Массивы — первый и главный составной тип данных, с которым мы познакомимся. Как уже говорилось в курсе о ключевых аспектах разработки на PHP, работа с коллекциями относится к основополагающим навыкам в программировании, независимо от специализации программиста.
Вот лишь некоторые примеры того, где мы работаем с коллекциями:
- Постраничный вывод на сайте
- Подсчет общей суммы в заказе на основании каждой из позиций
- Вывод списка друзей, сообщений, фильмов и тому подобное
Нередко задачи c коллекциями имеют алгоритмический характер. То есть требуют от вас составления разумного (не обязательно оптимального по скорости или памяти) алгоритма. К таким задачам относится, например, сортировка. И хотя она уже реализована как функция стандартной библиотеки, умение написать сортировку самостоятельно говорит о вашем развитом алгоритмическом мышлении. Другой реальный пример связан с поиском пересечений, например, необходимостью найти общих друзей у вас и у вашего друга. Такая функциональность реализована на Фейсбуке. Для решения данной задачи желательно также понимать математическую основу — теорию множеств (это не сложно). В программировании она требуется на каждом углу, даже при работе с базами данных (SQL).
Возможно, вы слышали (и не раз!) о том, что изучение программирования стоит начинать с изучения алгоритмов и структур данных. Вероятно, вам даже рекомендовали книги Кнута для их постижения. По большей части я согласен с этим утверждением, но читать Кнута от корки до корки — занятие не для слабонервных.
Знание алгоритмов и структур позволяет вам создавать по-настоящему хорошие решения, понимать плюсы и минусы тех или иных подходов, дает способность быстро ориентироваться на местности. В университетах примерно так и происходит. Другой вопрос в том, насколько глубоко и долго погружаться в эту тему. Когда речь идёт про наших пользователей, то, как правило, мы имеем ограниченный запас времени и почти наверняка отсутствие хорошего бекграунда. В этих условиях я постараюсь дать небольшую базу, достаточную для понимания происходящего, чтобы как можно быстрее перейти к реальной веб-разработке. В дальнейшем, по желанию, вы всегда сможете углубиться в эти темы, благо материала на просторах сети по ним крайне много. В любом случае важно понимать, что обозначенная выше тема не является уделом хардкорных программистов. Она одинаково важна и для системных, и для веб-программистов.
В этом курсе вы научитесь не только базовым операциям над массивами, но и немного коснетесь основных структур данных, познакомитесь с понятием алгоритмической сложности, научитесь решать некоторые типичные алгоритмы, которые нередко спрашивают на собеседованиях.
Дополнительные материалы
PHP: Массивы → Синтаксис
Перед тем как изучать синтаксис работы с массивами, стоит понять его суть на логическом уровне. Для этого достаточно здравого смысла. Массивом в программировании представляют любые списки (коллекции элементов), будь то курсы на Хекслете либо сайты в поисковой выдаче или друзья в вашей любимой социальной сети. Задача массива представить такие списки в виде единой структуры, которая позволяет работать с ними как с единым целым.
Определение массива
<?php
$animals = ['cats', 'dogs', 'birds'];
Массив представляет из себя список элементов , заключенных в квадратные скобки. В примере выше происходит определение массива ['cats', 'dogs', 'birds'] и присваивание его переменной $animals . PHP позволяет создавать массив из разнотипных данных, то есть чисто технически можно создать и такой массив:
<?php
$values = [null, 'one', 4, 'two', false];
На практике такой подход лучше не использовать. Для разнотипных данных обычно, хорошо подходит ассоциативный массив, которому посвящен следующий курс.
Кроме того, можно создать и пустой массив:
<?php
$animals = [];
Как правило, пустой массив используют в ситуации, когда мы работаем с коллекцией, но значения отсутствуют. Такой подход позволяет избежать условных проверок на то, является ли данное значение массивом. Либо его используют в алгоритмах, которые постепенно наполняют массив в процессе своей работы.
( Для любознательных : массив в PHP — динамическая структура. Её можно расширять прямо в процессе работы программы. В языках, близких к железу, таких как Си, размер массива — постоянная величина. При необходимости расширения в подобных языках создают новый массив).
Получение данных
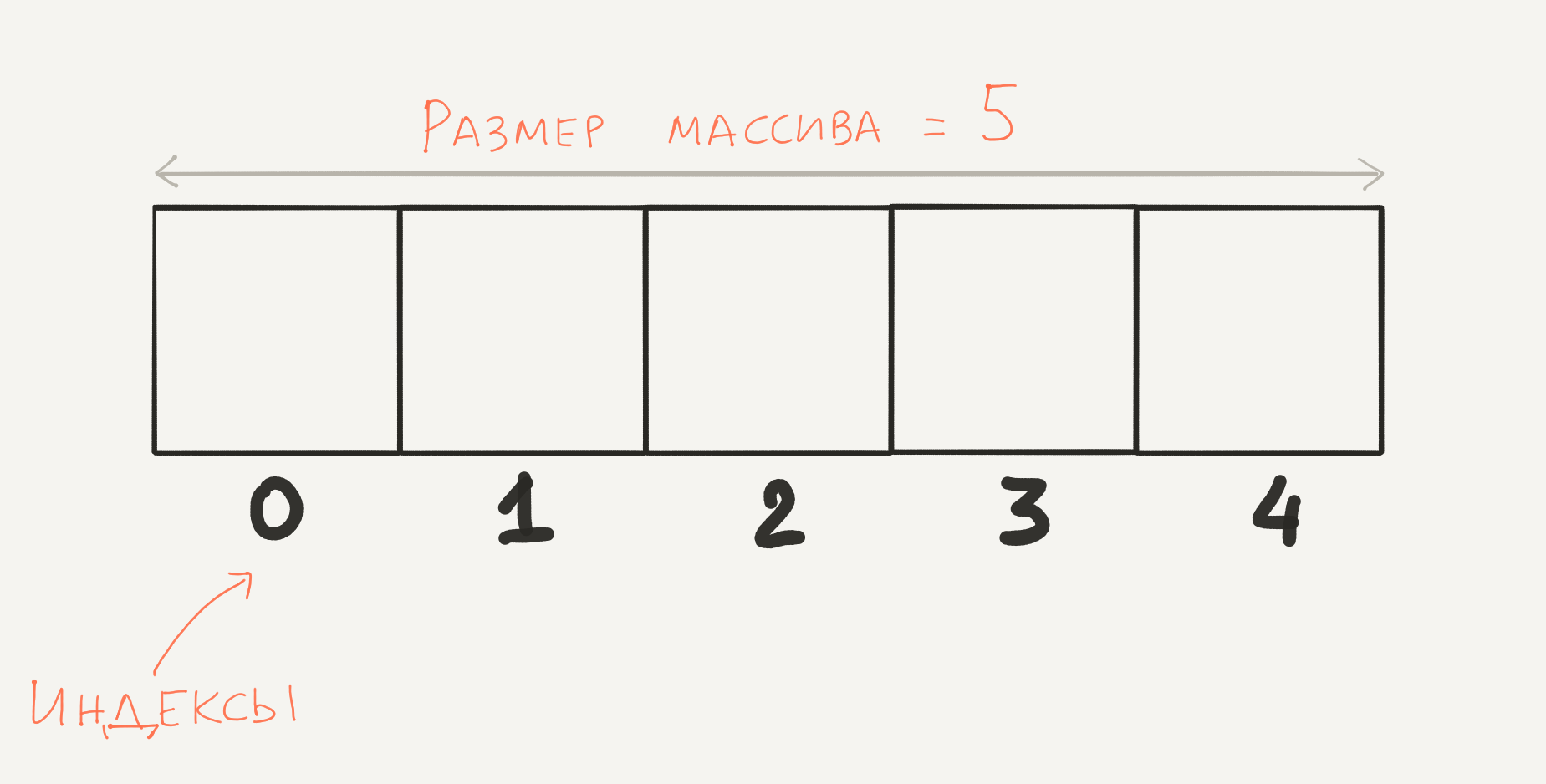
Каждый элемент в массиве имеет порядковый номер, называемый индексом . Индексация массива начинается с нуля. То есть первый элемент массива доступен по индексу 0 , второй — по индексу 1 , и так далее.
