Первое, с чем мы сталкиваемся в js при работе с IO – это коллбеки, сложность использования которых резко нарастает с увеличением зависимостей.
import fs from 'fs';
const myFile = '/tmp/test';
fs.readFile(myFile, 'utf8', (err, txt) => {
if (err) {
return console.log(err);
}
const newTxt = `${txt}'\nAppended something!`;
fs.writeFile(myFile, newTxt, err => {
if (err) {
return console.log(err);
}
console.log('Appended text!');
});
});
И мы знаем уже как минимум один способ борьбы с этой сложностью и даже написали реализацию нескольких функций библиотеки async .
async.filter(['file1', 'file2'], (filePath, callback) => {
fs.access(filePath, err => {
callback(null, !err)
});
}, (err, results) => {
// results now equals an array of the existing files
});
Этот способ довольно неплох, но обладает рядом недостатков. Один из основных связан с тем, что необходимо знать большое количество разнообразных функций на все случаи жизни. Другой – с тем, что комбинирование функций самой библиотеки async приводит к громоздкому коду, который, к тому же, не так просто понимать.
Оказывается, что существует ряд других способов работы с асинхронным кодом, часть из которых может быть реализована без поддержки со стороны языка.
- Promise (Futures)
- Coroutines (using Generators)
- Async/Await
В этом курсе будут подробно рассмотрены перечисленные концепции, которые стали неотъемлемой частью современной разработки на js . В процессе знакомства с ними мы построим библиотеку для выполнения http запросов. Она будет основана на промисах, а использовать ее можно будет с генераторами и async/await конструкциями.
import { get } from 'hexlet-http-request';
export default async () => {
const hostname = 'localhost:3000';
const id = await get(`${hostname}/id`);
const group = await get(`${hostname}/group`);
return get(`${hostname}/${group}/${id}`);
}
Как видите, здесь используется новый синтаксис, но сама структура читается хорошо даже без его знания. Код выглядит линейным и не использует коллбеки.
Дополнительно в курсе будет рассмотрен следующий набор тем:
- Формат данных
json - Итераторы
- Атаки в сети (CSRF)
- Модули
nodejs:querystring,url,http
JS: Синхронная асинхронность → URL
При работе с http возникает потребность в библиотеках, позволяющих манипулировать частями адресов, разбирать их, а так же собирать обратно. Nodejs предоставляет такие модули из коробки.
Url
Это модуль, основной задачей которого является парсинг строчки адреса для извлечения составных частей.
import url from 'url';
url.parse('http://user:pass@host.com:8080/p/a/t/h?query=string#hash')
Url {
protocol: 'http:',
slashes: true,
auth: 'user:pass',
host: 'host.com:8080',
port: '8080',
hostname: 'host.com',
hash: '#hash',
search: '?query=string',
query: 'query=string',
pathname: '/p/a/t/h',
path: '/p/a/t/h?query=string',
href: 'http://user:pass@host.com:8080/p/a/t/h?query=string#hash' }
Тоже самое можно визуализировать:
┌─────────────────────────────────────────────────────────────────────────────┐
│ href │
├──────────┬┬───────────┬─────────────────┬───────────────────────────┬───────┤
│ protocol ││ auth │ host │ path │ hash │
│ ││ ├──────────┬──────┼──────────┬────────────────┤ │
│ ││ │ hostname │ port │ pathname │ search │ │
│ ││ │ │ │ ├─┬──────────────┤ │
│ ││ │ │ │ │ │ query │ │
" http: // user:pass @ host.com : 8080 /p/a/t/h ? query=string #hash "
│ ││ │ │ │ │ │ │ │
└──────────┴┴───────────┴──────────┴──────┴──────────┴─┴──────────────┴───────┘
(all spaces in the "" line should be ignored -- they're purely for formatting)
Как видно, этот модуль дал нам возможность извлечь query params из адреса, но в виде строки. Дальше, как вы уже догадались, нам понадобится еще один модуль - querystring.
