает, что даже в этом случае не нужно пытаться их все уместить на диаграмме. Она нужна только для того, чтобы увидеть и понять ключевые возможности системы, а так же познакомиться с действующими лицами.
Бизнес-правила нашей системы продажи билетов очень просты:
Ценообразование
- Цена зависит от типа зала
- Цена зависит от дня недели (повышающий коэффициент в выходные)
–
Возврат билета
- Возвращается полная стоимость покупки
- Можно вернуть только до начала фильма
JS: Предметно-ориентированное проектирование → Сущности и связи
Настал момент, когда нужно начинать проектировать приложение. И делать мы это будет, используя Entity-relationship Model
ERM - Модель данных, позволяющая описывать концептуальные схемы предметной области.
Сущности
Этот подход включает в себя два основных понятия: сущность и связь. Проще всего начать с примеров:
- Пользователь
- Кинозал
- Билет
- Показ фильма
Это сущности нашей предметной области, с которыми предстоит работать в коде. Как видите, понятие сущность довольно интуитивно. Но, так же, оно обладает и рядом формальных характеристик:
- Идентификация
- Время жизни
Идентификация означает, что мы можем рассматривать сущности независимо и выделять одни среди других. Например, у нас есть разные кинозалы, и это разные сущности. Другой пример это пользователи. Даже если два человека имеют одинаковые ФИО, мы все равно сможем их различить на основе дополнительных признаков. В программировании, обычно, сущностям присваивается идентификатор (суррогатный ключ), который и используется для этой цели. Чаще всего эта задача возлагается на базу данных. В нашей ситуации базы нет, поэтому мы будем задавать его самостоятельно.
const user = new User('илон');
console.log(user.id);
// 896b677f-fb14-11e0-b14d-d11ca798dbac
// User.js
import uuid from 'uuid-js';
class User {
constructor(name) {
this.id = uuid.create().toString();
this.name = name;
}
}
Библиотека uuid-js позволяет генерировать уникальный идентификатор, который можно использовать для идентификации. Кстати uuid очень полезная штука, может пригодится в некоторых типах задач.
Время жизни означает, что наша сущность в какой-то момент появилась и когда-то может исчезнуть.
Связи
Между собой, сущности, образуют связи. Например, человек может быть владельцем нескольких машин, но машина может принадлежать только одному человеку. Пользователи хекслета проходят много курсов, каждый курс доступен всем пользователям.
Таким образом можно выделить три основных типа связи: один к одному (o2o), один ко многим (o2m) и многие ко многим (m2m).
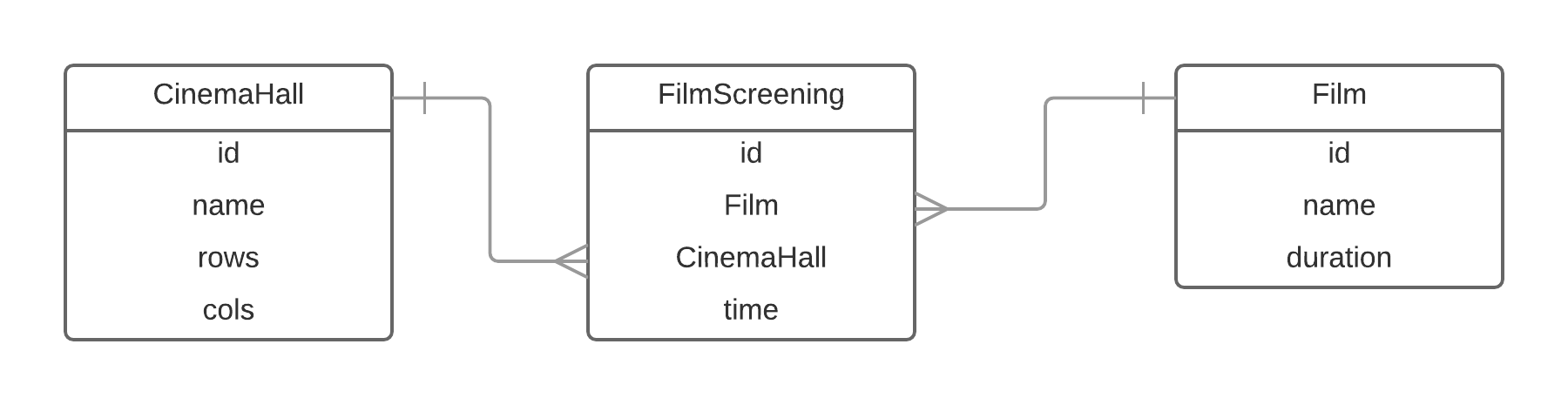
Выше представлена Entity-Relationship диаграмма. Она входит в стандарт UML и неплохо помогает понять то, какие сущности составляют вашу предметную область и как они друг с другом связаны.