Для извлечения элемента из массива, необходимо использовать специальный синтаксис. Он заключается в том, что после переменной содержащей массив ставятся квадратные скобки с индексом между ними:
<?php
$animals = ['cats', 'dogs', 'birds'];
$animals[0]; // => cats
$animals[1]; // => dogs
$animals[2]; // => birds
Обратите внимание: последний индекс в массиве всегда меньше размера массива на единицу. Получить размер массива можно функцией sizeof или count :
<?php
$animals = ['cats', 'dogs', 'birds'];
sizeof($animals); // => 3
count($animals); // => 3
Что использовать - выбор за вами. Главное, выбрав один стиль - всегда его придерживайтесь.
В алгоритмических задачах индекс обычно вычисляется динамически, поэтому обращение к конкретному элементу происходит с использованием переменных:
<?php
$i = 1;
$animals = ['cats', 'dogs', 'birds'];
$animals[$i]; // => dogs
И даже так:
<?php
$i = 1;
$j = 1;
$animals = ['cats', 'dogs', 'birds'];
$animals[$i + $j]; // => birds
Такой вызов возможен по одной простой причине. Внутри скобок ожидается выражение , и, как мы уже знаем, там, где ожидается выражение, можно подставлять всё, что вычисляется, в том числе вызовы функций.
Довольно часто в задачах с использованием массивов нужно взять последний элемент. К сожалению, PHP не предоставляет для этого специальной функции (в языке Руби есть функция last , выполняющая данную задачу). Поэтому придется немного подумать над тем, как это сделать:
<?php
$animals = ['cats', 'dogs', 'birds'];
$animals[count($animals) - 1]; // => birds
Индекс последнего элемента вычисляется по формуле: размер массива - 1 . Соответственно, в коде она реализуется так: count($animals) - 1 . На практике очень напрягает каждый раз писать такой код, поэтому через некоторое время мы познакомимся со специальной библиотекой, позволяющей работать с коллекциями намного более эффективно по сравнению со стандартными средствами.
Выход за границу
При работе с массивами часто допускается ошибка, называемая «выход за границу массива». Она заключается в том, что из массива извлекается элемент по несуществующему индексу:
<?php
$animals = ['cats', 'dogs', 'birds'];
$animals[5]; // => null
В разных языках программирования поведение в случае выхода за границу реализовано совершенно по-разному. Иногда возникает ошибка, иногда возвращается undefined , как в JS, а иногда подобный выход возвращает случайные данные из соседнего блока памяти, как в Си, что может привести к катастрофе.
В PHP свой путь. С одной стороны такой вызов вернет null , с другой возникает ошибка (Notice) с примерно таким текстом: PHP Notice: Undefined offset: 5 . В общем случае, правильно всегда проверять доступность индекса и никогда не обращаться к массиву за его границами. Это безопасная стратегия, и вам будет проще адаптироваться к новым языкам, используя это универсальное решение.
Проверку наличия индекса в массиве можно сделать с помощью функции array_key_exists, которая первым параметром принимает индекс, а вторым массив для поиска.
<?php
$ages = [3, 2];
if (array_key_exists(3, $ages)) {
print_r('yeah!');
} else {
print_r('no');
}
// => no
Изменение элементов массива
Здесь все просто. Синтаксис такой же, как и при обращении к элементу массива с добавлением присвоения нового значения:
<?php
$animals = ['cats', 'dogs', 'birds'];
$animals[0] = 'horses';
print_r($animals); // => ['horses', 'dogs', 'birds']
Также не забывайте про выход за границу. Изменять нужно только существующие элементы.
Добавление элемента в массив
То же самое, что и изменение, но в качестве индекса ничего не указывается.
<?php
$animals = ['cats', 'dogs', 'birds'];
$animals[] = 'horses';
print_r($animals); // => ['cats', 'dogs', 'birds', 'horses']
Удаление элемента из массива
Для удаления элемента массива PHP предоставляет специальную инструкцию unset .
<?php
$animals = ['cats', 'dogs', 'birds'];
unset($animals[1]);
print_r($animals); // => ['cats', birds']
Синтаксически её применение выглядит как функция, но если вы попробуете использовать её как выражение, то PHP выдаст ошибку:
<?php
$animals = ['cats', 'dogs', 'birds'];
$result = unset($animals[1]); // => PHP Parse error: syntax error, unexpected 'unset' ...
В общем случае уменьшение размера массива — нежелательная операция. Подробнее об этом поговорим в соответствующем уроке.
Дополнительные материалы
PHP: Массивы → Цикл For
Работа с массивами практически всегда подразумевает итерацию по его элементам. Самый простой способ выполнить её — циклы.
Обход
В данном коде создается массив из трех элементов — имен. Далее в цикле происходит обход массива и вывод на экран всех имен, так, что каждое имя оказывается на новой строчке.
Рассмотрим этот этап подробнее. При обходе массива циклом for , как правило, счетчик играет роль индекса в массиве. Он инициализируется нулем и увеличивается до count($userNumbers) - 1 , что соответствует индексу последнего элемента.
Интересно производится печать на экран. Элемент массива может участвовать в строковой интерполяции, а значит мы можем сразу печатать и имя и перевод строки используя такую конструкцию "{$userNames[$i]}\n" .
А что, если нам нужно вывести значения в обратном порядке? Для этого есть два способа. Один — идти в прямом порядке, то есть от нулевого индекса до последнего, и каждый раз вычислять нужный индекс по такой формуле размер массива - 1 - текущее значение счетчика .
Но есть и другой способ. Можно просто идти от верхней границы к нижней. В такой ситуации код меняется на следующий:
<?php
$userNames = ['petya', 'vasya', 'evgeny'];
for ($i = count($userNames) - 1; $i >= 0; $i--) {
print_r("{$userNames[$i]}\n");
}
При таком обходе проверка остановки должна быть именно на >= , иначе пропустится элемент с индексом 0 .
Изменение
Сам цикл при изменении остается тем же самым, меняется только его тело. Предположим, что перед нами стоит задача нормализации списка емейлов. Допустим, в нормализацию писем входит приведение их к нижнему регистру. Тогда код будет выглядеть так:
Ключевая строчка: $emails[$i] = strtolower($emails[$i]); . В ней происходит перезапись элемента под индексом $i . Иногда полезно создать промежуточную переменную для упрощения анализа кода:
<?php
$email = $emails[$i];
$emails[$i] = strtolower($email);
Дополнительные материалы
PHP: Массивы → Обмен значений
Для изменения массива в алгоритмических задачках часто используется приём с введением третьей переменной. Такое бывает нужно когда значения в массиве меняются местами.
Реализуем функцию reverse , которая располагает значения в обратном порядке без создания нового массива. Хотя вариант с созданием нового массива предпочтительнее с точки зрения простоты и поддерживаемости кода, вариант без создания нового массива полезен для более полного понимания работы алгоритмов.
Алгоритм работы следующий: достаточно менять местами элементы, стоящие зеркально относительно центра. А вот и код:
Первое, с чем нужно разобраться в данном алгоритме — до какого индекса двигаться, производя обмен. Достаточно очевидно, что это середина массива, но что делать, если в массиве нечетное количество элементов? В такой ситуации после реверса центральный элемент останется на своем месте, а значит, что при нечетном числе элементов можно округлять результат деления до нижней границы. То есть, если в массиве 5 элементов, то нужно 5 поделить на 2 и округлить до ближайшего числа снизу, то есть до 2. В php для округления вниз есть встроенная функция floor . Соответственно само вычисление выглядит так floor(count($coll) / 2); . Этот код работает универсально для массивов с четным и нечетным числом элементов.
Внутри тела цикла происходит самое интересное. Нам нужно поменять два значения местами. Если попытаться сразу одному значению присвоить другое, то мы потеряем исходное значение. Поэтому, предварительно нужно сохранить значение во временную переменную $temp = $coll[$i]; . Затем происходит вычисление индекса находящегося на зеркальной позиции и последующий обмен значениями.
Введение временной переменной для промежуточного хранения результата — распространенный прием в алгоритмических задачах, который помогает выполнять обмен значениями.
PHP: Массивы → Массивы в памяти комьютера
Работая на таких высокоуровневых языках как php, позволительно не знать устройство массивов для решения повседневных задач. С другой стороны, подобное понимание делает код менее магическим и дает возможность заглядывать чуть дальше.