Querystring
Он также входит в поставку nodejs и работает очень просто:
import querystring from 'querystring';
// w=%D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3&foo=bar
querystring.parse(str);
// { w: 'эрланг', foo: 'bar' }
querystring.stringify({ w: 'эрланг', foo: 'bar' });
// w=%D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3&foo=bar
Здесь необходимо сделать пояснение. Спецификация http разрешает использовать в адресах только те символы, которые входят в ASCII character-set . Возникает вопрос: как быть, если у нас есть другие символы? А для этого применяется специальное кодирование, называемое url encoding . Например, слово скрипт будет закодировано в строку: %D1%81%D0%BA%D1%80%D0%B8%D0%BF%D1%82 .
Модуль querystring делает кодирование/декодирование автоматически, это видно в примере выше. Но если вам вдруг понадобилось делать это руками, то js спешит на помощь:
encodeURI('эрланг');
// %D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3
decodeURI('%D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3');
// эрланг
А теперь собираем все вместе:
import url from 'url';
import querystring from 'querystring';
const uri = '/?q=%D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3';
const { query } = url.parse(uri);
const { q } = querystring.parse(query);
console.log(q); // эрланг
По правде говоря, можно сделать проще: url.parse() принимает вторым параметром флаг, который как раз включает парсинг параметров запроса.
import url from 'url';
import querystring from 'querystring';
const uri = '/?q=%D1%8D%D1%80%D0%BB%D0%B0%D0%BD%D0%B3';
const { query } = url.parse(uri, true);
console.log(query); // { q: 'эрланг' }
Обратная задача – конструирование адреса по его частям – выполняется так же просто с помощью функции format того же модуля:
const data = {
hostname: 'ru.hexlet.io',
pathname: 'my',
query: { page: 5 }
};
url.format(data);
В общем случае в url.format нужно передать объект такой же структуры как и urlObject , получаемый после url.parse . Для более полного понимания работы этой функции нужно смотреть в документацию. У нее есть хитрые кейсы в случае наличия или отсутствия определенных ключей и их значений в передаваемом объекте.
JS: Синхронная асинхронность → GET-запрос
Предположим, что мы хотим программно выполнить get запрос к Хекслету. В nodejs сделать это довольно просто:
import http from 'http';
http.get('http://ru.hexlet.io/my', res => {
console.log(res.statusCode);
});
Вторым параметром передается коллбек, который будет вызван после получения ответа. Он так же принимает на вход объект response , который содержит в себе параметры ответа.
Этих параметров внутри response очень много, и только некоторые из них наиболее часто используются или могут быть нам интересны. В первую очередь это следующий набор:
// response
{
headers: /* ... */,
statusCode: 301,
statusMessage: 'Moved Permanently',
};
Также get позволяет передавать первым параметром не адрес, а набор опций, из которого будет составлен адрес. Такое бывает полезно, когда у нас нет готового адреса, но есть его части:
import http from 'http';
// headers, method, port, ...
const options = {
hostname: 'ru.hexlet.io',
path: 'my',
};
http.get(options, res => {
console.log(res.statusCode);
});
Обо всех доступных опциях можно прочитать в официальной документации, а из самых распространенных мы выделим следующие:
- headers - объект, в котором ключ это название заголовка
- method - например
GET - port
- hostname
- path
Body
В запросе выше не хватает одной важной детали: получение тела ответа. Тут нас поджидает небольшой сюрприз. Объект response не содержит внутри себя тело ответа. Связано это с тем, что ответ может приходить чанками, и response дает возможность получать эти чанки сразу и независимо друг от друга. С одной стороны, это более гибкая возможность, которая позволяет работать с большим телом, без того чтобы занимать много оперативной памяти; с другой стороны, для простых запросов приходится доставать тело немного более сложным способом, чем хотелось бы. Но, в конечном итоге, все сводится к понятному коду, который нужно просто запомнить.
http.get(url, res => {
const body = [];
res.on('data', chunk => {
body.push(chunk.toString());
}).on('end', () => {
const html = body.join();
console.log(html);
});
});
Как видно из примера выше, объект response представляет из себя eventEmitter с событиями data и end . Первое вызывается после получения очередного чанка с данными, второе вызывается после того, как все данные пришли и нужно обозначить конец обработки.