Что можно сказать глядя на диаграмму?
- В одном зале может быть много показов фильмов
- Один фильм может быть показан много раз
- Фильмы и залы связаны друг с другом как “многие ко многим”. То есть один фильм показывается в разных залах, а в одном зале идут разные фильмы.
Все это довольно очевидно и соответствует нашему опыту посещения кинозалов. В других предметных областях это уже не так просто, и то, как вы проектируете сущности и их связи, имеет сильное влияние на ваше приложение. Общее правило такое, чем больше связей и чем более они разнообразные, тем сложнее приложение. Часто бывает такое, что программисты “закладываются на будущее” (которое не факт что наступит) и пытаются делать чуть ли не все связи m2m . Чаще всего такой подход оказывается примером over-engineering , другими словами, не надо добавлять сложности там, где нет реальной потребности.
Кроме влияния на логику работы, связи так же сильно влияют на способ хранения сущностей в базе данных. Например, в реляционных базах данных, связь m2m всегда подразумевает наличие промежуточной таблицы. В свою очередь рефакторинг базы данных не такое простое занятие как изменение кода.
Пример
На хекслете есть курсы. Каждый курс состоит из уроков. Урок не может существовать без курса. Вот как может быть представлена эта модель в коде:
const course = new Course('JS: DDD');
const lesson1 = new Lesson(course, 'Введение');
const lesson2 = new Lesson(course, 'Модель Сущность-Связь');
Передача курса в конструктор удобна по двум причинам. Сразу становится видна и понятна связь урока с курсом. А, так же, на уровне языка заложено бизнес-правило, что урок не может существовать без курса.
Объекты-значения (Справочники)
Кроме сущностей в предметной области всегда есть и значения, или, как их обычно называют, объекты-значения. В отличие от сущностей у них нет идентификации. Возьмем такое понятие как деньги (Money). Если мы не являемся казначейством, то нужно ли нам отличать одни 100$ от других 100$ ? Вероятно нет. Для нас не существует сущности 100$ , все, что имеет значение, это номинальная стоимость этих денег, другими словами, в случае объектов-значений сравнение происходит не по идентификации, а на основе фактического значения. Тоже самое применимо ко всем справочным данным. Имена стран (производители фильмов), адреса, список городов и многое другое.
Важно понимать, что это не абсолютная истина. Будет ли какое-то понятие сущностью или значением зависит от конкретной предметной области.
JS: Предметно-ориентированное проектирование → Архитектура
При разработке приложений с богатой предметной областью во весь рост встает вопрос о том, как правильно организовать код приложения, а если смотреть шире, то какую выбрать архитектуру. О том, какие варианты может предложить вам индустрия мы сейчас и поговорим, но перед тем как я расскажу про существующие подходы, важно запомнить несколько вещей.