Реальные массивы лучше всего рассматривать на языке C , который, с одной стороны, достаточно простой и понятный, с другой - очень близок к железу и не скрывает от нас практически ничего. Когда мы говорим про примитивные типы данных, такие как “строка” или “число”, то, на интуитивном уровне, все довольно понятно. Под каждое значение выделяется некоторый размер памяти (в соответствии с типом), в которой и хранится само значение. А как должна выделиться память под хранение массива? И что такое массив в памяти? На уровне хранения, понятия массив - не существует. Массив представляется цельным куском памяти, размер которого вычисляется по формуле “количество элементов * количество памяти под каждый элемент”. Из этого утверждения есть два интересных вывода:
- Размер массива - фиксированная величина. Те динамические массивы, с которыми мы имеем дело во многих языках, реализованы уже внутри языка, а не на уровне железа.
- Все элементы массива имеют один тип и занимают одно и тоже количество памяти. Благодаря этому появляется возможность простым умножением (по формуле, описанной выше) получить адрес той ячейки, в которой лежит нужный нам элемент. Именно это происходит под капотом, при обращении к элементу массива под определенным индексом.
Фактически индекс в массиве - смещение относительно начала куска памяти содержащего данные массива. Высчитывается он так: “индекс * количество памяти занимаемое одним элементом (для данного типа данных)”. Пример на C:
// Инициализация массива из пяти элементов типа int
int mark[] = {19, 10, 8, 17, 9};
mark[3]; // 17
Если предположить, что тип int занимает в памяти 2 байта (зависит от архитектуры), то адрес элемента, соответствующего индексу 3 , высчитается так: “начальный адрес + индекс * объем памяти для одного элемента типа int”.
Теперь должно быть понятно почему индексы в массиве начинаются с нуля. 0 - означает отсутствие смещения .
Безопасность
В отличие от высокоуровневых языков, в которых код защищен от выхода за границу массива, в таком языке как C , выход за границу не приводит к ошибкам. Обращение к элементу, индекс которого находится за пределами массива, вернет данные, которые лежат в той самой области памяти, куда его попросили обратиться (в соответствии с формулой выше). Чем они окажутся - никому не известно (но они будут проинтерпретированы в соответствии с типом массива. Если массив имеет тип int, то вернется число). Благодаря отсутствию какой-либо защиты выход за границу массива активно эксплуатируется хакерами для взлома программ.
PHP: Массивы → Агрегация
Еще один распространенный вариант использования циклов на массивах — агрегация . Агрегацией являются любые вычисления, которые строятся на основе всего набора данных, например, поиск максимального, среднего, суммы и так далее.
Алгоритм поиска максимального числа в массиве выглядит так:
- Если массив пустой, то возвращаем
null. Это классический пример использования идиомы guard expression - В ином случае берем за точку отсчета первый элемент массива и считаем его максимальным.
- Обходим массив, начиная со второго элемента и сравниваем каждое значение с максимальным. Если текущий рассматриваемый элемент больше максимального, то он становится максимальным.
- После обхода возвращаем результат.
Главное, что нужно увидеть в этом коде — место определения переменной $max . Новички часто забывают про то, что переменную нужно определить до её использования. Внутри цикла переменные определять нельзя. Это нужно делать до цикла. В большинстве языков переменные, определенные внутри блока кода (тело цикла в нашем случае) видны только внутри этого блока, то есть их область видимости ограничивается блоком кода. Соответственно, получить доступ к этим переменным вне блока невозможно.
Обратите внимание, что начальным значением $max взят первый элемент, а не, скажем, 0 . Ведь может оказаться так, что все числа в массиве меньше 0 , и тогда мы получим неверный ответ.
Второй важный момент: возврат делается только после обхода всего массива. Если бы return был внутри цикла, то массив не был бы рассмотрен целиком. Такая ошибка часто встречается у новичков.
Нейтральный элемент
Рассмотрим поиск суммы:
Алгоритм поиска суммы значительно проще, но обладает парой важных нюансов.
Чему равна сумма элементов пустого массива? С точки зрения математики такая сумма равна 0 . Что в принципе совпадает со здравым смыслом. Если у нас нет яблок, значит у нас есть 0 яблок (количество яблок равно нулю).
Второй момент связан с начальным элементом суммы. В коде используется 0 или так называемый нейтральный элемент операции сложения на множестве вещественных чисел. Нейтральный элемент бинарной операции — элемент, который ничего не меняет в результате его использования в бинарной операции. По простому, сложение любого числа с нулем всегда дает это же число. Тогда любую сумму, например 3 + 2 + 8 , можно вычислить как 0 + 3 + 2 + 8 , чем мы и пользуемся в нашем коде.
Агрегация далеко не всегда означает что, коллекция элементов сводится к некоторому простому значению. Результатом агрегации может быть сколь угодно сложная структура, например, массив. Подобные примеры часто встречаются в реальной жизни и будут ещё рассмотрены позже.
PHP: Массивы → Цикл Foreach
В типичных задачах, связанных с массивами, цикл for избыточен и многословен. Поэтому php предлагает альтернативу — цикл foreach :
<?php
$userNames = ['petya', 'vasya', 'evgeny'];
foreach ($userNames as $name) {
print_r("{$name}\n");
}
foreach значительно проще for . В нем отсутствует счетчик, его проверка и изменение. foreach берет всю грязную работу целиком на себя. Всё, что надо сделать программисту — назвать переменную для каждого элемента.
У foreach есть и другой вариант использования. Если нам понадобятся индексы массива, то запись станет такой:
<?php
$userNames = ['petya', 'vasya', 'evgeny'];
foreach ($userNames as $index => $name) {
print_r("{$index}: {$name}\n");
}
Теперь после as идет название ключа, а значение помещается после => .
В большинстве реальных задач используется как раз foreach , но иногда его бывает недостаточно, и требуется ручное управление обходом. В таких задачах можно возвращаться к использованию for .
PHP: Массивы → Управляющие инструкции
В циклах PHP доступны для использования две инструкции, влияющие на их поведение: break и continue . Впрочем, на практике они используются редко. Ту же функциональность легко получить и без их использования, но знать про них нужно, особенно при чтении чужого кода.
Break
Инструкция break производит выход из цикла . Не из функции, а из цикла. То есть, встретив её, интерпретатор перестаёт выполнять текущий цикл и переходит к инструкциям, идущими сразу за циклом.
<?php
$coll = ['one', 'two', 'three', 'four', 'stop', 'five'];
foreach ($coll as $item) {
if ($item == 'stop') {
break;
}
print_r($item);
}
Тоже самое легко получить, используя цикл while , который, кстати говоря, семантически лучше подходит для такой задачи, так как он подразумевает не полный перебор.
<?php
$coll = ['one', 'two', 'three', 'four', 'stop', 'five'];
$i = 0;
while ($coll[$i] != 'stop') {
print_r($coll[$i]);
$i++;
}
Continue
Инструкция continue позволяет пропустить итерацию цикла. Ниже пример с функцией myCompact , которая удаляет null элементы из массива:
<?php
function myCompact($coll)
{
$result = [];
foreach ($coll as $item) {
if (is_null($item)) {
continue;
}
$result[] = $item;
}
return $result;
}
Код без continue получается проще:
<?php
function myCompact($coll)
{
$result = [];
foreach ($coll as $item) {
if (!is_null($item)) {
$result[] = $item;
}
}
return $result;
}
Дополнительные материалы
PHP: Массивы → Удаление элементов массива
Несмотря на то, что из массива можно удалить элемент, лучше так никогда не делать. Особенно плохо изменять массив во время обхода. Как удалять, так и добавлять элементы. Поведение в этом случае может оказаться совершенно непредсказуемым. Что будет, если мы модифицируем массив в том месте, до которого не дошел цикл? Нужно ли итерировать по тому элементу, который был удален или добавлен? Правильный выход из ситуации — создание нового массива. Такой код проще и для понимания и для отладки.
В стандартную библиотеку большинства языков программирования входит функция compact , которая удаляет все null из массива. Вот ее реализация:
Главное, на что нужно обратить внимание, не происходит никаких удалений и модификаций исходного массива. Вместо этого инициализируется новый массив, который наполняется только подходящими под условие значениями. Именно так нужно воспринимать фразу “удалить из массива что-то”. Код с созданием нового массива меньше подвержен ошибкам, проще в отладке и оставляет больше возможностей для анализа. Вы всегда можете посмотреть исходный массив, если что-то пошло не так. Вы всегда можете наблюдать за процессом наполнения результирующего массива, что позволит четко отследить правильность поставленных условий.