Buffer
Из кода сбора чанков в body можно сделать вывод, что chunk – это не строка. Это действительно так, chunk – это объект типа Buffer , который предназначен для хранения потока байтов в виде массива фиксированного размера. Нужно это по той простой причине, что данные, передаваемые по http , не обязательно имеют текстовое представление. Возможна передача также и бинарных данных, таких как картинки, архивы и тому подобное.
const str = 'string as bytes';
const buffer = new Buffer(str, 'utf-8');
console.log(buffer);
// <Buffer 73 74 72 69 6e 67 20 61 73 20 62 79 74 65 73>
buffer.toString();
// string as bytes
Errors
Во время выполнения запроса может произойти все, что угодно. Библиотека http обрабатывает эти ошибки и кидает соответствующие исключения. К таким ошибкам относятся например:
- Проблемы с
DNS - Ошибки уровня
tcp - Ошибки парсинга
httpответа
Если для программы важно не завершаться в случае таких ошибок, то можно ловить событие error на объекте request , который возвращается после выполнения get запроса и производить желаемое действие:
import http from 'http';
const uri = 'http://ru.hexlet.io/my';
const req = http.get(uri, res => {
console.log(res.statusCode);
});
req.on('error', e => {
console.log(`Got error: ${e.message}`);
});
JS: Синхронная асинхронность → POST-запрос
Разобравшись с get запросом, пора переходить к post и передаче данных на сервер. Для начала познакомимся с методом request модуля http . Ниже пример обычного GET запроса, который мы делали с помощью http.get :
const options = {
hostname: 'ru.hexlet.io',
path: 'my',
method: 'GET', // default
}
const req = http.request(options, res => {
console.log(res.statusCode);
});
req.end();
На самом деле, http.get – это обертка над http.request , которая выполняет req.end автоматически. Ее добавили в модуль http только потому, что это очень частый вариант использования. Другими словами, http.request - универсальный способ делать http запросы. Для выполнения любого запроса, нужно лишь правильно подставить глагол в опцию method , будь то хоть POST хоть HEAD.
Следующий аспект это заголовок Content-Length . Как вы помните из курса http , этот заголовок обязателен при наличии тела запроса. Он содержит цифру - количество байт в теле запроса. Так как данные формы обычно отправляют, используя тип application/x-www-form-urlencoded , то перед подсчетом размера тела его нужно сначала сформировать, выполнив правильные преобразования.
// Content-Type: application/x-www-form-urlencoded
const postData = querystring.stringify({
'msg': 'Hello World!',
'key': 'value',
});
// msg=Hello%20World!&key=value
// Content-Length: ?
Buffer.byteLength(postData);
// 28
Рекомендуется всегда использовать такой способ определения размера тела запроса, потому что он считает количество байт, в отличие от length , который считает количество символов в текстовом представлении. Различия будут проявляться при использовании символов, не входящих в ASCII .
'Пошло поехало'.length; // 13
Buffer.byteLength('Пошло поехало'); // 25
Теперь можно собрать все вместе и выполнить post запрос с передачей данных формы:
const options = {
hostname: 'www.google.com',
path: '/upload',
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': Buffer.byteLength(postData)
}
};
const req = http.request(options, (res) => {
console.log(`STATUS: ${res.statusCode}`);
});
req.write(postData);
req.end();
Данные отправляются с помощью метода write объекта request . Часто можно упростить отправку до вызова req.end(postData) . write больше полезен тогда, когда используется отправка с помощью чанков, например, в случае передачи больших бинарных данных (картинки, видео).