Не существует единственного верного подхода при организации вашего приложения. Известные подходы - всего лишь видение конкретных людей для конкретных ситуаций и конкретных стеков (язык + инструментарий). Любая хорошая архитектура базируется на фундаментальных законах и принципах. Большую часть из них вы уже знаете:
- Изоляция побочных эффектов
- Хорошая абстракция (абстракция данных, композиция, разделение)
- Сильные барьеры (между абстракциями)
- Слабые связи (возможность замены/независимого развития)
Из популярного можно выделить следующие словосочетания:
- The Clean Architecture
- Onion Architecture
- Hexagonal Architecture
Все эти архитектуры сводятся так или иначе к тому, что наше приложение представляет из себя набор слоев (тех самых абстракций), которые связаны друг с другом определенным образом и отвечают за определенные аспекты системы. Лучше всего начать анализ с красивой картинки:
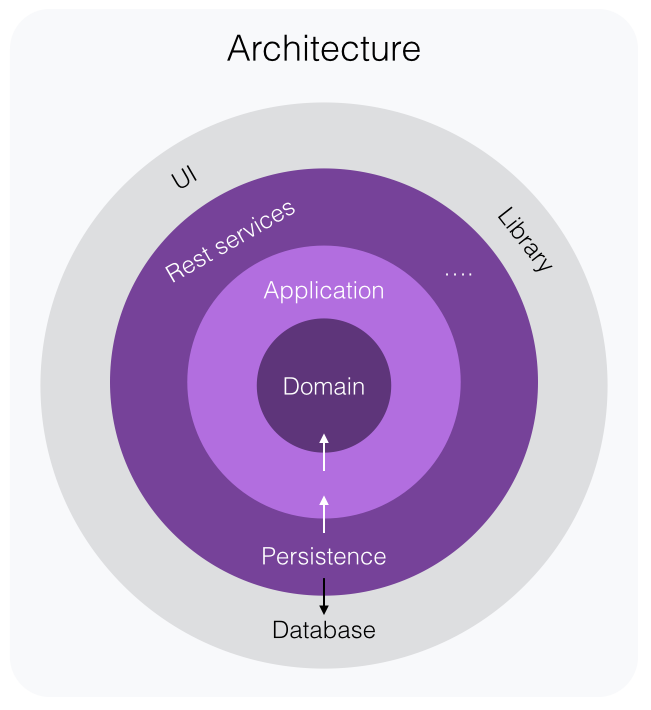
Начать стоит с того, что: Фреймворк - это не ваше приложение . Остановитесь на секундочку и хорошо обдумайте фразу. В типичных веб приложениях фреймворк определяет вообще все. Приложение на 100% переплетается с ним и становится его частью. Программист начинает мыслить в рамках возможностей фреймворка и его ограничений, и в его голове появляются несуществующие причинно-следственные связи.
Да, конечно, сложно (и не нужно) делать абсолютную изоляцию, но и всегда нужно проводить четкую грань между вашим приложением и тем фреймворком, который использует его.
Домен
Первым и базовым слоем в приложении является Домен. Это реализация вашей модели предметной области. Чистая бизнес-логика без намека на инфраструктуру.
Вот что обычно характеризует домен:
- Чистый код (pure)
- Plain Old X Object (POXO)
- Бизнес-логика
- Валидация
POXO - это обобщенное название, которое в каждом конкретном языке приобретает свое собственное имя. В java POJO , в ruby PORO , и так далее. Этой аббревиатурой описывают объекты, которые построены исключительно на возможностях самого языка, без дополнительных абстракций. Так подчеркивается, что домен не использует внешних библиотек, которые влияют на его организацию. Не надо фанатично относится к этой идее. В некоторых языках сформировались свои правила, и они идут в разрез с общими концепциями.
Персистентность
Реализовать логику только половина дела. В конце концов нужно сохранить наши изменения. Казалось бы, что эта часть должна быть самой простой, но нет. Состояние, его мутация и поддержка целостности настолько сложная история, что придуманы огромные и сложные фреймворки, называемые ORM . Обычно они построены вокруг двух самых распространенных паттернов:
- ActiveRecord
- DataMapper
В этом курсе мы их не рассматриваем, но в реальной жизни вам придется с ними столкнуться.
Repository
Репозиторий - это хранилище однотипных сущностей. Позволяет как делать выборки, так и сохранять сущности внутри себя. Для простоты, в нашем приложении репозитории будут хранить все данные в памяти.
const film = new Film(name, duration);
repository = new FilmRepository
repository.save(film);
repository.find(film.id); // film
repository.find(unknownId); // Boom!
Инфраструктура
Именно в эту категорию попадает фреймворк, ui и вообще любая прикладная история. На картинке этот слой находится на самой внешней стороне. Из него происходит посылка емейлов, смс, и выполняется так называемая логика приложения. Например, редирект на определенную страницу после создания какой-то сущности.