По сути, код выше — пример агрегации. Только в отличие от предыдущих примеров, в которых результатом был примитивный тип, здесь результат — массив. Это совершенно нормально. Как вы увидите в дальнейшем, результат может быть и более сложной структурой. Сама операция прореживания массива обычно называется фильтрацией .
PHP: Массивы → Вложенные массивы
Значением массива может быть все, что угодно, в том числе массив. В этом случае синтаксис может выглядеть немного необычно, поэтому разберем его отдельным уроком. Создать массив в массиве можно так:
<?php
$arr1 = [[3]];
count($arr1); // => 1
$arr2 = [1, [3, 2], [3, [4]]];
count($arr2); // => 3
Каждый элемент, являющийся массивом, рассматривается как единое целое, что видно по размеру второго массива. Вложенность никак не ограничивается. Можно создавать массив массивов массивов и т. д.
Обращение ко вложенным массивам выглядит уже немного необычно, хотя и логично:
<?php
$arr1 = [[3]];
$arr1[0][0]; // => 3
$arr2 = [1, [3, 2], [3, [4]]];
$arr2[2][1][0]; // => 4
Возможно, с непривычки вы не всегда сразу точно увидите, как добраться до нужного элемента, но это всего лишь вопрос тренировок.
Изменение и добавление массивов в массив выполняется без сюрпризов. Все, что меняется - значение справа становится массивом:
<?php
$arr1 = [[3]];
$arr1[0] = [2, 10];
$arr1[] = [3, 4, 5];
// [[2, 10], [3, 4, 5]]
Вложенные массивы можно изменять напрямую, просто обратившись к нужному элементу:
<?php
$arr1 = [[3]];
$arr1[0][0] = 5;
// [[5]]
Тоже самое касается и добавления нового элемента:
<?php
$arr1 = [[3]];
$arr1[0][] = 10;
// [[3, 10]]
PHP: Массивы → Генерация строки в цикле
Генерация строк в циклах — задача, часто возникающая на практике. Типичный пример в вебе, функция-хелпер, помогающая генерировать html списки в шаблонах. Она принимает на вход коллекцию элементов и возвращает список из них:
<?php
$coll = ['milk', 'butter', 'eggs', 'bread'];
buildList($coll);
// => <ul><li>milk</li><li>butter</li><li>eggs</li><li>bread</li></ul>
Самый примитивный алгоритм, который приходит в голову. Пройтись циклом по элементам коллекции и дописать в результирующую строку очередной li элемент. В начале и конце добавить ul и вернуть строчку наружу.
<?php
$result = '';
foreach ($coll as $item) {
$result .= "<li>{$item}</li>";
// либо так
// $result = "{$result}<li>{$item}</li>";
}
$result = "<ul>{$result}</ul>";
Такой способ вполне рабочий, но для большинства языков программирования максимально не эффективный. Дело в том, что конкатенация и интерполяция порождают новую строчку вместо старой и подобная ситуация повторяется на каждой итерации. Причем строка становится все больше и больше. Копирование строк приводит к серьезному расходу памяти и может влиять на производительность. Конечно, для большинства приложений данная проблема не актуальна из-за малого объема прогоняемых данных, но более эффективный подход не сложнее в реализации и обладает дополнительными плюсами. Поэтому стоит сразу приучить себя работать правильно и никогда больше не возвращаться к этому вопросу. В статических языках для подобной цели используется так называемый String Buffer. В динамических — обычный массив. Перепишем программу выше, используя новое знание:
<?php
$parts = []; // переименовал для того, чтобы не менять значения переменной
foreach ($coll as $item) {
$parts[] = "<li>{$item}</li>";
}
$innerValue = implode(' ', $parts);
$result = "<ul>{$innerValue}</ul>";
Как видите, код не сильно поменялся. Разница в том, что теперь собирается массив вместо строки, и в конце он собирается в строку с помощью implode . Помимо эффективности у такого подхода есть дополнительные плюсы:
- Такой код проще отлаживать и анализировать внутренности
- Массив можно дообработать, если надо, а строчку — уже нет
Дополнительные материалы
PHP: Массивы → Обработка строк через преобразование в массив
Иногда на собеседованиях я задаю такую задачку:
Дана строка текста. Нужно сделать заглавной первую букву каждого слова в тексте. На любые хитрые вопросы «а есть ли в строке знаки препинания» ответ — выбирайте самый простой случай для обработки.
Решить её можно достаточно большим количеством способов. Чем больше называет человек, тем лучше. К ним относятся:
- Посимвольный перебор строки. Эта задачка может быть решена двумя способами. Один из которых связан с использованием конечных автоматов, которым будет посвящен отдельный курс впереди.
- Регулярные выражения. Про них также есть отдельный курс.
- Через преобразование в массив. Этот способ тоже распадается на два. Одно решение через функции высших порядков мы рассмотрим в следующих курсах, а пока исследуем решение через цикл.
Первым делом нужно превратить строку в массив. Для этого мы воспользуемся функцией explode , которая разделяет строку, используя указанный разделитель. В нашем случае разделителем является пробел.
<?php
function capitalizeWords($sentence)
{
$words = explode(' ', $sentence);
// ...
}
Теперь, используя цикл, легко выполнить операцию capitalize , то есть приведение первой буквы каждого слова к верхнему регистру.
<?php
function capitalizeWords($sentence)
{
$words = explode(' ', $sentence);
for ($i = 0; $i < count($words); $i++) {
$words[$i] = ucfirst($words[$i]);
}
// ...
}
Последнее действие обратно первому. Нужно соединить слова и вернуть получившуюся строку наружу. Для соединения элементов массива в PHP используется функция implode . Она, как и explode , принимает на вход разделитель, который теперь используется для сборки строки.
В случае, если строчку нужно разбить по символам, а не по словам, можно воспользоваться функцией str_split .
<?php
$chars = str_split($text);
foreach ($chars as $char) {
print_r($char);
}
str_split принимает второй параметр, в котором можно указать количество символов в каждой группе (элементе получившегося массива). По умолчанию используется число 1, поэтому мы получаем массив, в котором каждый элемент — один символ. Но, если указать, например, 3, то в каждом элементе массива будет по три символа.
<?php
$text = 'Hello Friend';
$arr2 = str_split($str, 3);
print_r($arr1);
// Array
// (
// [0] => Hel
// [1] => lo
// [2] => Fri
// [3] => end
// )
PHP: Массивы → Вложенные циклы
Во многих языках программирования есть очень полезная функция flatten . В определенных задачах она сильно упрощает жизнь и сокращает количество кода. flatten принимает на вход массив и выправляет его: если элементами массива являются массивы, то flatten сводит все к одному массиву, раскрывая каждый вложенный.
Посмотрим на пример:
<?php
flatten([[3, 2], 5, 3, [3, [4, 2]], 10]);
// => [3, 2, 5, 3, 3, 4, 2, 10]
Давайте напишем функцию flatten . В общем случае эта функция раскрывает массивы на всех уровнях вложенности. Но мы для простоты сделаем вариант функции, в котором происходит раскрытие только до первого уровня. То есть, если элемент основного массива — массив, то он раскрывается без просмотра его внутренностей (там тоже могут быть массивы).
Логика работы функции выглядит так:
- Инициализируем массив-результат, в который запишутся все значения.
- Итерируем (проходим) по основному массиву и проверяем текущий элемент.
- Если текущий элемент — не массив, то добавляем его в массив-результат и идём дальше.
- Если текущий элемент — массив, то начинаем вложенный цикл, внутри которого идем по массиву и добавляем каждый его элемент в массив-результат.
- Возвращаем массив-результат.
Обратите внимание, что вложенный цикл запускается, только если текущий элемент — массив. Чисто технически во вложенных циклах нет ничего особенного. Их можно вкладывать внутрь любого блока и друг в друга сколько угодно раз. Но прямой связи между внешним и вложенным нет. Внутренний цикл может использовать результаты внешнего, а может и работать по своей собственной логике независимо.
Вложенные циклы коварны. Их наличие может резко увеличить сложность кода и в особо тяжелых случаях значительно замедлить его. В тех местах, где можно от них избавиться, лучше от них избавляться.