JS: Синхронная асинхронность → Promises
Промисы стали настоящим спасением человечества и среди прогрессивных разработчиков являются основным способом управления асинхронным кодом.
Полное описание всех возможностей и аспектов поведения промисов является объемной задачей, которая может запутать на первых порах, поэтому в этом уроке мы остановимся на ключевых особенностях поведения. Все остальное можно почерпнуть из стандарта и/или документации.
Знакомству с промисами способствует понимание темы “конечные автоматы”.
Начнем по традиции с примера:
const file = '/tmp/hello1.txt';
import { writeFile, readFile } from 'fs-promise';
writeFile(file, 'hello world')
.then(() => readFile(file, 'utf8'))
.then(contents => console.log(contents))
.catch(err => console.log(err));
// hello world
В этом примере происходит запись файла, затем чтение этого же файла, затем вывод содержимого этого файла в консоль, а в случае ошибки, возникшей на любом этапе, она была бы выведена на экран.
Абзац выше – это пример того, как выглядит типичная программа, построенная на промисах. Так что такое промис?
Объект, используемый для асинхронных операций. Промис содержит в себе результат выполнения и позволяет строить цепочки из вычислений, избегая проблемы callback hell
Интерфейс:
Promise.prototype.then(onFulfilled, onRejected)Promise.prototype.catch(onRejected)
Отсутствие callback hell происходит благодаря тому, что мы всегда работаем на уровне последовательных вызовов then , а не уходим в глубину.
Разберем пример выше по косточкам. Первый вызов writeFile(file, 'hello world') возвращает тот самый промис, и пока не важно, как он строится внутри, сейчас мы пытаемся понять то, как с ним работать.
// Вызов ничем не отличается кроме того, что мы не передаем коллбек
writeFile(file, 'hello world')
После этого у нас есть два варианта:
- Мы вызываем
thenи передаем функциюonFulfilled, которая будет вызвана в случае успешного выполнения асинхронной операции - Мы вызываем
catchи передаем функциюonRejected, которая будет вызвана, в случае ошибок в результате выполнения асинхронной операции.
Функция onFulfilled принимает на вход данные, которые были получены в результате предыдущего выполнения. Таким образом идет передача данных по цепочке.
.then(() => readFile(file, 'utf8'))
.then(contents => console.log(contents))
Данные, возвращаемые из функции onFulfilled , переходят по цепочке в функцию onFulfilled следующего then . Но если вернуть promise , то в следующем then окажутся данные, полученные в результате выполнения этого промиса, а не сам промис. Что и происходит в примере выше: мы возвращаем readFile() , а ниже получаем contents . То есть, промисы хорошо комбинируются друг с другом.
Конечный автомат
Теперь попробуем посмотреть внутрь промиса. С концептуальной точки зрения промис – это конечный автомат, у которого три состояния: pending , fullfiled , rejected .
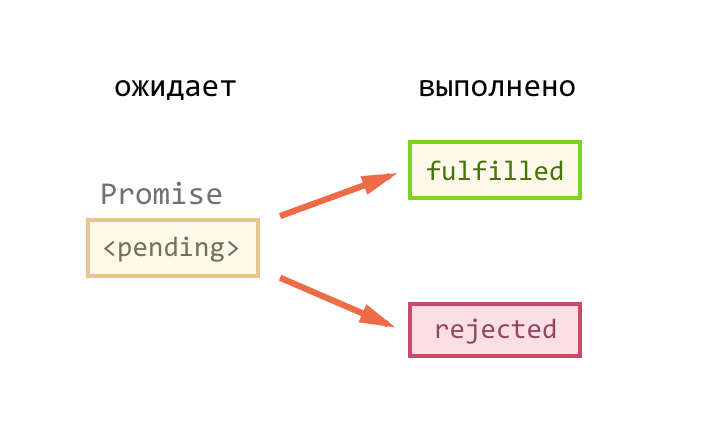
Изначально он находится в состоянии pending , а дальше может перейти в одно из двух: либо выполнен ( fullfiled ), либо отклонен ( rejected ). И все, больше никакие переходы невозможны. Придя один раз в одно из терминальных (конечных) состояний, промис больше не подвержен изменениям, как бы мы не старались снаружи заставить его перейти в другое состояние.