Сервисы
Помните диаграмму вариантов использования? Вот именно эти варианты и являются единственным способом изменения состояния вашего приложения. Ваш домен обрастает слоем так называемых сервисов. Каждый сервис представляет собой набор функций, имитирующих бизнес-сценарии, например, “добавить в друзья”, “поставить лайк”.
class CinemaService {
createFilm(name, duration) {
const film = new Film(name, duration);
this.FilmRepository.save(film);
return film;
}
}
Инфраструктурный слой является главным пользователем вашего слоя сервисов. Сервисы могут вызываться в ui , в контроллерах, в асинхронных jobs . Слой сервисов настолько важен сам по себе, что Мартин Фаулер описывает его как шаблон проектирования Service Layer
При проектировании сервисов нужно придерживаться некоторых правил, которые позволяют абстракции не протекать и максимально поддерживать чистоту.
Входными данными в функции сервиса не могут быть сущности предметной области. Причина такого правила очень проста, сервисы, слой поверх предметной области, он инкапсулирует в себе все сценарии. Если сущности окажутся снаружи, то логика становится размазанной между слоями (потекла абстракция), пропадает изоляция. Но так сделать не всегда возможно. Иногда это связано с устройством конкретных фреймворков, которые не дают нормально абстрагировать предметную область от инфраструктуры. В такой ситуации не стоит бороться насмерть за концептуальную чистоту, идите на компромиссы.
Тоже самое касается выходных данных. В теории, отдавать наружу сущности нельзя по той же причине, по которой нельзя ими оперировать вне сервисов. Так как после возврата крайне просто начать ей оперировать, что сразу повлечет за собой размазывание логики по слоям. Вместо сущности, как правило, отдают специальный “Data Transfer Object”. В отличие от сущности он не содержит поведения и используется исключительно как контейнер для чтения.
DTO - Используется для передачи данных между подсистемами приложения. DTO, в отличие от business object, не должен содержать какого-либо поведения
- Неизменяемый
- Просто данные
Опять же, чтобы не усложнять, в тех системах, где нет готовых механизмов для трансляции, возвращают и сущности, но на уровне соглашений используют их исключительно как DTO .
И последнее по списку, но не последнее по важности, не вызывайте сервисы из сервисов. Если появляется общий код, то выносите общую функциональность, но не позволяйте самому сервису начинать мешаться с доменом. Последнее означает то, что если сервисы начинают использовать внутри себя сервисы (тот же или другие), то с большой вероятностью происходит нарушение принципа одного уровня абстракции. Сервисы - слой поверх домена, а это значит что на одном уровне нельзя использовать и домен и сервис.
JS: Предметно-ориентированное проектирование → Валидация
const cinemaHall = new CinemaHall(undefined, -5, 0);
cinemaHallRepository.save(cinemaHall);
Обратите внимание на то, что CinemaHall создается с неверными параметрами. Что будет, если мы попробуем выполнить такой код? Он выполнится и репозиторий с удовольствием сохранит сущность, которая не должна существовать. Вряд ли такое поведение системы можно назвать удачным. Очевидно, что должен существовать дополнительный механизм, предотвращающий подобные ошибки. Этот механизм существует и называется “валидация”.
Валидаций существует много разных типов, и делаться они могут на разных уровнях. Для начала давайте ответим на вопрос: А что необходимо валидировать? Первое правило валидации: никогда не доверяй пользовательским данным. Все, что приходит из внешних источников, должно проходить валидацию. Даже если ваши пользователи это менеджеры, которые сидят в соседнем кабинете, это не повод им доверять. Хотя бы потому, что они могут ошибиться.
Второй вопрос связан с тем, а какая, собственно, валидация существует. Можно выделить следующие виды:
- Клиентская валидация
- Валидация сообщений
- Валидация на уровне обработчиков
- Валидация сущностей (Бизнес-Правила)
- Ограничения на уровне хранилища
В этом уроке мы будем говорить про валидацию сущностей. Ту валидацию, которая отвечает за то, что наше представление предметной области находится в консистентном (согласованном) состоянии.
validate.js
validate.js - это простая и мощная библиотека для валидации объектов js . Из всего, что было на просторах сети, мне она показалась наиболее удачной, для наших задач.
const constraints = {
username: {
presence: true,
exclusion: {
within: ["nicklas"],
message: "'%{value}' is not allowed"
}
},
password: {
presence: true,
length: {
minimum: 6,
message: "must be at least 6 characters"
}
}
};
Для ее использования, первым делом необходимо описать ограничения ( constraints ). К каждому свойству привязывается набор констрейнов. Каждый констрейн может быть настроен согласно документации. Например, констрейн length конфигурируется параметром minimum . Подробнее о том, какие правила встроены в validate.js можно прочитать на официальном сайте.
validate.js: check
Дальше сконфигурированный объект с правилами передается в функцию validate вместе с проверяемым объектом. На выходе мы получаем либо массив с ошибками, либо undefined (в случае, если ошибок не было).
import validate from 'validate';
validate({password: 'bad'}, constraints);
// => {
// username: ["Username can't be blank"],
// password: ['Password must be at least 6 characters']
// }
validate({username: 'nick', password: 'better'}, constraints);
// => undefined
validate({username: 'nicklas', password: 'better'}, constraints);
// => {username: ["Username 'nicklas' is not allowed"]}
validate({password: 'better'}, constraints, {fullMessages: false});
// => {username: ["can't be blank"]}
Теперь попробуем прикрутить эту библиотеку к нашей системе. Вот как это будет выглядеть:
class CinemaService {
createFilm(name, duration) {
const film = new Film(name, duration);
const errors = this.validate(film);
// { name: "can't be blank" }
if (!errors) {
this.FilmRepository.save(film);
}
return [film, errors];
}
}
Здесь есть пара тонкостей, про которые нужно сказать. Во-первых, массив с ошибками нужен, в том числе, снаружи, например для вывода сообщений об ошибках в формах. Во-вторых, мы не можем использовать функцию validate напрямую. Связано это с тем, что есть некоторые виды валидаторов, например uniqueness , которые проверяют уникальность сущности, делая обращения к репозиторию. А это значит, что валидатору нужен доступ к объектам репозиториям (ведь объекты мы храним в памяти). То есть в проекте появляется процесс инициализации, в рамках которого мы конфигурируем наш валидатор, передавая репозитории во внутрь.
Обязательно изучите процесс инициализации приложения в практике к этому
уроку
Такой подход к валидации, который подразумевает то, что сущность может быть создана в невалидном состоянии, не единственный способ организации валидации. Более того, в определенных кругах этот подход считается неверным. Я оставлю этот вопрос за рамками урока, но скажу так. На практике, в подавляющем большинстве проектов используются orm , валидация в которых устроена так же, как описано выше. Более того, ограничения, обычно, описываются прямо в самой сущности.
Собирая все вместе
export default class User {
static constraints = {
email: {
presence: true,
email: true,
uniqueness: true,
},
};
constructor(email) {
this.id = uuid.create().toString();
this.email = email;
}
}
import makeValidator from './lib/validator';
const validate = makeValidator(repositories);
// const validate = entity => validate(entity, entity.constructor.constraints);
const user = new User('test@gmail.com');
const errors = validate(user);
JS: Предметно-ориентированное проектирование → Dependency Injection Container
const repository = new UserRepository();
repository.save(user);
Каждый раз, когда в коде встречается подобная запись, мы уже можем сделать вывод, что полиморфизм включения обошел этот код стороной. Подменить реализацию UserRepository не представляется возможным, ведь он прямо захардкожен в месте своего использования. Такая ситуация не всегда является проблемой, но, все же, хотелось бы иметь возможность легкой подмены компонентов системы. Да и в тестах часто бывает нужно подменять реализации и использовать стабы.
В этой ситуации мы можем воспользоваться DIP , то есть принципом инверсии зависимостей:
- Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций.
- Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Хотя он и звучит страшно, на практике, особенно в динамических языках, применять его проще простого. Грубо говоря, все сводится к тому, что мы передаем зависимости снаружи, а клиентский код ими пользуется. Например так:
const createUser = (userData, UserRepository) => {
const user = new User(userData);
const repository = new UserRepository(); // приходит снаружи
repository.save(user);
}
Как видите, теперь код не зависит от конкретной реализации репозитория. Так мы получаем преимущества от ООП. Только всегда будьте прагматиками. Инверсия ради инверсии, это так себе обоснование для усложнения. В реальности не так часто бывает нужна подмена, как об этом кричат в некоторых книжках, но все же это важная тема.
Рядом с DIP всегда появляется словосочетание Dependency Injection или Внедрение Зависимостей - это набор способов, с помощью которых можно доставить зависимости. Кроме внедрения через параметры функции, выделяют следующие способы:
- Через конструктор
- Через сеттер
Кроме собственно полиморфизма, многим компонентам часто нужны готовые объекты, представляющие различные подсистемы программы. К таким компонентам могут относится соединения с базой данных, доступы к кешам, любые стейтфул компоненты. Единственный способ получать к ним доступ без внедрения зависимостей это использование глобальных переменных.
Многие действительно так и делают, более того, экосистемы некоторых языков подталкивают к таким подходам. Например, в руби очень часто объекты делаются глобальными переменными.
Из этой ситуации есть несколько хорошо изученных выходов.
Service Locator
Сервис локатор - это чуть более продвинутая альтернатива глобальным переменным. Этот паттерн подразумевает наличие одного глобального объекта, который и является сервис локатором. В начале программы он инициализируется всеми нужными сервисами. В процессе жизни программы каждый компонент сам запрашивает у локатора нужные зависимости. Честно скажем, что этот подход так себе, но за неимением лучшего, может стать неплохим подспорьем.
import locator from './locator'
const sendEmail = (subject, body) => {
const email = new locator.emailKlass(subject, body);
locator.emailSender.send(email);
}
DI Container
Самый продвинутый вариант называется Dependency Injection Container . При таком подходе контейнер становится центральной частью системы. С одной стороны он предоставляет интерфейс для описания всех сервисов и их зависимостей, с другой стороны сам занимается созданием графа объектов, попутно внедряя зависимости в те места, где они нужны. Такой подход особенно распространен в таких языках как java/c# . Возможно, вы даже слышали такое название, как spring framework .
Ниже представлен один из вариантов того, как могли бы выглядеть части системы, использующей контейнер:
class SendService {
constructor(EmailKlass, sender) {
this.EmailKlass = EmailKlass;
this.sender = sender;
}
sendEmail(subject, body) {
const email = new this.EmailKlass(subject, body);
this.sender.send(email);
}
}
Как видите, класс не запрашивает никаких зависимостей сам, они внедряются через конструктор какой-то внешней системой.
bottlejs
bottlejs это библиотека, которая позиционирует себя как DI Micro Container . В отличии от своих старших собратьев, он очень прост (я бы сказал деревянен) и обладает куцыми возможностями, но вполне себе позволяет собрать приложение и внедрить зависимости снаружи.
const bottle = new Bottle();
bottle.service('Barley', Barley);
bottle.service('Water', Water);
bottle.factory('Beer', (container) => {
const barley = container.Barley;
const water = container.Water;
barley.halved();
water.spring();
return new Beer(barley, water);
});
bottle.container.Beer;
JS: Предметно-ориентированное проектирование → Предметная область
Предметно-ориентированное проектирование (Domain-driven design) - это набор принципов и схем, направленных на создание оптимальных систем объектов. Сводится к созданию программных абстракций, которые называются моделями предметных областей. В эти модели входит бизнес-логика, устанавливающая связь между реальными условиями области применения продукта и кодом.
Данный термин был впервые введен Э. Эвансом в его книге с таким же названием «Domain-Driven Design»

Представьте себе, что перед вами поставили задачу разработать биллинг (система тарификации, выставление счетов, обработка платежей) для интернет-провайдера. С чего вы начнете проектирование такой системы? А начать надо с анализа предметной области. Познакомиться с основными сущностями системы и их взаимоотношениями, другими словами, вам будет необходимо разобраться в онтологии предметной области.
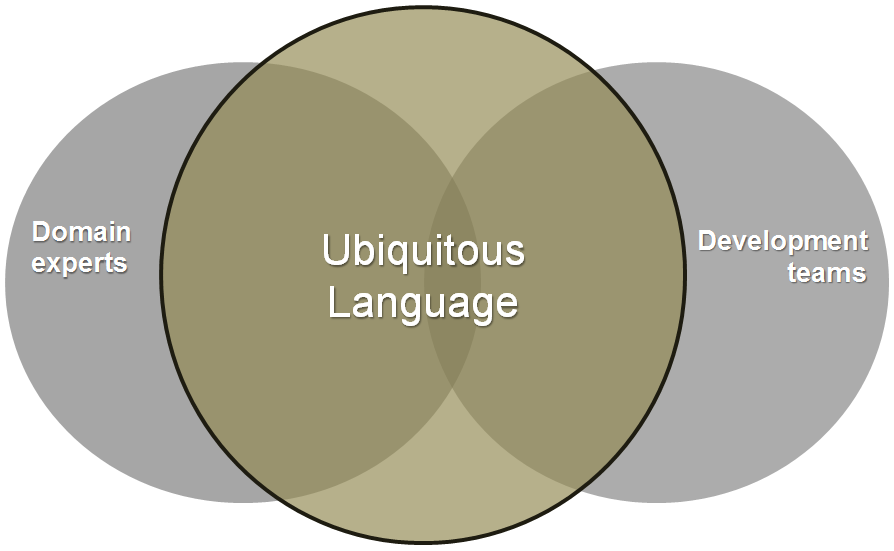
И вот тут на сцену выходит DDD . Центральная идея этого подхода заключается в том, что разработчики постоянно активно сотрудничают с экспертами предметной области (со стороны заказчика) и вместе с ними формируют так называемый единый язык. Этот язык будет использоваться для общения между всеми членами команды, а позже отразится в исходном коде разрабатываемой программы.
Ubiquitous Language - Это не бизнес жаргон, навязанный разработчикам, а настоящий язык, созданный целостной командой – экспертами в предметной области, разработчиками, бизнес-аналитиками и всеми, кто вовлечен в создание системы. Роль в команде не столь существенна, поскольку каждый член команды использует для описания проекта единый язык. Процесс создания единого языка более творческий чем формальный, так как он, как и любой другой естественный язык, постоянно развивается, а те артефакты, которые вначале способствовали разработке полезного единого языка, со временем устаревают. В итоге, остаются только самые устойчивые и проверенные элементы.
Наиболее важное для разработчика – это умение слушать экспертов, получать максимальное количество полезных знаний о предметной области. В то же время, эксперты также должны прислушиваться к разработчикам и их пожеланиям. Команда учится и растет вместе, если она действует сплоченно, получая более глубокое понимание бизнеса.
Bounded context
Это второе по значимости свойство DDD после единого языка. Оба эти понятия взаимосвязаны и не могут существовать друг без друга.
Итак, ограниченный контекст – это явная граница, внутри которой существует модель предметной области, которая отображает единый язык в модель программного обеспечения.
В каждом ограниченном контексте существует только один единый язык.
- Ограниченные контексты являются относительно небольшими.
- Ограниченный контекст достаточно велик только для единого языка изолированной предметной области, но не больше.
- Единый значит «вездесущий» или «повсеместный», т. е. язык, на котором говорят члены команды и на котором выражается отдельная модель предметной области, которую разрабатывает команда.
- Язык является единым только в рамках команды, работающей над проектом в едином ограниченном контексте.
- Попытка применить единый язык в рамках всего предприятия или что хуже, среди нескольких предприятий, закончится провалом.
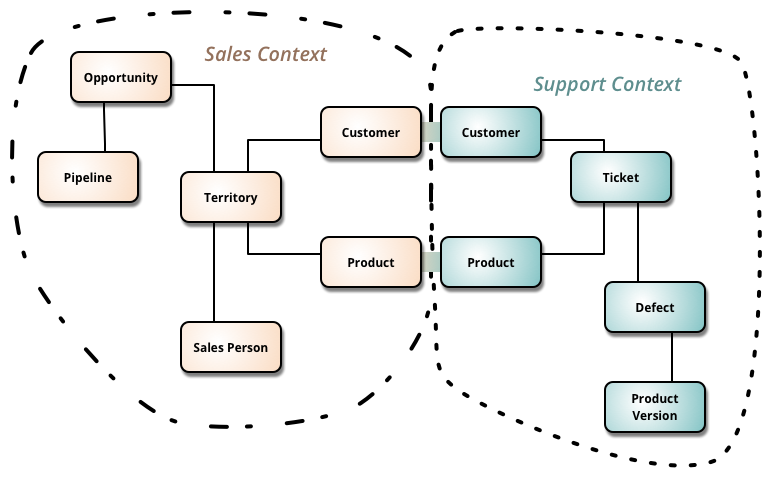
Например, система биллинга крупной телекоммуникационной компании может иметь следующие ключевые элементы (контексты):
- Клиентское обслуживание
- Система безопасности и защиты
- Резервное копирование
- Взаимодействие с платежными системами
- Ведение отчетности
- Система уведомлений
В этом уроке были представлены самые базовые понятия и идеи предметно-ориентированного проектирования. За более подробным описанием можно обратиться к отличной статье на хабре, либо к книге Эрика Эванса. Так же не могу не порекомендовать мое выступление на одной из региональных конференций, в котором я рассказываю о похожих идеях, помогающих улучшить качество кода, который мы пишем.
JS: Предметно-ориентированное проектирование → Мутация
На протяжении всего курса, в практической части, мы разрабатывали сценарии, в которых происходило только добавление сущностей. Добавление это наиболее простая операция из всех возможных, потому что в ней отсутствует (почти) изменяемость данных. Но большинство сценариев в реальной жизни, обычно, связано с изменением:
- Обновление расписания
- Возврат билета
- Удаление кинозала
- Изменение конфигурации кинозала
И вот тут начинаются настоящие проблемы. Попробуйте ответить себе на следующие вопросы:
- Можно ли безопасно удалить из системы кинозал?
- Можно ли безопасно изменить конфигурацию зала в любой момент времени?
- Простая ли операция возврат билета?
На все эти (и многие другие) вопросы ответ: нет. Возврат билета затрагивает множество связанных сущностей, например, в зале нужно освободить место для возможности перепродажи. Удаление кинозала из системы приведет к тому, что все предыдущие просмотры фильмов в этом зале станут не консистентными, мы потеряем историю операций. Изменение конфигурации зала приведет к поломке старых покупок. Удаление сеанса связано с возвратом билетов, а эта операция, в свою очередь, порождает цепочку других изменений.
Итак, чем же нам грозит изменяемость:
- Сложное обновление связанных сущностей
- Отсутствие истории
- Рассинхронизация
- Повреждение старых связей
В связи с этим хочется сформулировать первое правило мутации:
Не мутируй!
И действительно, на практике, часто, можно и нужно проектировать систему так, чтобы изменяющие действия превращались в append only . Проницательный читатель, вероятно, заметил что эта идея очень сильно коррелирует с главным принципом функционального программирования, а именно отсутствием изменений. Это действительно так, проблема изменяемого состояния это не проблема кода и программирования, это особенность физической реальности. И на практике гораздо лучше пытаться уйти от изменений, чем пытаться создать систему, которая консистентно обновляет все нужные связи, что в общем случае невозможно и рождает очень много случайной сложности.
Разберем несколько простых примеров.
Изменение конфигурации зала
В такой ситуации правильно создать новый зал с другой конфигурацией, а предыдущий архивировать. То есть перевести конечный автомат жизненного цикла зала в состояние archived . Соответственно, все старые данные остаются в согласованном виде. У нас появляется история, и мы можем отследить момент в который произошла физическая перепланировка зала.
Возврат билетов
При возврате билета, правильно не удалять записи о том что был приход денег. Правильно создать новую запись, в которой отражается расход. Кроме стандартных плюсов, мы получаем возможность проводить глубокий бизнес-анализ ситуации с возвратами. Сам билет так же может быть переведен в состояние (везде конечные автоматы) возвращен .
Current
Еще один подход для ухода от мутации связан с тем, что вводится понятие current . Например на хекслете есть понятие “Упражнение”, это задание, которое выполняется в нашей ide . Перед тем как новая версия упражнения попадает на сайт, она проходит этап сборки и верификации. На этом этапе происходит упаковка всех зависимостей, кода упражнения в докер образ, а так же выполнение различных проверок на работоспособность, в первую очередь, конечно же, тестов.
Исправлять упражнение ни в коем случае нельзя. Потому что всегда есть пользователи, которые проходят старую версию упражнения. И если бы мы делали изменение текущей версии, то у части упражнение перестало бы работать. Выход из ситуации очень простой, мы разделяем понятия Exercise и Exercise::Build . И после того как успешно пройдет новый Exercise::Build , то в Exercise будет записан Current Exercise Build . После этого все новые старты будут использовать эту сборку, а старые - ту, которая была актуальна на момент старта. Для функционирования такого механизма нужно всегда записывать Current Exercise Build в объект, представляющий собой запущенную практику, тогда все будет работать даже если появится новая сборка.
На практике это очень простая тактика. Хекслет использует ее просто повсеместно, и, таким образом, мы сильно снижаем затраты на синхронизацию данных.