Для реализации функции flatten лучше использовать слияние массивов, которое мы рассмотрим в одном из следующих уроков. Если же от вложенных циклов уйти не получается, то с высокой вероятностью их можно вынести в отдельную функцию.
<?php
function concat($result, $items)
{
foreach ($items as $item) {
$result[] = $item;
}
return $result;
}
function flatten($coll)
{
$result = [];
foreach ($coll as $item) {
if (is_array($item)) {
$result = concat($result, $item);
} else {
$result[] = $item;
}
}
return $result;
}
print_r(flatten([3, 2, [], [3, 4, 2], 3, [123, 3]]));
PHP: Массивы → Теория Множеств
Теория множеств. Знаю, как многие пугаются математики, но конкретно теория множеств (наивная) очень проста и понятна. Более того, мы постоянно используем её элементы в обычной жизни. А уж в программировании она встречается на каждом шагу.
Основное понятие теории множеств, как ни удивительно — множество . Множеством обозначают совокупность объектов произвольной природы, рассматривающихся как единое целое. Простейший пример — цифры. Множество арабских цифр включает в себя 10 элементов и является конечным . Понятие конечности носит интуитивный характер и обозначает, что в множестве конечное число элементов.
Пример бесконечного множества — натуральные числа. В свою очередь множество натуральных чисел является подмножеством целых чисел, которые в свою очередь являются подмножеством рациональных чисел и так далее.
«Подмножество» означает, что все элементы одного множества также входят в другое множество, называемое надмножеством (по отношению к подмножеству).

Представление множеств кружками довольно удобно. Можно быстро оценить как друг с другом соотносятся разные множества.
Но математические объекты, такие как числа, не единственные возможные объекты множеств. Множеством можно назвать всех людей, стоящих на остановке в ожидании своего автобуса, или жильцов квартир одного дома, города или страны. Любой набор любых объектов, которые мы хотим рассматривать как одно целое.
Главное для нас в теории множеств — операции над ними. К ним относятся: дополнение, объединение, пересечение, разность, декартово произведение и некоторые другие.
Простой пример. Когда в Фейсбуке вы заходите на страницу другого человека, то Фейсбук показывает вам блок с общими друзьями. Если принять, что ваши друзья и друзья вашего друга — два множества, то общие друзья — множество, полученное как пересечение исходных множеств друзей.
Переходя к программированию, можно заметить, что массив очень похож на множество, и его действительно можно так рассматривать. Почему это так важно? Понимая принципы, на которых основаны некоторые операции, вы сможете реализовывать их наиболее быстрым и эффективным способом. Например, зная, что вам нужна операция пересечения множеств в php, вы можете попытаться найти функцию, которая делает поставленную задачу. Для этого достаточно ввести в гугл запрос: php set intersect (set — множество, intersect — пересечение). Первая (по крайней мере, у меня) ссылка в поисковой выдаче ведет на нужную функцию array_intersect . Тоже самое вас ждет и с другими операциями. Это частичный ответ на вопрос «нужна ли математика программистам?».
Кстати, не во всех языках есть встроенные функции для работы со множествами. В некоторых для этого нужно ставить дополнительные библиотеки, а в некоторых, например, в Ruby, операции со множествами реализованы с использованием арифметических операторов (объединение множеств: coll1 + coll2 ).
Отдельно стоит сказать, что реляционные базы данных построены на идеях реляционной алгебры, в которой теория множеств играет центральную роль. Базы данных — неотъемлемая часть веб-разработки, и позже мы с ними познакомимся.
Рассмотрим основные операции:
Пересечение
Пересечением множеств называется множество, в которое входят элементы, встречающиеся во всех данных множествах одновременно.
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
array_intersect($friends1, $friends2); // => ['vasya', 'petya']
Эта функция принимает любое количество массивов. То есть вы можете находить пересечение любого количества массивов за один вызов.
Объединение
Объединением множеств называется множество, в которое входят элементы всех данных множеств. Объединение множеств в php нельзя сделать одним вызовом, но его можно имитировать, соединив две функции:
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
// merge выполняет слияние двух массивов, в отличие от объединения, в нем повторяются элементы которые встречаются там и там (а не должны)
$friends = array_merge($friends1, $friends2);
// => ['vasya', 'kolya', 'petya', 'igor', 'petya', 'sergey', 'vasya', 'sasha'];
// unique удаляет дубли
$sharedFriends = array_unique($friends);
// => ['vasya', 'kolya', 'petya', 'igor', 'sergey', 'sasha']
Дополнение (разность)
Разностью двух множеств называется множество, в которое входят элементы первого множества, не входящие во второе. В программировании такая операция часто называется diff .
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
array_diff($friends1, $friends2); // => ['kolya']
Принадлежность множеству
Проверку принадлежности элемента множеству можно выполнить с помощью функции in_array :
<?php
$terribleNumbers = [4, 13];
if (in_array(10, $terribleNumbers)) {
print_r('woah!');
}
Дополнительные материалы
PHP: Массивы → Теория Множеств
Теория множеств. Знаю, как многие пугаются математики, но конкретно теория множеств (наивная) очень проста и понятна. Более того, мы постоянно используем её элементы в обычной жизни. А уж в программировании она встречается на каждом шагу.
Основное понятие теории множеств, как ни удивительно — множество . Множеством обозначают совокупность объектов произвольной природы, рассматривающихся как единое целое. Простейший пример — цифры. Множество арабских цифр включает в себя 10 элементов и является конечным . Понятие конечности носит интуитивный характер и обозначает, что в множестве конечное число элементов.
Пример бесконечного множества — натуральные числа. В свою очередь множество натуральных чисел является подмножеством целых чисел, которые в свою очередь являются подмножеством рациональных чисел и так далее.
«Подмножество» означает, что все элементы одного множества также входят в другое множество, называемое надмножеством (по отношению к подмножеству).
Представление множеств кружками довольно удобно. Можно быстро оценить как друг с другом соотносятся разные множества.
Но математические объекты, такие как числа, не единственные возможные объекты множеств. Множеством можно назвать всех людей, стоящих на остановке в ожидании своего автобуса, или жильцов квартир одного дома, города или страны. Любой набор любых объектов, которые мы хотим рассматривать как одно целое.
Главное для нас в теории множеств — операции над ними. К ним относятся: дополнение, объединение, пересечение, разность, декартово произведение и некоторые другие.
Простой пример. Когда в Фейсбуке вы заходите на страницу другого человека, то Фейсбук показывает вам блок с общими друзьями. Если принять, что ваши друзья и друзья вашего друга — два множества, то общие друзья — множество, полученное как пересечение исходных множеств друзей.
Переходя к программированию, можно заметить, что массив очень похож на множество, и его действительно можно так рассматривать. Почему это так важно? Понимая принципы, на которых основаны некоторые операции, вы сможете реализовывать их наиболее быстрым и эффективным способом. Например, зная, что вам нужна операция пересечения множеств в php, вы можете попытаться найти функцию, которая делает поставленную задачу. Для этого достаточно ввести в гугл запрос: php set intersect (set — множество, intersect — пересечение). Первая (по крайней мере, у меня) ссылка в поисковой выдаче ведет на нужную функцию array_intersect . Тоже самое вас ждет и с другими операциями. Это частичный ответ на вопрос «нужна ли математика программистам?».
Кстати, не во всех языках есть встроенные функции для работы со множествами. В некоторых для этого нужно ставить дополнительные библиотеки, а в некоторых, например, в Ruby, операции со множествами реализованы с использованием арифметических операторов (объединение множеств: coll1 + coll2 ).
Отдельно стоит сказать, что реляционные базы данных построены на идеях реляционной алгебры, в которой теория множеств играет центральную роль. Базы данных — неотъемлемая часть веб-разработки, и позже мы с ними познакомимся.
Рассмотрим основные операции:
Пересечение
Пересечением множеств называется множество, в которое входят элементы, встречающиеся во всех данных множествах одновременно.
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
array_intersect($friends1, $friends2); // => ['vasya', 'petya']
Эта функция принимает любое количество массивов. То есть вы можете находить пересечение любого количества массивов за один вызов.