Реализация
const promiseReadFile = filename => {
return new Promise((resolve, reject) => {
fs.readFile(filename, (err, data) => {
err ? reject(err) : resolve(data);
});
});
};
Любая функция возвращающая промис, внутри себя создает объект промиса привычным способом. Конструктор Promise принимает на вход функцию, внутри которой запускается выполнение асинхронной операции. Делается это, кстати, сразу, промисы не являются примером отложенного (lazy) выполнения кода. Но это еще не все. Промис требует от нас некоторых действий для своей работы. Во входную функцию передаются две другие: reject и resolve . reject должна быть вызвана в случае ошибки, с передачей внутрь объекта error , а resolve - в случае успешного завершения асинхронной операции с передачей внутрь данных, если они есть.
Ошибки
Ошибка обрабатывается ближайшим обработчиком onRejected в цепочке вызовов. При этом существует два варианта определения обработчика. Первый - через catch , второй - с помощью передачи в then второго параметра. Это продемонстрировано в примере ниже:
promiseReadFile('file1')
.then(data => promiseWriteFile('file2', data))
.then(() => promiseReadFile('file3'))
.then(data => console.log(data))
.catch(err => console.log(err));
// .then(null, err => console.log(err));
Promise.all
Иногда возникает необходимость дождаться выполнения нескольких асинхронных операций. В этом случае можно воспользоваться идиомой Promise.all . Работает она очень просто: в эту функцию передается массив промисов, а дальше в then приходит массив с результатами выполнения.
const readJsonFiles = filenames => {
// N.B. passing readJSON as a function,
// not calling it with `()`
return Promise.all(filenames.map(readJSON));
}
readJsonFiles(['a.json', 'b.json'])
.then(results => {
// results is an array of the values
// stored in a.json and b.json
});
JS: Синхронная асинхронность → JSON
Хотя мы и привыкли чаще всего иметь дело с программами, которые пишутся для людей, это не всегда так. Некоторые программы вообще никак не соприкасаются с человеком, другие общаются и между собой и с человеком тоже.
В такой ситуации важно договориться не только о способе передачи данных, таком как протокол http , но и о том, как будут представлены данные, так чтобы их могли читать программы, написанные на разных языках и выполняющиеся в разных окружениях.
Одним из таких способов представления структурированных данных является json .
JSON
JSON (JavaScript Object Notation) - простой формат обмена данными, удобный для чтения и написания как человеком, так и компьютером. Он основан на подмножестве языка программирования JavaScript.
{
"firstName": "John",
"lastName": "Smith",
"isAlive": true,
"age": 25,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
},
"phoneNumbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "office",
"number": "646 555-4567"
},
{
"type": "mobile",
"number": "123 456-7890"
}
],
"children": [],
"spouse": null
}
Структура подозрительно смахивает на объекты, с которыми мы работаем в js. По большому счету это и есть текстовое представление наших объектов.
json стал настолько популярным форматом, что в большом количестве языков библиотека для преобразования в json и обратно входит в стандартную поставку. Можно даже сказать, что этот формат стандарт де-факто для обмена информацией между сервисами в интернете. Его характеристики списком:
- Языко-независимый
- Текстовый
- Человеко-ориентированный
- Доступен везде
js так же имеет встроенные средства для трансляции в json и обратно, причем как в браузере, так и в nodejs :
const obj = { key: 'value', keys: ['v1', 'v2'] };
const str = JSON.stringify(obj);
// {"key":"value","keys":["v1","v2"]}
JSON.parse(str);
// { key: 'value', keys: [ 'v1', 'v2' ] }
Media Type
При передаче контента по интернету мы должны явно специфицировать, какого типа этот контент. Достигается это использованием заголовка content-type . А вот значение, которое можно туда подставить, не является произвольным. Существует такое понятие, как media type (раньше – MIME type ), которое представляет из себя строковой идентификатор. Для json он выглядит так: application/json .