Объединение
Объединением множеств называется множество, в которое входят элементы всех данных множеств. Объединение множеств в php нельзя сделать одним вызовом, но его можно имитировать, соединив две функции:
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
// merge выполняет слияние двух массивов, в отличие от объединения, в нем повторяются элементы которые встречаются там и там (а не должны)
$friends = array_merge($friends1, $friends2);
// => ['vasya', 'kolya', 'petya', 'igor', 'petya', 'sergey', 'vasya', 'sasha'];
// unique удаляет дубли
$sharedFriends = array_unique($friends);
// => ['vasya', 'kolya', 'petya', 'igor', 'sergey', 'sasha']
Дополнение (разность)
Разностью двух множеств называется множество, в которое входят элементы первого множества, не входящие во второе. В программировании такая операция часто называется diff .
<?php
$friends1 = ['vasya', 'kolya', 'petya'];
$friends2 = ['igor', 'petya', 'sergey', 'vasya', 'sasha'];
array_diff($friends1, $friends2); // => ['kolya']
Принадлежность множеству
Проверку принадлежности элемента множеству можно выполнить с помощью функции in_array :
<?php
$terribleNumbers = [4, 13];
if (in_array(10, $terribleNumbers)) {
print_r('woah!');
}
Дополнительные материалы
PHP: Массивы → Сортировка массивов
Сортировка массивов — самая базовая алгоритмическая задача, которую нередко спрашивают на собеседованиях. С другой стороны, в реальном коде массивы сортируют, используя уже готовые функции стандартной библиотеки. Тогда для чего задают подобные вопросы? Обычно собеседующий хочет узнать следующее:
- Насколько вы вообще в курсе о существовании алгоритмов.
- Способны ли вы программировать.
- Как работает ваше алгоритмическое мышление.
Знание алгоритмов действительно влияет на то, как вы думаете и насколько быстро соображаете. И хотя невозможно знать все алгоритмы, нужно хотя бы иметь представление о самых ключевых и, в идеале, уметь их реализовывать. В нашем списке рекомендуемых книг есть как минимум одна книга, полностью посвященная алгоритмам.
Кроме того, Роберт Мартин (авторитетный программист, по книгам которого образовывается весь мир) в своей книге «Идеальный программист» рассказывает о подходе Ката — понятии, взятом из боевых искусств.
Принцип изучения боевого искусства на основе ката состоит в том, что повторяя ката многие тысячи раз, практик боевого искусства приучает своё тело к определённого рода движениям, выводя их на бессознательный уровень. Таким образом, попадая в боевую ситуацию, тело работает «само» на основе рефлексов, вложенных многократным повторением ката. Также считается, что ката обладают медитативным воздействием.
Роберт рекомендует время от времени решать классические алгоритмические задачки для поддержания формы. Эта тема стала настолько популярной, что если загуглить php github kata , то вы увидите множество репозиториев с подобными задачками.
Сортировка
Способов сортировать массив достаточно много. Самый популярный для обучения — пузырьковая сортировка (bubble sort).
Алгоритм состоит из повторяющихся проходов по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются N-1 раз или до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При каждом проходе алгоритма по внутреннему циклу, очередной наибольший элемент массива ставится на своё место в конце массива рядом с предыдущим «наибольшим элементом», а наименьший элемент перемещается на одну позицию к началу массива («всплывает» до нужной позиции, как пузырёк в воде. Отсюда и название алгоритма).
В интернете можно найти сервисы, визуализирующие процесс сортировки, что очень помогает пониманию, например:
- zenozeng.github.io/bubble-sort-visualization/
- sorting.at/
- visualgo.net/ru/sorting
- www.cs.usfca.edu/~galles/visualization/ComparisonSort.html
Весь код делится на два уровня:
- Внутренний цикл
for, который проходит по массиву от начала до конца, меняя элементы попарно, если нужно сортировать. - Внешний цикл
while..do, определяющий, когда нужно остановиться. Обратите внимание, что в худшем случае этот цикл выполнитсяcount($arr)раз, что совпадает с теоретическим худшим случаем этого алгоритма, при котором самый большой или маленький элемент находятся в противоположных конце массива от сортированного варианта.
Хотя мы и меняем входной массив напрямую, это никак не скажется на массиве, который был передан внутрь функции. Он останется точно таким же, каким и был до входа в функцию. По сути внутри мы работаем с копией, которую и возвращаем наружу после сортировки.
Дополнительные материалы
PHP: Массивы → Ссылки
Большинство функций, работающих с массивами, после обработки возвращают новый массив. Но некоторые работают по-другому. В этих функциях, как правило, не используется возврат. Они меняют исходный массив напрямую за счет использования ссылок. К таким функциям, например, относится функция сортировки:
Обратите внимание на то что мы не пишем $sortedArray = sort($arr) . Функция sort не возвращает отсортированный новый массив, вместо этого, она меняет тот массив, на который ссылается $arr .
<?php
$data = [1, 3, 4];
$result = sort($data);
print_r($result); // => 1
Кроме прочего, такие функции не умеют работать с литералами, так как на них нельзя получить ссылки:
<?php
print_r(sort([1, 3, 4]));
// PHP Fatal error: Only variables can be passed by reference
С точки зрения устройства, такие функции выглядят следующим образом:
<?php
function addValueToArray(&$array, $value)
{
$array[] = $value;
}
В сигнатуре функции, перед именем переменной, ставится знак & , а в теле функции происходит прямое изменение без возврата.
Возникает вопрос, как лучше проектировать функции: с передачей по ссылке или по значению. В подавляющем большинстве случаев предпочтителен второй вариант. Функции возвращающие значения удобнее в работе и поведение программы становится, в целом, более предсказуемое, так как отсутствуют неконтролируемые изменения данных. Первый подход лучше просто никогда не использовать. Не забудьте прочитать http://optimization.guide.
Несмотря на то, что подход, меняющий массивы напрямую, сложнее в отладке, его используют в некоторых языках для увеличения эффективности работы. Если массив достаточно большой, то полное копирование окажется дорогой операцией. В реальной жизни (веб разработчика) это почти никогда не проблема, но знать об этом полезно.
Дополнительные материалы
PHP: Массивы → Стек
Алгоритмы — это хорошо, но структуры данных — ещё лучше.
Структура данных — это конкретный способ хранения и организации данных . В зависимости от решаемых задач, удобным оказывается либо один способ организации данных, либо другой. Как минимум, одну структуру данных вы уже знаете достаточно хорошо — это массив. С точки зрения организации, массив представляет собой совокупность элементов, к которым имеется индексированный доступ (доступ по индексу), а вот с точки зрения хранения — все сложнее. Массивы бывают разные и внутри языка реализуются тоже по-разному.
Каноническая организация хранения массива — непрерывный блок памяти. А индекс в таком случае играет роль смещения по ней. Именно поэтому индексация в массивах начинается с нуля, так как указывает на начало этого блока, а индекс под номером 1 уже является смещением. Но на практике все сложнее. В PHP нет настоящих массивов. Об этом вы узнаете в следующем курсе.
Кроме массивов существует множество других структур данных, таких как списки, хеш-таблицы, деревья, графы, стек, очередь и другие. Использование структуры данных, подходящей под решаемую задачу, позволяет кардинально упростить код, устраняя запутанную логику.
Некоторые из перечисленных структур данных мы рассмотрим в процессе прохождения курсов и проектов, другие вам нужно будет подтянуть самостоятельно из книг (книги лучше, чем статьи). В любом случае алгоритмы и структуры данных (без фанатизма) составляют базу, на которую нанизывается все остальное в разработке.
Стоит разделять три понятия:
- Структура данных
- Конкретный тип данных (или просто «тип данных»)
- Абстрактный тип данных
Со структурой данных все понятно, выше было определение. С типом данных тоже все просто. Например, массив в PHP — это тип данных . Понятие «тип данных» всегда привязано к конкретному языку и может быть абсолютно чем угодно в зависимости от предпочтений разработчиков языка. Другими словами если бы разработчики PHP решили, что числа надо назвать типом данных Array, то никто бы им этого не запретил, несмотря на абсурдность такого имени для чисел. Кроме встроенных типов данных, бывают и пользовательские. Так, PHP позволяет создавать интерфейсы и классы, но об этом мы поговорим чуть позже.
А вот АТД — теоретическое понятие. АТД целиком и полностью определяется набором операций, которые можно выполнять над ним. АТД абстрактный потому, что он ничего не говорит о способе хранения и существует лишь на бумаге и в головах. А вот уже в конкретных языках существуют конкретные типы, реализующие АТД.
АТД нередко путают с понятием «структура данных», более того, часто, структуры данных и АТД имеют одно и тоже название.
Стек
Стек — упорядоченная коллекция элементов, в которой добавление новых и удаление старых элементов всегда происходит с одного конца коллекции. Обычно его называют вершиной стека.
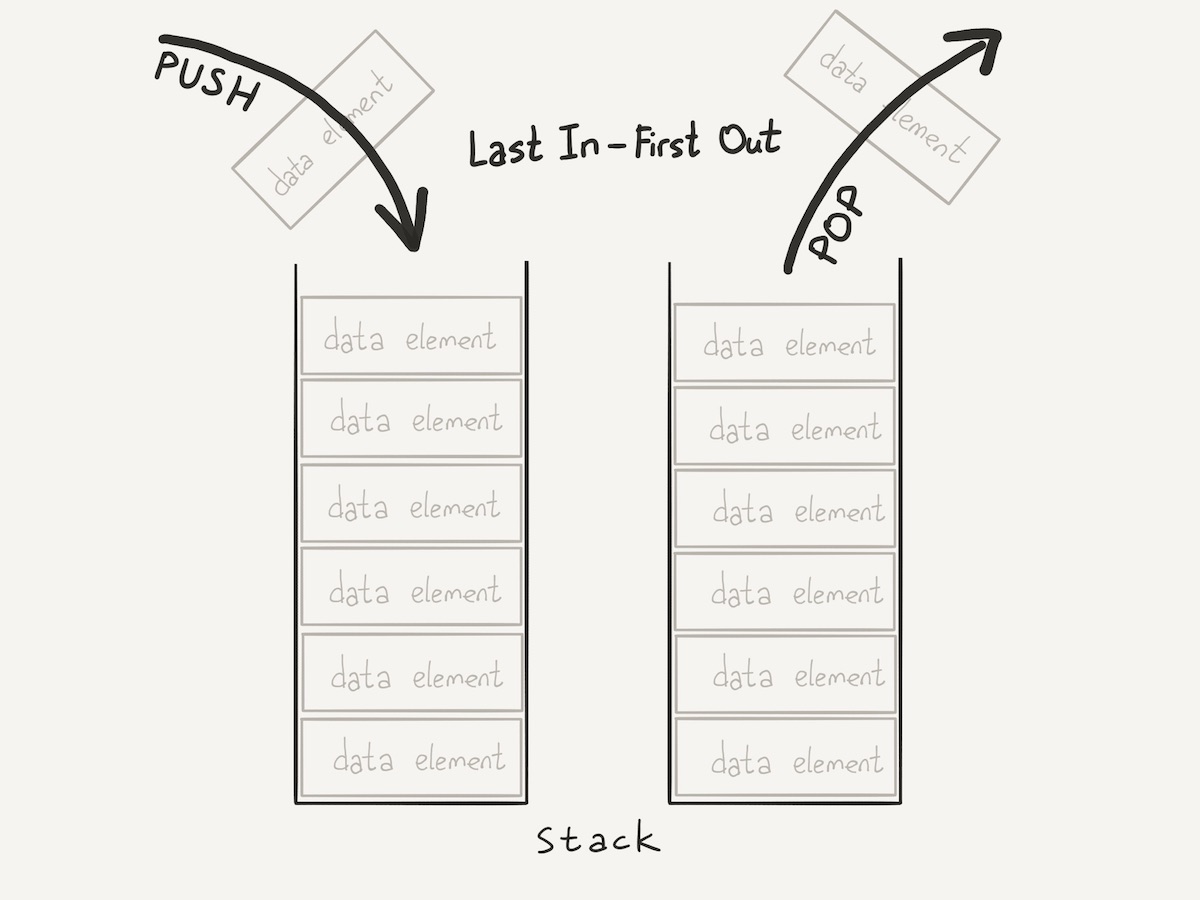
У стека есть аналоги из реальной жизни. Слово stack, с английского, переводится как «стопка». По сути, любая стопка может рассматриваться как стек. Если не применять грубую физическую силу, то со стопками мы работаем двумя способами. Либо кладем новый элемент (например, книгу) на верхушку стопки, либо снимаем элемент с верхушки. Еще более показательный пример — магазин в огнестрельном оружии. Первый заложенный патрон выйдет из магазина последним. Поэтому стек еще называют “Last In First Out” (LIFO), то есть “последний зашел, первый вышел”.

Возможно, на этом этапе у вас возник вопрос: ну да, есть стек, но зачем нам всё это?
Перед тем, как разбирать конкретную задачу, я покажу вам, что стек играет огромную роль в программировании. Вспомните, как исполняется любая программа. Одни функции вызывают другие, которые, в свою очередь, вызывают третьи, и так далее. После того, как выполнение заходит в самую глубокую функцию, та возвращает значение, и начинается обратный процесс. Сначала идет выход из наиболее глубоких функций, затем из тех, что уровнем выше, и так далее до тех пор, пока не дойдет до самой внешней функции. Вызов функций — ничто иное, как добавление элемента в стек, а возврат — снятие со стека. Именно так всё устроено на аппаратном уровне. К тому же, если в процессе выполнения программы происходит ошибка, то её вывод часто называют Stack Trace (трассировка стека).
Другой пример, связанный с программированием — кнопка «назад» в браузере. История посещений представляет собой стек, каждый новый переход по ссылке добавляет её в историю, а кнопка «назад» извлекает из стека последний элемент.
Стек — абстрактный тип данных со следующим набором операций:
- Добавить в стек (push)
- Взять из стека (pop)
- Вернуть элемент с вершины стека без удаления (peek)
- Проверить на пустоту (isEmpty)
- Вернуть размер (size)
В PHP стек можно построить на основе массивов. Для этого используется следующий набор функций: array_push , array_pop , empty , count .
Обратите внимание, что array_pop и array_push изменяют исходный массив. array_pop не только изменяет его, но и возвращает элемент, снятый со стека.
( Для любознательных : В PHP встроена реализация большинства популярных структур данных. Работа с ними требует знания ООП механизмов в PHP.)
Рассмотрим задачку, решение которой тривиально при использовании стека. Кстати, её нередко задают на собеседованиях, как раз чтобы убедиться, хорошо ли вы знаете базовые структуры данных.
Задача:
Необходимо реализовать функцию, которая проверяет, что парные символы сбалансированы. То есть каждый открывающий символ имеет закрывающий, и они не перекрываются, например так [{]} . К таким символам в нашем случае относятся <>, {}, () [] . Входом в функцию может быть ()<>{} . Такой пример проходит проверку, а вот этот уже нет: [({)}] . Здесь происходит перекрытие фигурных и круглых скобок.
Решение со стеком выглядит так:
- Если перед нами открывающий элемент, то заносим его в стек
- Если закрывающий, то достаем из стека элемент (очевидно, последний добавленный) и смотрим, что он открывающий для данного закрывающего. Если проверка провалилась, значит выражение не соответствует требуемому формату.
- Если мы дошли до конца строки и стек пустой, то все хорошо. Если в стеке остались элементы, то проверка не прошла. Такое может быть, если в начале строки были открывающие элементы, но в конце не было закрывающих.
Разберем его построчно:
<?php
function checkIfBalanced(string $expression): boolean
{
// инициализируем стек
$stack = [];
// инициализируем список открывающих элементов
$startSymbols = ['{', '(', '<', '['];
// инициализируем список пар.
$pairs = ['{}', '()', '<>', '[]'];
// Проходимся по строке от первого до последнего символа
for ($i = 0; $i < strlen($expression); $i++) {
$curr = $expression[$i];
// Если текущий символ находится в списке открывающих символов, то заносим его в стек
if (in_array($curr, $startSymbols)) {
array_push($stack, $curr);
} else { // Если элемент не входит в список открывающих, значит считаем что это закрывающий символ
$prev = array_pop($stack);
// Составляем из этих символов пару
$pair = "{$prev}{$curr}";
// Проверяем, что она входит в список $pairs. Если входит, то все правильно, двигаемся дальше; если нет,
// то это автоматически означает, что символы не сбалансированы
if (!in_array($pair, $pairs)) {
return false;
}
};
}
// Если стек оказался пустой после обхода строки, то значит все хорошо
return count($stack) == 0;
}
Предположим, что на вход функции попала следующая строка: [{] . Ниже описание ключевых шагов при выполнении функции проверки:
- Первый символ
[заносится в стек, так как он входит в список открывающих - Символ
{также заносится в стек по той же самой причине - Символ
]относится к закрывающим, поэтому со стека забирается последний символ{. Из них составляется пара{], которая не проходит проверку.