JS: Синхронная асинхронность → Итераторы и Генераторы
Этот урок посвящен механизму, основное предназначение которого не связано с асинхронным кодом. Этот механизм называется генераторами и, фактически, представляет из себя улучшенный итератор. А поскольку с итераторами мы тоже не знакомы, то начнем наше повествование с них.
Итак, вообразим следующую задачу: необходимо сделать объект, содержащий в себе коллекцию (чего угодно), итерируемым. На практике это означает, что мы можем идти циклом по самому объекту, хотя, как мы знаем, по умолчанию это невозможно. Пример:
// Упадет с ошибкой
for (const v of { a: 1, b: 2 }) {
console.log(v);
}
// obj это объект и for спокойно по нему пройдется
const obj = makeIterator(); // Устройство функции makeIterator будет раскрыто позже
for (const v of obj) {
console.log(v);
}
Во втором примере, obj представляет из себя итерируемый объект ( iterable object ). Мы можем самостоятельно сделать его таким:
const obj = {
collection: ['yo', 'ya'],
[Symbol.iterator]: makeIterator,
};
for (const v of obj) {
console.log(v);
}
// yo
// ya
Напомню, что Symbol – это специальный неизменяемый тип данных. В основном используется в свойствах объектов. js предоставляет несколько встроенных символов, одним из которых и является iterator .
Чтобы сделать любой объект итерируемым, нужно создать свойство со значением Symbol.iterator и записать туда специальную функцию, о структуре которой мы сейчас и поговорим.
Эта функция не является общей для всех итерируемых объектов, ее содержимое зависит от объектов, для которых она предназначена. Общее правило - функция должна реализовывать The iterable protocol .
const makeIterator = function () {
let nextIndex = 0;
const next = () => {
if (nextIndex < this.collection.length) {
const value = this.collection[nextIndex++];
return { value, done: false };
}
return { done: true };
};
return { next };
};
Функция makeIterator не имеет параметров, потому что так она вызывается внутри js . Из этого следует, что доступ к текущему объекту, к которому она прикреплена, возможен только через this , а значит она должна быть объявлена как functionDeclaration , а не arrowFunction . Требование к возвращаемому значению этой функции следующее:
Необходимо вернуть объект с методом next . Каждый вызов next будет возвращать объект с двумя свойствами: value и done . value – это значение текущего элемента коллекции, а done – это флаг конца коллекции. Как только next завершает перебор, то возвращается { done: true } , и это является сигналом к тому, что итерирование завершено.
Можно продемонстрировать работу этой функции, немного переписав ее для возможности прямого вызова:
const makeIterator = coll => {
let nextIndex = 0;
const next = () => {
if (nextIndex < coll.length) {
const value = coll[nextIndex++];
return { value, done: false };
}
return { done: true };
};
return { next };
}
Еще раз отмечу, что выше мы создали пример только для демонстрации, в реальном коде такая функция не сделает объект итерируемым.
const it = makeIterator(['yo', 'ya']);
it.next(); // { value: 'yo', done: false }
it.next(); // { value: 'ya', done: false }
it.next(); // { done: true }
Именно так будет вызываться next скрыто от наших глаз в момент итерации по объекту.
Что можно заметить, глядя на эту функцию? Она содержит в себе скрытое состояние, которое необходимо для запоминания текущей позиции. Как мы помним, состояние – штука сложная, и, программируя в таком стиле, легко допустить ошибку.
Оказывается, что можно переложить задачу по управлению состоянием на машину. И делается это с помощью так называемых, генераторов.
const makeIterator = function* (coll) {
for (const value of coll) {
yield value;
}
};
const it = makeIterator(['yo', 'ya']);
it.next(); // { value: 'yo', done: false }
it.next(); // { value: 'ya', done: false }
it.next(); // { value: undefined, done: true }
Как видно из примера, генераторы вводят новый синтаксис в язык. Во-первых, это звездочка после слова function . Она просто указывает на то, что мы имеем дело с генератором. Во-вторых, выражение yield (подчеркиваю: это – не инструкция).
Генератор, в отличие от обычной функции, при своем вызове не выполняет тело, а возвращает специальный объект с методом next . Каждый раз, когда вызывается next , запускается тело генератора с того места, где оно остановилось последний раз. При первом вызове выполнение идет с самого начала генератора и продолжается до встречи с выражением yield . В этот момент управление передается наружу, next возвращает то, что было передано в yield , а генератор замирает в этом состоянии, на выражении yield . Последующие вызовы начинают работу от yield .
Еще один пример для осознания:
const gen = function* () {
yield 1;
yield 2;
yield 3;
};
const it = gen();
it.next(); // { value: 1, done: false }
it.next(); // { value: 2, done: false }
it.next(); // { value: 3, done: false }
it.next(); // { value: undefined, done: true }
Или даже так:
const it = gen();
[...it]; // [1, 2, 3]
Кроме yield в генераторах можно использовать версию yield* , которая ожидает на вход коллекцию и делает yield для каждого элемента этой коллекции.
const makeIterator = function* () {
yield* this.collection;
};
Теперь можно переписать наш первый пример вот таким образом:
const obj = {
collection: ['yo', 'ya'],
[Symbol.iterator]: function* () {
yield* this.collection;
},
};
for (const v of obj) {
console.log(v);
}
// yo
// ya
JS: Синхронная асинхронность → Корутины
В Computer Science под генераторами понимается data producer , то есть сущность в языке, которая только выдает наружу данные, используя yield . При этом существует более общая концепция, которая называется coroutine или сопрограмма. В отличие от генераторов, она может не только генерировать данные, но так же может и потреблять их ( data consumer ). Самым удивительным в этой истории является то, что генераторы в js , по сути, являются корутинами, а использование их в качестве генераторов – это всего лишь один из возможных вариантов.
Сопрограмма — компонент программы, обобщающий понятие функции, который дополнительно поддерживает множество входных точек (а не одну, как функция), остановку и продолжение выполнения с сохранением определенного положения.
Главное, на что нужно обратить внимание, это появление выражения yield справа от знака равно: const a = yield 10 .
Попробуем по шагам выполнить этот код:
- Создание корутины
const coroutine = gen(); - Вызов
next(). Первый вызов приводит к тому, что наружу возвращается{ value: 10, done: false }, так как внутри мы оказываемся в точкеyield 10. - Вызов
next(result.value + 1). Выражениеresult.value + 1равно11, поэтому в итоге происходит вызовnext(11). Внутри корутины мы находимся в этой позицииconst a = yield. Аргумент, переданный вnext, оказывается записанным в константуaвнутри корутины и код продолжает выполнятся до следующего вызоваyield, на котором корутина останавливается, и управление возвращается наружу. - Дальнейший вызов
next(15)приводит к тому, что константаbстановится равна15, а наружу возвращается{ value: 26, done: true }.
Если обобщить, то yield <что-то> производит данные наружу, const a = yield потребляет данные, а const a = yield <что-то> производит и потребляет в два шага.
Теперь, используя немного магии, мы можем создать обертку над генераторами для работы с асинхронным кодом.
co(function* () {
const a = yield Promise.resolve(1);
const b = yield Promise.resolve(2);
const c = yield Promise.resolve(3);
console.log([a, b, c]); // [1, 2, 3]
});
Идея в том, что функция co автоматически итерирует по генератору, извлекая значение из промисов и передавая их дальше в next по цепочке. В целом, на этом можно было бы и остановиться, но для полной имитации синхронной работы хотелось бы поддержки со стороны try/catch . И генераторы дают возможность трансформировать ошибки в исключения.
co(function* () {
const a = yield Promise.resolve(1);
try {
const b = yield Promise.reject(new Error('Boom'));
} catch (e) {
console.log(e.message); // Boom
}
});
Чтобы такой код заработал, необходимо в функции co отслеживать состояние rejected и использовать метод throw , который есть у нашего генератора. Ниже пример того, как это можно было бы сделать (без промисов):
const gen = function* () {
try {
const a = yield;
yield new Error('Boom');
} catch (e) {
console.log(e.message);
}
console.log('after Boom');
};
const coroutine = gen();
coroutine.next();
const result = coroutine.next();
coroutine.throw(result.value); // => { value: undefined, done: true }
// Boom
// After Boom
Метод throw() возобновляет выполнение тела генератора кидая внутри исключение и возвращает объект со свойствами done и value.
JS: Синхронная асинхронность → async/await
Концепция async/await для работы с асинхронным кодом впервые появилась на платформе .net в 2011 году. С тех пор разработчики многих языков оценили удобство этой конструкции и начали ее внедрение. Например, такое произошло с python , в котором есть уже встроенная поддержка этого механизма, а также с языком kotlin . js тоже не остается в стороне, и не смотря на то, что этот механизм находится в стадии разработки (он не утвержден), многие его уже активно используют в продакшен среде. Хекслет начал использовать async/await еще в 2015 году, за что отдельное спасибо babel .
Использование async/await очень похоже на то, как мы работаем с генераторами:
const load = async () => {
const a = await Promise.resolve(5);
const b = await Promise.resolve(10);
return a + b;
};
load().then(value => console.log(value)); // 15
Первым делом необходимо добавить ключевое слово async перед определением функции. Это обязательное условие для включения механизма. Далее, перед каждой асинхронной операцией ставится ключевое слово await . Сами операции должны возвращать promise . По правде говоря, async/await – это механизм, построенный вокруг и для промисов.
Стоит отметить, что async функция не является генератором, это обычная функция, которая выполняется сверху вниз и, в конце концов, может вернуть результат. Только в отличие от обычного кода на js , await дожидается выполнения асинхронной операции и возвращает ее значение. Как видно, код такой функции плоский и очень легко читается.
Еще одной особенностью таких функций является то, что наружу всегда будет возвращен промис, даже если мы возвращаем что-то другое, как в примере выше. Внутри происходит автоматическое преобразование Promise.resolve(a + b) . Кстати, это означает, что код, вызывающий async функцию, может применять к ней await , и так далее по цепочке вверх.
Теперь можно посмотреть на более комплексный пример и сравнить генераторы с async/await :
import { get } from 'hexlet-http-request';
const getFriends = id => {
return co(function* () {
const link = `http://ru.hexlet.io/users/${id}.json`;
const user = yield get(link);
yield Promise.all(user.friends.map(f => get(f.link)));
});
};
getFriends(5).then(friends => console.log(friends));
Версия с async/await :
import { get } from 'hexlet-http-request';
const getFriends = async id => {
const link = `http://ru.hexlet.io/users/${id}.json`;
const user = await get(link);
return await Promise.all(user.friends.map(f => get(f.link)));
};
const load = async () => {
const friends = await getFriends(5);
console.log(friends);
};
load();
Здесь можно отметить следующий момент: async/await не предоставляют возможности выполнить одновременно несколько асинхронных операций, для этого нужно будет пользоваться Promise.all , что логично, ведь await ждет промис.