Семантика
Может возникнуть соблазн использовать эти функции в повседневной практике. Например, чтобы извлечь из массива последний элемент. Несмотря на то, что array_pop действительно позволяет это сделать, такой вариант использования крайне нежелателен по нескольким причинам:
- Побочный эффект данной операции — изменение исходного массива. Даже если далее массив не используется, такой код вносит потенциальные проблемы и заставляет его переписывать в будущем.
- Нарушается семантика. Инструменты нужно использовать по назначению, иначе рождается код, который декларирует одно, но в реальности делает другое. Любой опытный программист, который видит
array_popилиarray_pushсразу считает, что массив в данной части программы используется как стек, но на самом деле он этого не делает. Подобный код заставляет напрягаться и анализировать его лишний раз для понимания сути.
Дополнительные материалы
PHP: Массивы → Big O
Когда заходит речь про алгоритмы, нельзя не упомянуть понятие «сложность алгоритма» и нотация О-большое (Big O notation). Она не только полезна при прохождении собеседований, но и даёт понимание того, как вообще оценивать эффективность кода (очень относительно).
Как вы помните, алгоритмов сортировок существует много, я бы сказал очень много. Все они выполняют одну и ту же задачу, но при этом отличаются друг от друга. В информатике алгоритмы сравниваются друг с другом (или классифицируются) по их вычислительной (или алгоритмической) сложности. Сложность оценивается по количеству выполняемых операций. Понятно, что конкретное количество операций зависит от входных данных, например, если массив отсортирован, то количество операций будет минимальным (но они все равно будут, потому что алгоритм должен убедиться в том, что массив отсортирован). Если не отсортирован, то для каждого алгоритма можно подобрать такие входные данные, при которых он будет работать максимально долго и не эффективно. Эти случаи называют соответственно верхней и нижней границей.
Нотация Big O как раз придумана для описания алгоритмической сложности. Она призвана показать, как сильно увеличится количество операций при увеличении размера данных.
Вот некоторые примеры того, как записывается сложность: O(1) , O(n) , O(nlog(n)) .
O(1) описывает так называемую константную сложность. Например обращение к элементу массива по индексу оценивается константой, другими словами оно не зависит от размера массива, поэтому внутри O записывается единица, символизирующая константу. А вот функция, которая печатает на экран все элементы переданного массива используя обычный перебор имеет сложность O(n) (линейная сложность). То есть количество выполняемых операций будет равно количеству элементов массива. Именно это количество символизирует символ n в скобках.
Еще один простой пример — вложенные массивы. Вспомните как работает поиск пересечений в неотсортированных массивах. Для каждого элемента из одного массива проверяется каждый элемент другого массива (либо через цикл, либо с помощью функции in_array , чья сложность O(n) , ведь в худшем случае она просматривает весь массив). Если принять, что размеры обоих массивов одинаковы и равны n , то получается, что поиск пересечений имеет квадратичную сложность или O(n^2) (n в квадрате). Существуют как очень эффективные, так и абсолютно не эффективные алгоритмы. Первые, как правило имеют логарифмическую сложность, последние — степенную, такую, при которой n находится в степени. Скорость работы подобных алгоритмов падает с катастрофической скоростью даже при небольшом количестве элементов.
Нередко более быстрые алгоритмы быстрее не потому, что они лучше, а потому что они потребляют больше памяти или имеют возможность паралеллиться (и если это происходит, то работают крайне эффективно). Как и все в инженерной деятельности, эффективность — компромисс. Выигрывая в одном месте, мы проиграем где-то в другом.
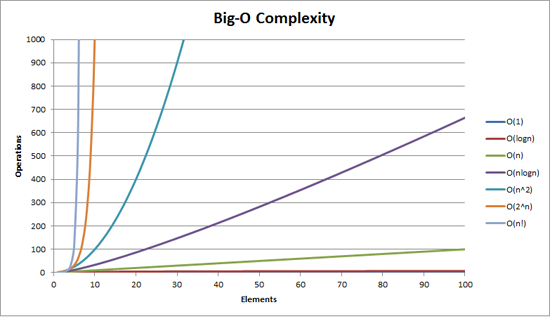
Big O, во многом, теоретическая оценка, на практике всё может быть по-другому. Реальное время выполнения зависит от множества факторов среди которых, архитектура процессора, операционная система, язык программирования, доступ к памяти (последовательный или произвольный) и многое другое.
Вопрос эффективности кода довольно опасен. В силу того, что многие начинают учить программирование именно с алгоритмов (особенно в университете), им начинает казаться, что эффективность — это главное. Код должен быть быстрым.
Такое отношение к коду гораздо чаще приводит к проблемам, чем делает его лучше. Важно понимать, что эффективность — враг понимаемости. Такой код всегда сложнее, больше подвержен ошибкам, труднее модифицируется, дольше пишется. А главное, настоящая эффективность редко когда нужна сразу или вообще нужна. Обычно тормозит не код, а, например, запросы к базе данных или сеть. Но даже если код выполняется медленно, то вполне вероятно, что именно тот участок, который вы пытаетесь оптимизировать, вызывается за все время жизни программы всего лишь один раз и ни на что не влияет, потому что работает с небольшим объемом памяти, а где-то в это время есть другой кусок, который вызывается тысячи раз, и приводит к реальному замедлению.
Программисты тратят огромное количество времени, размышляя и беспокоясь о некритичных местах кода, и пытаются оптимизировать их, что исключительно негативно сказывается на последующей отладке и поддержке. Мы должны вообще забыть об оптимизации в, скажем, 97% случаев. Поспешная оптимизация является корнем всех зол. И, напротив, мы должны уделить все внимание оставшимся 3%. — Дональд Кнут
Перед тем, как пытаться что-то оптимизировать, обязательно прочитайте небольшую онлайн-книжку, которая хорошо объясняет суть всех оптимизаций.
Дополнительные материалы
PHP: Массивы → Destructuring
В программировании часто встречается понятие «синтаксический сахар». Им обозначают конкретные конструкции в языках программирования, которые упрощают часто используемые операции, делая их синтаксически проще.
PHP не богат на подобные конструкции, но кое-что все же имеется. Во время наших курсов я периодически буду подкидывать те или иные способы сделать код короче и, главное, понятнее (в этом и суть сахара).
Самый простой пример сахара — обмен переменных местами. Обычно для этого используют третью переменную (хотя те, кто сильны в теории, скажут и о XOR варианте обмена):
<?php
$a = 5;
$b = 8;
$temp = $a;
$a = $b;
$b = $temp;
Довольно утомительное занятие. А вот как можно сделать короче:
<?php
$a = 5;
$b = 8;
[$b, $a] = [$a, $b];
Не так круто, как в других языках, где можно писать a, b = b, a , но уже что-то.
Другой интересный пример синтаксического сахара — destructuring (дестракчеринг или деструктуризация). Представьте, что у нас есть массив из двух элементов, которыми мы хотим оперировать в нашей программе. Самый простой вариант использования — постоянное обращение по индексу $arr[0] и $arr[1] . Такой код не очень хорошо читается, потому что надо понять, что это такое. Поэтому гораздо лучше сначала присвоить эти значения переменным с хорошими именами. Тогда код будет выглядеть так:
<?php
$firstName = $arr[0];
$lastName = $arr[1];
Как видно, код стал значительно понятнее без лишних слов. Дестракчеринг позволяет извлекать элементы из составной структуры, используя особый синтаксис:
<?php
[$firstName, $lastName] = $arr;
Получилось и короче и понятнее (особенно если привыкнуть к этому способу записи). Пример с обменом переменных тоже построен на дестракчеринге. Обратите внимание, что справа от = фактически был создан массив [$a, $b] . Дестаркчеринг работает для любого количества элементов и не только с массивами.
Разложение массива можно использовать не только как отдельную инструкцию в коде, но и, например, в циклах: