Переход от написания скриптов (то что мы делали ранее) к созданию полноценных сайтов, сопровождается необходимостью знакомиться с большим числом понятий и инструментов выходящих далеко за рамки языка. Взаимодействие с внешним миром вовлекает в себя знание операционных систем, в частности сетей, работу с регистраторами, хостингом, деплоем сайта. На собеседованиях веб-программистов часто задают вопрос “Что происходит после того как в адресной строке браузера набирается сайт www.google.com и нажимается enter?”. Очень подробный ответ на этот вопрос доступен здесь. Спрашивающий, в этот момент, хочет услышать от вас ключевые понятия связанные с веб-разработкой.
- Выполнение DNS запроса для получения IP адреса по имени домена.
- Соединение с веб-сервером находящемся по этому адресу на порту 443 (или 80) по TCP.
- Выполнение HTTP запроса на содержимое сайта по указанному домену
- Получение ответа и рендеринг содержимого во вкладке браузера
Каждый из этих пунктов неявно подразумевает знание следующих тем:
- Протокол HTTP. Понятие виртуальных хостов. Желательно понимание принципов работы HTTPS.
- Принципы работы DNS.
- Знание TCP/IP. Понятия: порт, маска, подсети. Модель OSI. Сетевые сокеты.
- Веб-сервер. Что это такое, как работает и зачем нужен.
На Хекслете есть ответы на некоторые из этих вопросов, но большую часть материала придется почерпнуть из сторонних источников (со временем мы будем добавлять его к себе например на https://guides.hexlet.io). Подавляющее большинство ответов на указанные темы можно (и нужно!) получить в книгах по операционным системам. В наших рекомендованных книгах есть все необходимое. Знание HTTP можно почерпнуть из соответствующего курса. Общее понимание DNS, хостинга, деплоя из курса Введение в веб-разработку. Остальное есть в дополнительных ссылках.
Очень рекомендую посмотреть наше публичное собеседование где как раз поднимались эти вопросы.
Если говорить про саму разработку, то здесь также открывается целый пласт неизведанного. Фреймворки, микрофреймворки, роутинг, куки, сессии, безопасность, шаблонизация, взаимодействие с базой данных и многое другое. И даже когда вы научитесь готовить сайт, это еще не конец. Сайт доступен пользователям только находясь на удаленном сервере, а значит в разработку включается понятие “деплой”, то есть процесс разворачивания сайта на хостинге. Причем чтобы сайт развернуть, для начала нужно настроить удаленную машину (или машины) используя инструмент наподобие Ansible. Кстати сам хостинг бывает очень разный: IaaS (aws), PaaS (heroku), Shared Hosting, VPS/VDS.
Данный курс посвящен, в первую очередь, разработке веб-сайтов с использованием микрофреймворков и темы указанные выше включает в себя лишь поверхностно (и то не все). Поэтому крайне рекомендуется выполнять задачи не только в среде Хекслета, но и локально, паралелльно выкатывая код на сервис подобный https://www.heroku.com/
Дополнительные материалы
Веб-разработка на PHP → Архитектура Веба
Современные сайты разрабатываются на множестве языков используя совершенно разные технологии, но принципы их устройства одинаковые. То почему сайты внутри устроены похожим образом, определяется архитектурой веба. В его основе лежит протокол HTTP, с которым вы уже знакомы по одноименному курсу.
Современный веб несколько сложнее благодаря Websockets, что существенно влияет на принципы построения сайтов активно их использующих. Однако вебсокеты не замена обычному способу взаимодействия, а дополнение необходимое для некоторых ситуаций. К таким задачам относится любое взаимодействие в реальном времени (real-time), например чаты или многопользовательские игры
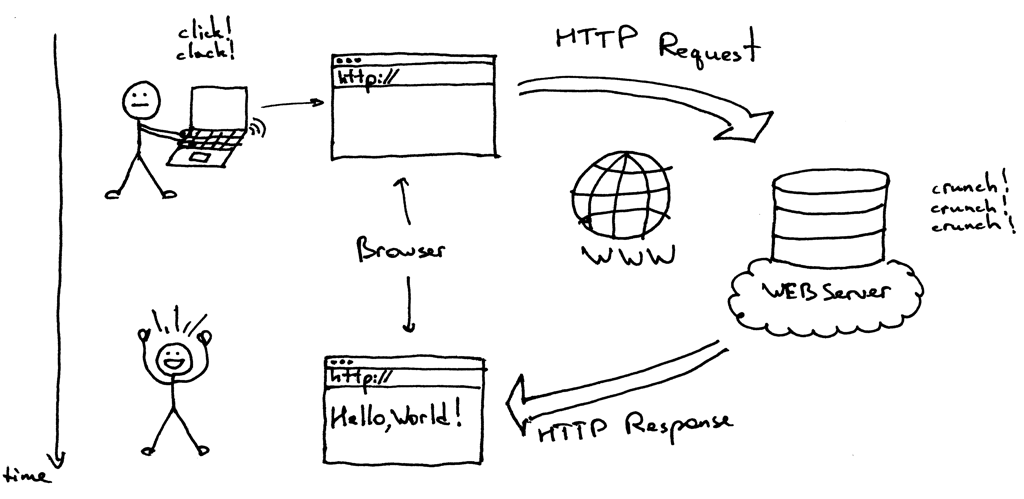
Принцип взаимодействия с любым сайтом сводится к следующим шагам (сам процесс сложнее, но нас интересует только взаимодействие с приложением):
- Пользователь запрашивает страницу сайта
- Браузер выполняет HTTP запрос к веб-серверу
- Веб-сервер возвращает содержимое страницы в HTTP ответе
- Браузер отрисовывает страницу сайта
- Пользователь кликает по ссылке на сайте и весь процесс повторяется снова.
Каждый такой цикл включает в себя HTTP сессию: HTTP запрос и HTTP ответ. Проще всего увидеть HTTP сессию используя утилиту curl :
$ curl -v --head http://code-basics.ru
* Rebuilt URL to: http://code-basics.ru/
* Trying 100.102.175.148...
* TCP_NODELAY set
* Connected to code-basics.ru (100.102.175.148) port 80 (#0)
# Ниже приведен запрос
> HEAD / HTTP/1.1
> Host: code-basics.ru
> User-Agent: curl/7.54.0
> Accept: */*
>
# А это ответ
< HTTP/1.1 200 OK
< Date: Wed, 04 Jul 2018 08:38:22 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 7902
< Connection: keep-alive
< Server: nginx/1.15.1
<
* Connection #0 to host code-basics.ru left intact
Как видно, принцип взаимодействия не зависит от того на чем написан сайт. С точки зрения сайта, всегда есть запрос который нужно обработать и вернуть ответ в виде, например, HTML. То каким будет HTML для конкретного запроса, определяется самим запросом, то есть запрошенной страницей и различными параметрами HTTP, такими как заголовки. В конечном итоге, код сайта, представляет из себя набор обработчиков разных страниц, которые принимают входящие запросы, формируют ответ и возвращают его. Ниже вы увидите примеры на разных языках. Даже не зная синтаксиса достаточно легко уловить общую структуру всех примеров кода: функция обработчик привязанная к конкретной странице.
PHP
<?php
$app = new Slim\App();
$app->get('/', function ($request, $response) {
$response->write('Welcome to Slim!');
return $response;
});
$app->get('/about', function ($request, $response) {
$response->write('About My Site');
return $response;
});
$app->run();
Ruby
require 'sinatra'
get '/frank-says' do
'Put this in your pipe & smoke it!'
end
Python
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
Java
import static spark.Spark.*;
public class HelloWorld {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello World");
}
}
JavaScript
import Express from 'expressjs';
const app = new Express();
app.get('/', (req, res) => {
res.send('Hello World!');
});
Конечно реальные сайты устроены значительно сложнее, но в основе лежит та связка запрос-ответ, которая была описана в этом уроке. Именно она определяет общую структуру любого сайта написанного на любом языке.
Самостоятельная работа
- Выполните запрос
curl --head https://hexlet.io. Изучите отправляемые и возвращаемые заголовки - Откройте в браузере консоль разработчика, перейдите в ней на вкладку network (сеть) и загрузите
https://ru.hexlet.ioв этой вкладке. Изучите то какие запросы делает сайт (и с какими заголовками) и что приходит в ответ.
Веб-разработка на PHP → Веб-сервер
Процессы
Давайте теперь посмотрим для чего нужен веб-сервер. Ответ на этот вопрос требует небольшой подготовки.
Единицей исполнения в операционных системах является процесс. Это некоторая абстракция внутри ОС (имеется ввиду, что процесс невозможно представить визуально). Любая запущенная программа представляет собой либо один процесс, либо набор процессов. Например, в браузерах одна вкладка, как правило, — это один процесс. Особенность процессов в том, что они изолированы друг от друга. Например, сбой в одном процессе не влечет за собой остановку работы других. Такое свойство процессов можно наблюдать в тех ситуациях, когда одна из вкладок браузера начинает тормозить и в конце концов зависает (и её не всегда удаётся закрыть!). В это время можно без проблем продолжать использовать другие вкладки.
Внутри себя процесс может делиться на потоки, но эта деталь не влияет на описываемую тему, поэтому я её опускаю. Подробнее о менеджменте процессов можно прочитать в книгах по операционным системам.
Посмотреть список процессов в Linux можно командой ps aux либо top
Понимание процессов тесно связано с сетевым взаимодействием. Взаимодействие между двумя компьютерами в сети — всегда сводится к взаимодействию двух процессов. Другими словами, нельзя взять и подключиться к компьютеру в целом — можно подключиться только к конкретному процессу конкретной программы. Происходит это так: одна программа, которая хочет, чтобы к ней можно было подключаться по сети, при запуске начинает слушать сетевой сокет. Такая программа называется сервером. Другая программа к ней подключается. Такая программа называется клиентом. В случае веба, сервер — это конкретный веб-сервер, например, nginx, а клиент — это браузер.
Здесь нужно сделать небольшую ремарку насчет “слушать сетевой сокет”. Сетевое взаимодействие между программами двух компьютеров осуществляется с помощью протокола TCP, поверх которого уже работает HTTP. Для обращения к другому комьютеру нужно знать два параметра: IP адрес и порт . Так вот “слушать сетевой сокет” означает занять определённый порт (на определённом сетевом интерфейсе) и дать возможность обращаться к процессу через него. Именно по номеру порта операционная система понимает, к какому процессу пытаются обратиться.
Браузер, благодаря DNS, получает IP адрес компьютера, на котором расположен сайт указанного домена (например, google.com). А вот откуда он знает порт, на котором висит веб-сервер в ожидании входящих запросов? Ответ на этот вопрос очень простой: существует соглашение , согласно которому веб-сервер, обслуживающий сайт по протоколу HTTP, слушает порт 80 , а протокол HTTPS обслуживается на порту 443 . Но так бывает не всегда. Во время локальной разработки, обычно, используются другие порты, например, 3000 , или 4000 . Сам номер не принципиален, главное, что он доступен для веб-сервера, и вы обращаетесь через браузер именно к нему. Порт указыавется через двоеточие после названия сайта, например www.google.com:80 .
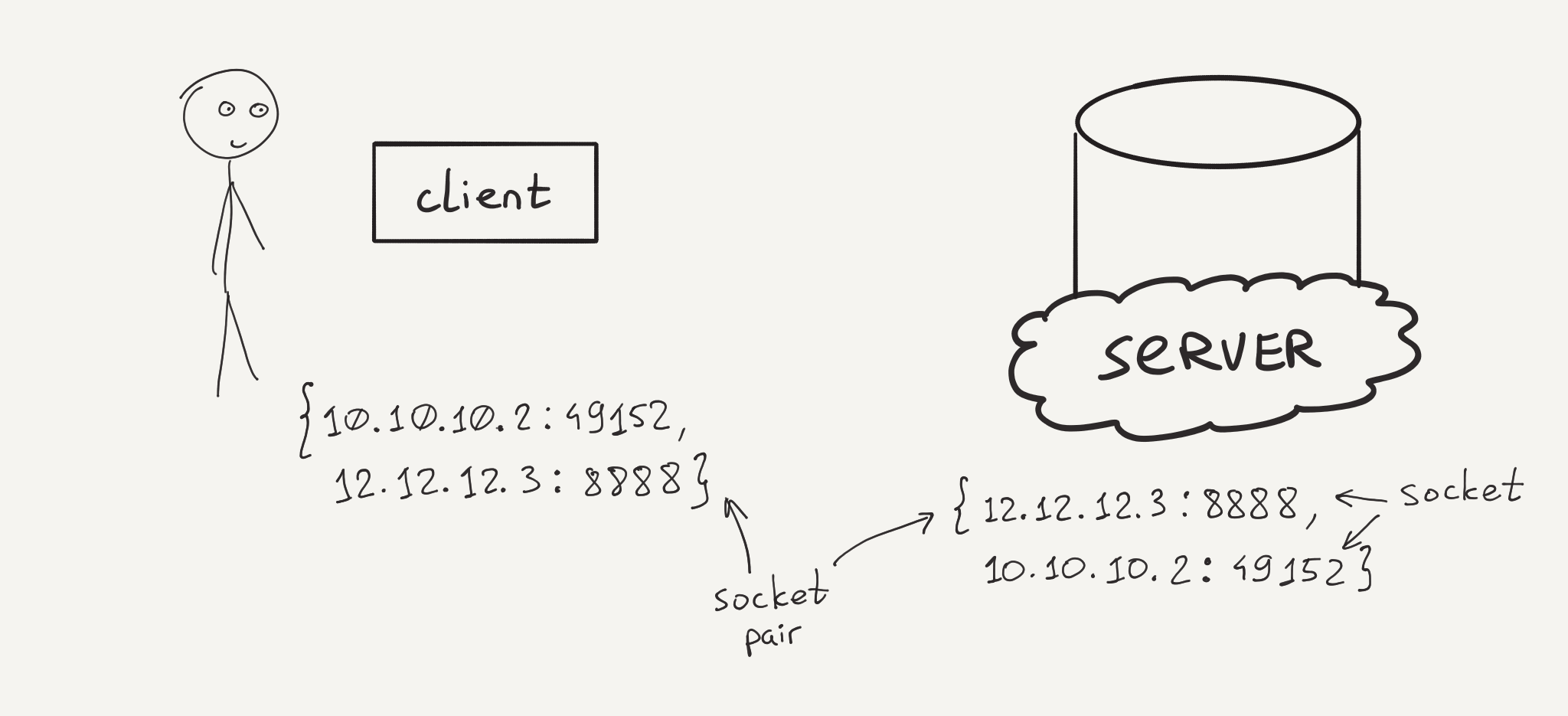
Веб-сервер
Веб-сервер — специализированная программа для обслуживания сайтов. Один веб-сервер может обрабатывать практически любое число сайтов (благодаря Virtual Hosts ). В общем случае он перенаправляет входящие сетевые запросы на код сайтов, получает от них ответ и возвращает его браузеру . Кроме главной функции, у веб-серверов огромное число вспомогательных. Среди них кеширование, перезапись запросов, раздача статики (например, картинки), reverse proxy, балансировка нагрузки и многое другое. Веб-сервера ничего не знают про то, на чём написан сайт. Все способы взаимодействия веб-сервера и сайта на любом языке стандартизированы. Благодря этому веб-серверов существует не так много и все они могут работать с сайтами, написанными на чём угодно.
Первым и самым простым способом взаимодействия веб-сервера с сайтом был CGI (Common Gateway Interface). Этот стандарт сразу разрабатывался с учётом того, что сервер не должен зависеть от того, на чём написан сайт. Он основан на переменных окружения. По сути, сайт представляет из себя исполняемый файл, который запускается веб-сервером во время обработки входящего запроса и передает в него все параметры запроса через переменые окружения. Всё, что требуется от скрипта, — это вернуть HTTP ответ в стандартный вывод (STDOUT). Общий алгоритм работы выглядит так:
- Клиент запрашивает страницу сайта.
- Веб-сервер принимает запрос и устанавливает переменные окружения (через них приложению передаются данные и служебная информация).
- Веб-сервер перенаправляет запросы через стандартный поток ввода (stdin) на вход вызываемой программы.
- CGI-приложение выполняет все необходимые операции и формирует результаты в виде HTML.
- Сформированный гипертекст возвращается веб-серверу через стандартный поток вывода (stdout). Сообщения об ошибках передаются через stderr.
- Веб-сервер передаёт результаты запроса клиенту.
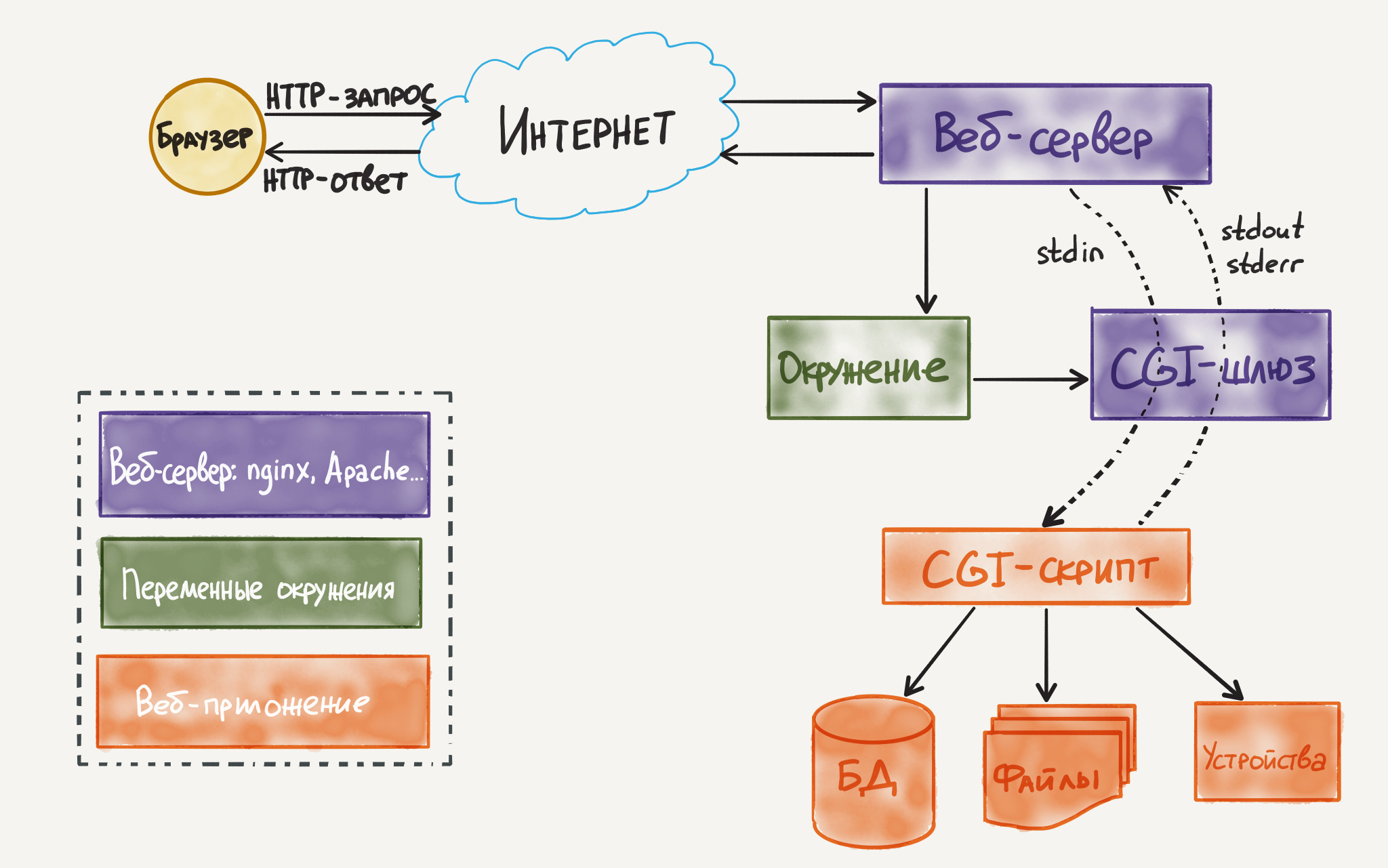
Очень важно осознать, что в режиме CGI, скрипт, который представляет из себя сайт (как программу), запускается на каждый запрос заново. Это значит, что вся логика инициализации отрабатывает для каджого запроса по новой, а после выполнения запроса, ничего не остается (скрипт просто завершается). Если между запросами есть некоторое состояние (например пользователь что-то сохранил), то его нужно отправлять в какое-то хранилище, файловую систему (создать файл) или базу данных.
Реализации
Разных веб серверов довольно много. Начиная от встроенного в сам PHP, с которым мы познакомимся очень скоро, заканчивая веб-серверами общего назначения, которые используются всеми. Самым популярным и эффективным решением на текущий момент является Nginx. Именно с ним и стоит познакомиться. Для разработки он не понадобится, так как в PHP встроен свой сервер, но в продакшен среде без него никак. Кроме него набирает популярность веб-сервер Caddy, который хоть и не такой быстрый, но обладает рядом важных особенностей, он значительно проще в настройке, из коробки умеет генерировать сертификаты и многое другое.
Кроме указанных серверов, в PHP мире до сих пор пользуется популярностью Apache. Этот веб-сервер когда-то был передовым решением, но те времена давно ушли. Использовать Apache можно только в том случае, если у вас нет выбора, например, на хостинге предлагают именно его. Во всех остальных ситуациях предпочтительнее Nginx. Связано это с моделью работы самого сервера. Apache работает по модели “поток за запрос”, что значительно более затратно и медленно по сравнению с асинхронной моделью Nginx.
Самостоятельная работа
Установите nginx и убедитесь в том что он запускается и работает. Сделать это можно по одному из гайдов в сети, которые гуглятся так: php nginx <имя вашей операционной системы> . Это задание повышенной сложности. Если не получается прямо сейчас, то не тратьте время, сначала пройдите курс, а затем попробуйте еще раз.
Дополнительные материалы
Веб-разработка на PHP → Встроенный в PHP веб-сервер
PHP, как и многие другие языки, сразу поставляется со встроенным веб-сервером. Этот веб-сервер создан исключительно для удобства разработки, так как не надо ставить ничего дополнительно, но совсем не подходит для продакшен среды. В последнем случае нужно использовать Nginx.
Разработка сайтов, с точки зрения организации кодовой базы, мало отличается от разработки обычных программ. Первым делом необходимо создать директорию внутри которой будет вестись разработка сайта, а затем ее следует добавить в git репозиторий. Назовем эту директорию корнем проекта. Если проект учебный, то лучше сразу создать репозиторий на гитхабе и выкладывать все эксперименты туда.
Затем нужно создать файл index.php и поместить его в корень проекта. По соглашению это главный входной файл в PHP, который автоматически ищется веб-серверами. Создайте такой файл в директории проекта со следующим содержимым:
<?php
// Печатает год в STDOUT
echo date('Y');
Затем запустите веб сервер, например, на порту 8000 .
$ php -S localhost:8000
PHP 7.2.7 Development Server started at Wed Jul 4 15:28:08 2018
Listening on http://localhost:8000
Document root is /private/tmp
Press Ctrl-C to quit.
После того как сервер будет запущен, он полностью забирает управление. Вкладка терминала больше не доступна для ввода команд. В отличии от обычных скриптов, которые выполняют свою задачу и заканчиваются, веб-сервера должны слушать порт непрерывно и сразу реагировать на входящие соединения. Поэтому однажды запустив сервер, он продолжит работать до тех пор пока его не остановят. Остановить сервер можно набрав Ctrl-C.
Такой способ запуска удобен в разработке, но в реальном окружении сервера запускают в виде Демонов. Демон - процесс операционной системы работающий в фоне.
Если в это время попытаться запустить еще один веб-сервер в соседней вкладке на том же порту, то запуск завершиться с такой ошибкой:
Failed to listen on localhost:8000 (reason: Address already in use)
В своей программисткой жизни вы встретитесь с этой ошибкой не раз. Она означает что какой-то процесс занял соответствующий порт (в данном случае 8000). В такой ситуации нужно либо остановить процесс который вам мешает, либо стартовать на другом порту.
Посмотреть какой процесс занял порт 8000 можно командой sudo lsof -i :8000
После этого откройте браузер и введите http://localhost:8000 . На экран выведется текущий год. В терминале, где запущен веб-сервер, появятся записи (лог) показывающие входящие запросы.
[Wed Jul 4 15:28:16 2018] ::1:51214 [200]: /
[Wed Jul 4 15:28:17 2018] ::1:51215 [404]: /favicon.ico - No such file or directory
Теперь снова откройте файл index.php и добавьте ниже вывод echo 'Hello, world!'; . Выполните f5 в браузере, и вы увидите, что изменения применились автоматически. Так происходит потому что веб-сервер запускает файл на выполнение каждый раз заново.
Дополнительные материалы
Веб-разработка на PHP → PHP CGI
В предыдущем уроке мы создали сайт буквально из одного PHP файла, печатающего в STDOUT текущий год. Так работает только PHP, потому что это единственный в мире язык, который в своем ядре работает как CGI скрипт. Именно этим он обязан своей популярностью. Ниже вы увидите основные возможности, которые есть в языке для работы с вебом “из коробки”.
После выполнения скрипта index.php , все необходимые HTTP заголовки ответа, PHP, отправил автоматически, а телом ответа стали данные, которые были отправлены в STDOUT.
$ curl -v localhost:8000
* Trying ::1...
* TCP_NODELAY set
* Connected to localhost (::1) port 8000 (#0)
> GET / HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Host: localhost:8000
< Date: Thu, 05 Jul 2018 06:20:10 +0000
< Connection: close
< X-Powered-By: PHP/7.2.7
< Content-type: text/html; charset=UTF-8
<
* Closing connection 0
PHP об этом говорит прямо: X-Powered-By: PHP/7.2.7 . Заголовки можно менять и добавлять используя функцию header.
<?php
// file: index.php
header('X-My-Header: hi!');
echo date('Y');
Теперь запрос
$ curl --head localhost:8000
HTTP/1.1 200 OK
Host: localhost:8000
Date: Thu, 05 Jul 2018 06:26:29 +0000
Connection: close
X-Powered-By: PHP/7.2.7
X-My-Header: hi!
Content-type: text/html; charset=UTF-8
Как видно, заголовок появился в ответе. Помните, что функцию header можно вызывать только если клиенту еще не передавались данные. То есть она должна идти первой в выводе, перед ее вызовом не должно быть никаких HTML-тегов, пустых строк и т.п.
<?php
echo 'hello';
/* Этот пример приведет к ошибке. Обратите внимание
* на тег вверху, который будет выведен до вызова header()
*/
header('Location: http://www.example.com/');
Все что мы обсудили выше, касается HTTP ответа, но не менее важно уметь работать с данными HTTP запроса: посмотреть текущие заголовки, адрес, параметры запроса и его тело. Для этого в PHP реализованы суперглобальные переменные (массивы). Суперглобальность означает то, что они доступны из абсолютно любого места программы. К ним относятся:
$GLOBALS$_SERVER$_GET$_POST$_FILES$_COOKIE$_SESSION$_REQUEST$_ENV
И хотя чисто технически это обычные массивы которые можно изменять, большинство из них, все же, предназначены только для чтения. Например массив $_SERVER содержит в себе все заголовки запроса:
Array
(
[DOCUMENT_ROOT] => /private/tmp
[REMOTE_ADDR] => ::1
[REMOTE_PORT] => 58667
[SERVER_SOFTWARE] => PHP 7.2.7 Development Server
[SERVER_PROTOCOL] => HTTP/1.1
[SERVER_NAME] => localhost
[SERVER_PORT] => 8000
[REQUEST_URI] => /
[REQUEST_METHOD] => GET
[SCRIPT_NAME] => /index.php
[SCRIPT_FILENAME] => /private/tmp/index.php
[PHP_SELF] => /index.php
[HTTP_HOST] => localhost:8000
[HTTP_USER_AGENT] => curl/7.54.0
[HTTP_ACCEPT] => */*
[REQUEST_TIME_FLOAT] => 1530772973.7628
[REQUEST_TIME] => 1530772973
)
Обратите внимание на формат ключей. PHP автоматически переводит все имена заголовков в верхний регистр. Кроме заголовков этот массив содержит некоторые дополнительные параметры, например имя запущенного скрипта и версию PHP. Практически главный ключ в этом массиве REQUEST_URI . Он содержит адрес запрошенной страницы и на основе него выбирается подходящее действие.
$_POST содержит данные отправленные методом POST . А вот $_GET вопреки своему названию, содержит Query Params, которые, если вы помните, можно отправить с любым глаголом. Кстати не все PHP программисты это знают и думают что существует понятие “гет параметры”. Массив $_REQUEST содержит объединенные данные массивов $_POST и $_GET .
Веб-разработка на PHP → HTML в PHP
Главный секрет PHP заключается в том, что сам язык - шаблонизатор. Если вы посмотрите любой другой язык, то в его файлах не увидите ничего похожего на теги: <?php ... ?> . В PHP любой файл с кодом это шаблон, причем этот шаблон не имеет никакой структуры (как бывает в некоторых шаблонизаторах). Вы можете создать php файл, написать любой текст вне тегов <?php ?> , запустить код на выполнение и, внезапно, он не упадет с указанием синтаксической ошибки.
Содержимое index.php :
hi
i am
the template
Запуск этого “кода” выведет весь текст на экран:
$ php index.php
hi
i am
the template
Тоже самое касается HTML, так как это всего лишь текст. Достаточно в любом php файле добавить немного HTML и запустить его, как он будет выведен на экран:
Содержимое index.php :
<div>
<a href="/lessons">Lessons</a>
</div>
Запуск этого “кода” выведет весь текст на экран:
$ php index.php
<div>
<a href="/lessons">Lessons</a>
</div>
Такое поведение языка существует исключительно ради создания сайтов. Если запустить веб сервер в директории с этим файлом index.php , то при обращении к этому “сайту”, мы получим ровно тот же вывод что и в терминале. А это значит, что мы можем заменить такой код:
<?php
echo '<p>hello, world</p>';
На такой:
<p>hello, world</p>
Теперь добавим немного PHP. Шаблон становится шаблоном, тогда, когда внутри него появляется подстановка данных. Принцип работы такой, абсолютно в любом месте шаблона вставляются теги <?php ?> внутри которых можно написать код.
<div>
<a href="/lessons"><?php echo 'Lessons' ?></a>
</div>
Запуск этого кода на выполнение вернет такой же результат что и код выше. Добавим немного программирования:
<?php
$name = 'Lessons';
?>
<div>
<a href="/lessons"><?php echo $name ?></a>
</div>
В данном примере я добавил один блок сверху файла, внутри которого создал переменную. Затем, использовал ее в другой вставке. Все содержимое файла находится в одном пространстве и блоки кода определенные дальше по тексту имеют доступ к данным предыдущих блоков.
<?php
$name = 'Lessons';
$id = 23;
?>
<div>
<a href="/lessons/<?php echo $id ?>"><?php echo $name ?></a>
</div>
Вывод на экран после запуска:
$ php index.php
<div>
<a href="/lessons/23">Lessons</a>
</div>
Для удобства вставки кода в HTML, PHP предлагает альтернативный синтаксис для стандартных конструкций языка. Например, для вставки значения используется сокращенная версия тега начала PHP кода: <?= <код на php> ?> , она отличается от полной тем что вместо <?php echo ... используется <?= ... .
Сокращенная вставка
<?php
$name = 'Lessons';
?>
<div>
<a href="/lessons/<?= 23 ?>"><?= $name ?></a>
</div>
If
<?php if ($a == 5): ?>
A is equal to 5
<?php endif; ?>
Switch
<?php switch ($foo): ?>
<?php case 1: ?>
...
<?php endswitch ?>
Foreach
<?php foreach ($actions as $action): ?>
<option value="<?= $action ?>"><?= $action ?>
<?php endforeach; ?>
С одной стороны, поддержка CGI внутри самого языка позволяет начать делать сайт буквально на коленке без особых знаний программирования и HTTP, что многие и делают. С другой, PHP толкает к созданию абсолютно не поддерживаемого кода, который не может никто прочитать кроме автора. Посмотрите сами:
<!DOCTYPE html>
<html>
<head>
<title>Upload your files</title>
</head>
<body>
<form enctype="multipart/form-data" action="upload.php" method="POST">
<p>Upload your file</p>
<input type="file" name="uploaded_file"></input><br />
<input type="submit" value="Upload"></input>
</form>
</body>
</html>
<?php
if (!empty($_FILES['uploaded_file'])) {
$path = "uploads/";
$path = $path . basename( $_FILES['uploaded_file']['name']);
if (move_uploaded_file($_FILES['uploaded_file']['tmp_name'], $path)) {
echo "The file " . basename( $_FILES['uploaded_file']['name']) . " has been uploaded";
} else{
echo "There was an error uploading the file, please try again!";
}
}
Такой способ программирования возможен только в PHP (потому что только PHP это сразу и язык и шаблонизатор и CGI скрипт). При таком способе организации кода, сайт очень быстро начинает представлять из себя мешанину HTML и PHP. Если количество разных страниц сайта достигнет хотя бы десятка (а их обычно сотни и больше), то поддержка уже станет невероятно сложной. Безопасность такой шаблонизации находится на нуле (см XSS). Так же PHP не поддерживает макеты, то есть специализированые шаблоны, содержащие обвязку сайта, в которую вставляется HTML конкретного обработчика.
По этой причине в PHP, как и в других языках, используют шаблонизаторы, написанные на самом PHP. Наиболее популярные среди них Blade и Twig. Лично мне больше импонируют шаблоны на основе Slim, но в PHP они не так популярны, как в JS или Ruby. Шаблонизаторы будут одной из тем следующих уроков.
Дополнительные материалы
Веб-разработка на PHP → Микрофреймворк Slim
Цикл запрос-обработка-ответ включает множество элементов, которые идентичны для всех сайтов. Поэтому возникли, так называемые, фреймворки, специализированные библиотеки, которые определяют структуру программы. В этом их отличие от обычных библиотек. Благодаря фреймворкам можно сосредоточиться на логике сайта, а не на продумывании базовой архитектуры или кодированию вспомогательных инструментов.
Веб-фреймворки подразделяются на две больших группы одна из которых так и называется Фреймворки, а другая - Микрофреймворки. Микрофреймворки устроены значительно проще и содержат внутри себя только минимально необходимую обвязку для комфортной работы в архитектуре HTTP запрос-ответ. Они идеально подходят для обучения, потому что просты в эксплуатации и не отвлекают от главного. С одним микрофреймворком мы уже знакомились ранее - Slim. Теперь, обладая гораздо более глубоким пониманием происходящих процессов, мы сможем изучить его вдоль и поперек, попутно разбирая типичные задачи и их способы решения в вебе.
Slim
Первым делом создайте подходящую структуру директорий в вашей домашней директории:
.
├── hexlet-slim-example
│ └── public
Создайте репозиторий внутри hexlet-slim-example и добавьте его на github. Не забудьте создать файл .gitignore и поместите туда директорию vendor . hexlet-slim-example теперь называется корневой директорией проекта (root directory).
Зайдите в корневую директорию проекта и установите Slim:
$ composer require slim/slim "^3.0"
Добавьте файл hexlet-slim-example/public/index.php со следующим содержимым:
<?php
// Подключение автозагрузки через composer
require __DIR__ . '/../vendor/autoload.php';
// Вывод ошибок на экран (для удобной отладки)
$configuration = [
'settings' => [
'displayErrorDetails' => true,
],
];
$app = new \Slim\App($configuration);
$app->get('/', function ($request, $response) {
return $response->write('Welcome to Slim!');
});
$app->run();
Создайте файл Makefile в корне проекта и добавьте туда задачу start :
start:
php -S localhost:8000 -t public public/index.php
Теперь выполните запуск:
$ make start
Вывод должен быть примерно таким:
php -S localhost:8000 -t public public/index.php
PHP 7.2.7 Development Server started at Thu Jul 5 11:44:03 2018
Listening on http://localhost:8000
Document root is /private/var/tmp/hexlet-slim-example/public
Press Ctrl-C to quit.
Эта команда содержит новую для нас опцию -t . С ее помощью меняется корневая директория, то место где происходит поиск файла index.php . Подобную директорию принято называть public и помещать в нее только то, что можно открыть напрямую из браузера. Все остальное, ни в коем случае, не должно лежать в этой директории, иначе вас могут взломать.
И последний шаг, откройте в браузере localhost:8000 . Если все хорошо, то на экране появится надпись Welcome to Slim! .
Веб-разработка на PHP → Обработчики запросов
Главная содержательная часть в файле index.php - обработчик запроса:
<?php
$app = new \Slim\App();
// Обработчик
$app->get('/', function ($request, $response) {
return $response->write('Welcome to Slim!');
});
Общий принцип работы любого веб-фреймворка отражает архитектуру HTTP. На каждый адрес задается обработчик (функция), который выполняет необходимые действия и возвращает ответ. В Slim, все приложение (сайт) представлено объектом класса Slim\App . Этот объект содержит методы на каждый глагол HTTP: get , post , put и так далее. Эти методы принимают на вход два параметра, первый - адрес (говорят маршрут) для которого вызовется обработчик и второй, собственно сам обработчик. Лямбда-функция с двумя параметрами $request и $response .
Во фреймворках принято (и это соответствует идеям REST) определять маршрут как комбинацию глагола HTTP и адреса. То есть GET /users и POST /users с точки зрения большинства фреймворков - разные маршруты с разными обработчиками. В этом достаточно просто убедиться если определить соответствующие маршруты и выполнить к ним запросы с помощью curl.
<?php
$app = new \Slim\App;
$app->get('/users', function ($request, $response) {
return $response->write('GET /users');
});
$app->post('/users', function ($request, $response) {
return $response->write('POST /users');
});
$app->run();
$ curl localhost:8000/users
GET /users
$ curl -XPOST localhost:8000/users
POST /users
Перед тем как двигаться дальше, обязательно попробуйте повторить примеры выше в вашей локальной среде, это очень важно для понимания последующего контента .
Первое что бросается в глаза, у нас всего лишь один входной файл для всех адресов. Пользователь может запрашивать сколь угодно сложный адрес /companies/3/photos5 , все сведется к запуску файла index.php , а сам адрес становится лишь значением $_SERVER['REQUEST_URI'] .
.
├── site
│ └── public
│ └── index.php
Такой подход имеет название FronController впротивовес подходу, когда каждый адрес (на самом деел маршрут, но об этом чуть позже) фактически отображался на конкретный файл файловой системы. Такой подход называется PageController . В интернете до сих пор встречаются сайты построенные по этой модели, но она давным давно вышла из употребления. Заметить ее легко, если вы видите адреса наподобие /users.php , то почти наверняка в корне сайта лежит файлик users.php , отвечающий за обработку этой страницы.
.
├── site
│ └── public
│ └── home.php
│ └── users.php
│ └── companies.php
Во FrontController процесс поиска нужного хандлера называется диспетчеризацией, по аналогии с тем как это слово используется в оффлайн жизни. Пошагово он выглядит так:
До входа во фреймворк:
- Клиент выполняет запрос к веб-серверу расположенному на сервере. Кстати клиент это не обязательно браузер, в примере выше клиентом выступает программа curl .
- Веб-сервер перенаправляет запрос на
index.phpи устанавливает правильные параметры запроса.
После входа в сам PHP (именно это и есть диспетчеризация):
- Фреймворк анализирует параметры запроса и пытается сопоставить маршруты добавленные в объект
$app(как в примерах в начале урока) с тем что пришло. Он сравнивает комбинацию глагола запроса и сам адрес. Этот процесс называется роутингом (или маршрутизацией). А место где внутри хранятся все добавленные маршрути обычно называют роутером. - Если в процессе роутинга был найден соответствующий маршрут, то вызывается его обработчик.
- Ответ сформированный обработчиком отправляется обратно клиенту
Рассмотрим конкретный пример. Возьмем за основу следующий код:
<?php
$app = new \Slim\App;
$app->get('/', function ($request, $response) {
return $response->write('GET /');
});
$app->get('/companies', function ($request, $response) {
return $response->write('GET /companies');
});
$app->post('/companies', function ($request, $response) {
return $response->write('POST /companies');
});
$app->run();
После запуска этого кода, формируется роутер, который содержит в себе три маршрута:
GET /
GET /companies
POST /companies
Теперь предположим что клиент выполнил такой запрос:
$ curl -XPOST localhost:8000/companies
Веб-сервер запустил index.php , который проинициализировал объект $app (помните что на каждый запрос этот процесс повторяется с нуля?), затем фреймворк сопоставил маршруты и нашел что за этот запрос отвечает POST /companies . Далее фреймворк вызвал обработчик, который вернул клиенту ответ: POST /companies .
Интересный вопрос заключается в том, что произойдет если фреймворк не обнаружит соответствия? Например клиент запросит страницу /comments ? В такой ситуации, фреймворк берет управление на себя (по умолчанию) и автоматически отдает браузеру ответ 404 , то есть говорит о том что страница не найдена. Всегда внимательно смотрите какие делаются запросы и есть ли подходящие под них запросы, чтобы не мучатся вопросом “почему браузер ничего не показывает”. Проще всего увидеть ответ от сервера через консоль разработчика вашего браузера:
Она есть в каждом браузере. Попробуйте открыть ее и понаблюдать за процессом загрузки.
Дополнительные материалы
Веб-разработка на PHP → HTTP Сессия (запрос и ответ)
Каждая HTTP сессия определяется двумя вещами - запросом и ответом. Запрос формируется клиентом, ответ кодом обработчика соответствующего маршрута. И запрос и ответ, в Slim представлены двумя объектами, которые передаются в каждый обработчик.
<?php
$app->get('/', function ($request, $response) {
return $response->write('Hello, world!');
});
$response по стандарту - неизменяемый, это значит, что каждый метод, который выглядит как мутирующий (изменяющий) $response , на самом деле, возвращает новый $response . Не зная этого, очень легко допустить такую ошибку:
<?php
$app->post('/users', function ($request, $response) {
// Метод withStatus устанавливает код ответа HTTP
$response->withStatus(302);
return $response;
});
В этом коде withStatus возвращает новый $response , который никак не используется, а наружу возвращается старый. Если попробовать выполнить запрос к этому обработчику, то он не вернет никаких данных.
Query Params не являются частью маршрута и не влияют на выбор обработчика. Связано это с тем, что такие параметры используются для различных вспомогательных целей, например, параметр page , обозначает страницу просматриваемого списка. Обработчик в такой ситуации всегда один и тот же, а вот данные показываются разные.
$ curl 'localhost:8000/users?page=4&per=3'
GET /users
Параметры извлекаются из объекта $request методом getQueryParam($name, $defaultValue) :
<?php
$app->post('/users', function ($request, $response) {
$page = $request->getQueryParam('page', 1); // 1 - значение по умолчанию
$per = $request->getQueryParam('per', 10);
return $response;
});
Количество обработчиков и маршрутов которые можно добавить ничем не ограничено. При этом микрофреймворки не задают никакой структуры. Если кода становится много, то разделять код по файлам придется самостоятельно.
Во фреймворках не подразумевается прямая работа с PHP в режиме CGI. Данные запроса берутся из объекта $request , ответ вместе с заголовками записывается в объект в $response . Конкретно для отправки тела вызывается функция write . Ее можно использовать множество раз в рамках одного обработчика. Подробнее об этих объектах мы поговорим в следующих уроках.
Дополнительные материалы
Веб-разработка на PHP → Динамические маршруты
До сих пор мы встречались только со статическими маршрутами. В статическом маршруте нет изменяемых частей: адрес точно совпадает с маршрутом и не меняется (поэтому называется “статический”). На практике чаще встречаются динамические маршруты. Проанализируем адреса курсов на Хекслете.
- https://ru.hexlet.io/courses/php-introduction-to-oop
- https://ru.hexlet.io/courses/php-object-oriented-design
- https://ru.hexlet.io/courses/js-react
Нетрудно заметить, что в этих адресах прослеживается определенная структура /courses/<имя курса> . Можно предположить, что на каждый такой адрес создается свой собственный маршрут и обработчик, но тогда представьте себе процесс наполнения сайта. При добавлении нового курса придется программировать. И хотя курсов у нас не тысячи, такой процесс все равно крайне трудоемок. Тоже самое можно сказать и про профили пользователей /u/<никнейм пользователя> . Причем пользователей сотни тысяч и добавляются они на сайт непрерывно без нашего участия.
В примерах выше мы столкнулись с так называемыми динамическими маршрутами. Такие маршруты имеют внутри себя изменяемые части, но обработчик у маршрута только один. Например, все указанные выше адреса курсов соответствуют одному маршруту, который можно записать так /courses/{id} . Где секция {id} означает, что на это место подставляется конкретный идентификатор (уникальная запись, отличающая одну сущность от другой) курса. Имя изменяемой части можно выбирать произвольно, вместо {id} можно написать {lala} . Сам способ записи (в данном случае имя с обрамляющими {} ) зависит от конкретного фреймворка. В Slim для этого используются фигурные скобки, что создает ощущение использования интерполяции.
<?php
$app->get('/courses/{id}', function ($request, $response, array $args) {
$id = $args['id'];
return $response->write("Course id: {$id}");
});
$ curl localhost:8000/courses/132
Course id: 132
Любая изменяемая часть маршрута называется плейсхолдером (заполнитель). В маршруте выше только один плейсхолдер id . Доступ к значению конкретного плейсхолдера осуществляется по имени через массив $args , передающийся третьим параметром в функцию-обработчик.
Для удобства пользователей в адресах стараются использовать не числовые идентификаторы, а человекочитаемые названия. Например, вместо /courses/332 показывают /courses/php-mvc . Эту часть адреса называют словом slug. Slug должен быть уникален и его формат обязан соответствовать требованиям формирования адресов. Как правило, эти имена делают, используя символы латинского алфавита с дефисом между ними: this-that-other-outre-collection .
Подведем промежуточный итог. Понятия адрес и маршрут обозначают разные вещи. Если маршрут статический, то он всегда совпадает с адресом, например, /about . Если маршрут динамический, то ему могут соответствовать бесконечное число адресов (даже если таких страниц на сайте нет), например, /courses/:id .
Количество плейсхолдеров в маршруте может быть больше одного. Обычно такие маршруты используются для вложенных ресурсов.
<?php
$app->get('/courses/{courseId}/lessons/{id}', function ($request, $response, array $args) {
$courseId = $args['courseId'];
$id = $args['id'];
return $response->write("Course id: {$courseId}")
->write("Lesson id: {$id}");
});
Дополнительные материалы
Веб-разработка на PHP → Шаблонизатор
Формирование HTML во фреймворках — отдельная нетривиальная тема. Конечно, никто не запрещает создавать HTML напрямую в виде строки, но такой способ просто перестает работать на реальных сайтах, где HTML одной страницы — это сотни строк.
<?php
$app->get('/courses/{name}', function ($request, $response, array $args) {
$slug = $args['name'];
$course = $courses[$slug];
return $response->write("<h1>{$course->name}</h1>")
->write("<div>{$course->body}</div>");
});
У такого подхода масса недостатков:
- Он небезопасен и может привести к взлому. Подробнее эта тема рассматривается в конце курса.
- С ростом количества HTML поддерживать такой код станет практически невозможно из-за неудобства анализа и редактирования.
- В таком коде будут возникать постояные проблемы с необходимостью экранировать одинарные или двойные кавычки.
- В таком коде крайне легко допустить ошибку в HTML и крайне сложно ее обнаружить.
- В типичных сайтах большая часть HTML общая для разных страниц. Выделить, ее используя подход выше — очень сложно.
Для решения подобных задач придумали шаблонизаторы — специализированные библиотеки, позволяющие описывать шаблон отдельно от остальной части кода.
Для начала необходимо установить пакет slim/php-view . Выполните соответствующую команду в корне проекта:
$ composer require slim/php-view
Добавьте в public/index.php после строчки, где создается переменная $app следующие строки:
<?php
// Контейнеры в этом курсе не рассматриваются (это тема связанная с самим ООП), но если вам интересно, то посмотрите DI Container
$container = $app->getContainer();
// Параметром передается базовая директория в которой будут храниться шаблоны
$container['renderer'] = new \Slim\Views\PhpRenderer(__DIR__ . '/../templates');
В этих строчках происходит подключение шаблонизатора к Слиму, используя DI Container. Наши шаблоны будут храниться в папке templates в корне проекта.
Далее добавьте еще один обработчик:
<?php
$app->get('/users/{id}', function ($request, $response, $args) {
$params = ['id' => $args['id']];
// Указанный путь считается относительно базовой директории для шаблонов, заданной на этапе конфигурации
return $this->renderer->render($response, 'users/show.phtml', $params);
});
Метод render выполняет рендеринг указанного шаблона и добавляет результат в ответ. Сама функция принимает на вход три параметра:
- Объект ответа
- Путь до нужного шаблона внутри папки
templates - Набор параметров, которые будут доступны внутри шаблона. Сюда можно передавать все, что угодно.
И последний шаг, добавьте файл templates/users/show.phtml со следующим содержимым:
<h1>Hello, <?= $id ?></h1>
Расширение phtml используют тогда, когда хотят показать что внутри файла содержится шаблон на PHP, в остальном файл рассматривается как обычный файл с кодом на PHP.
Теперь откройте браузер и попробуйте загрузить страницу http://localhost:8000/users/nick
$ curl localhost:8000/users/nick
<h1>Hello, nick</h1>
Вместо кода <?= $id ?> на экране появилось значение переменной $id . Откуда она взялась в шаблоне? Наш шаблонизатор берет массив $params , который передается третьим параметром в метод render и создает внутри шаблона локальную переменную на каждый ключ этого массива. Причем имя переменной и ключа совпадают. Этот принцип работает всегда. Если вам нужно вывести данные на странице, то добавляйте их в массив $params и обращайтесь с ним в шаблоне через переменные.
Этой тактики следует придерживаться и для суперглобальных массивов. По понятным причинам их можно использовать напрямую:
<h1><?= $_GET['name'] ?></h1>
Но делать так ни в коем случае нельзя. Такой код значительно сложнее в отладке и потенциально очень опасен (подробнее об этом дальше по курсу).
Собирая все вместе
Теперь, когда мы добавили поддержку шаблонов во фреймворк, появляется способ создавать не тривиальные сайты. Ниже пример обработчика и шаблона для вывода курсов:
Обработчик
<?php
$app->get('/courses', function ($request, $response) use ($courses) {
$params = [
'courses' => $courses
];
return $this->renderer->render($response, 'courses/index.phtml', $params);
});
Шаблон
<table>
<?php foreach ($courses as $course): ?>
<tr>
<td>
<?= $course['id'] ?>
</td>
<td>
<?= $course['name'] ?>
</td>
</tr>
<?php endforeach ?>
</table>
<!-- END -->
Дополнительные материалы
Веб-разработка на PHP → Безопасность
Безопасность сайтов, тема о которой редко говорят с новичками, но от которой зависит судьба любого бизнеса. Проблемы с безопасностью могут привести к утечеке данных пользователей и даже к полному уничтожению сайта. Исследования показывают, что подавляющее большинство сайтов имеют проблемы с безопасностью и подвержены атакам. Время от времени случаются громкие взломы и утечки данных сотен тысяч и миллионов пользователей.
Я уверен что говорить о безопасности нужно как можно раньше, это позволит избежать фатальных ошибок.
Главное правило касающееся безопасности звучит так: “Никогда не доверяйте пользователям”. В первую очередь это правило касается данных которые они вводят. Возьмем пример из предыдущего урока, практику, в которой выводилось имя пользователя взятое из адреса: /users/nick . Код который реализует эту функциональность, рассчитывает на то, что в адресе используются только допустимые имена. Но что если попытаться открыть такой адрес:
# Запустите сервер для приложения созданного в предыдущем уроке
# Попробуйте открыть этот адрес в FireFox, потому что Chrome и Safari блокируют его,
# они знают про то что такой код вредоносный.
http://localhost:8000/users/%3Cscript%3Ealert('attack!')%3B%3C%2Fscript%3E

В этом адресе закодирован код на JavaScript, который в оригинале выглядит так:
<script>
alert('attack!');
</script>
Проблема в том, что этот код не отобразился, а был вставлен в HTML как часть этого HTML и соответствовано выполнился. Для браузера такой JS выглядит как часть страницы. Если попробовать открыть получившийся HTML, то он будет выглядеть так:
<h1><script>alert('attack!');</script></h1>
Совсем не то что мы ожидали. Такая атака называется XSS или Межсайтовый скриптинг. Она работает так, на страницу внедряется вредоносный код, который выполняется в браузере пользователя и отправляет информацию о пользователе на сервер злоумышленника. Специфика подобных атак заключается в том, что вредоносный код может использовать авторизацию пользователя в веб-системе для получения к ней расширенного доступа или для получения авторизационных данных пользователя. XSS относится к одному из самых распространенных типов атак из-за большого количества уязвимостей даже на сайтах больших и серьезных компаний таких как Facebook.
Уязвимость возникает из-за доверия пользовательским данным. В нашем коде вывод слага делается, без какой-либо предварительной обработки, это в корне неверно. Дело в том, что браузер пытается интерпретировать как HTML все что похоже на HTML. Если в исходном коде встречается конструкция <текст> , то браузер автоматически считает ее тегом. Для вывода данных, которые не рассматриваются как HTML, обязательно использовать специализированные функции превращающие теги в html entities.
<?php
$str = "A 'quote' is <b>bold</b>";
// Outputs: A 'quote' is <b>bold</b>
echo htmlspecialchars($str);
Получившаяся строка содержит безопасное описание тегов в виде html entities. Например < отобразиться как < , а > как > . Возвращаясь к нашему примеру, правильный вывод в шаблоне должен пропускаться через функцию htmlspecialchars .
<h1><?= htmlspecialchars($id) ?></h1>
Теперь мы получим тот вывод, который изначально ожидали.

Тоже самое касается любого другого вывода. В следующих уроках мы начнем активно использовать формы в которых подобная уязвимость встречается очень часто.
К сожалению PHP никак не защищает нас от подобных уязвимостей. Необходимо постоянно держать в голове такую возможность и не забывать вызывать функцию htmlspecialchars . На практике вы обязательно забудете), таков человеческий фактор. Это одна из причин почему популярны другие шаблонизаторы. В большинстве из них любые выводимые данные автоматически пропускаются через функцию подобную htmlspecialchars , что гарантирует безопасность без необходимости задумываться о ней.
Кроме XSS часто встречаются и другие виды атак, например SQL Injection, но для их понимания нужно владеть самим инструментом. В будущих уроках и курсах я буду эпизодически затрагивать тему безопасности с примерами типичных ошибок и способах защиты.
Дополнительные материалы
Веб-разработка на PHP → Поисковые формы
HTML Формы - основной инструмент для создания интерактивных сайтов. Через них происходит регистрация пользователя, добавление в друзья, оплата покупок, фильтрация товара в магазине и тому подобное. Самые простые формы - поисковые. Они ничего не изменяют и не создают, а используются только для фильтрации данных. Такой поиск реализован на Хекслете на странице курсов https://ru.hexlet.io/courses. Аналогичная строка поиска используется и в поисковых системах.
<form action="/courses" method="get">
<input type="search" required name="term">
</form>
Основной элемент формы тег <form> . Все элементы формы должны быть вложены в него. У этого тега один обязательный аттрибут action , в котором нужно указать адрес на который отправятся данные формы. Второй необязательный, но часто используемый аттрибут - method . Он принимает два возможных параметра get или post , что соответствует HTTP глаголам. Напомню что семантика этих глаголов в том, что GET используется для чтения информации и неизменяет состояние системы, а POST неидемпотентный глагол, который используется при отправке форм изменяющих состояние системы, например, во время регистрации нового пользователя. По умолчанию значение этого аттрибута get . После отправки формы этим методом, ее данные передаются как параметры запроса. Если в форму выше ввести строчку sql и нажать Enter, то браузер откроет страницу по адресу https://ru.hexlet.io/courses?term=sql . Такой страницей можно поделиться с другими людьми и они увидят те же данные (если выдача не персонализированная).
Интересный факт. Поисковые боты (программы индексирующие контент в интернете) распознают поисковые формы (смотрят что метод отправки GET) и пытаются их использовать для того чтобы добавить в индекс поисковых систем как можно больше данных.
Для элементов формы используются теги input, button, select и textarea.
В свою очередь тег <input> благодаря аттрибуту type может принимать множество различных форм:
- Множественный выбор (checkbox)
- Одиночный выбор (radio)
- Кнопка отправки формы (submit)
- Поле для ввода пароля (password)
- Множество других таких как: tel, email, range и т.п.
У всех элементов формы есть как общие, так и специфические аттрибуты. К общим аттрибутам относится имя. Его указание обязательно для всех элементов формы кроме кнопок, так как имя используется для доступа к содержимому. В примере выше используется текстовое поле с типом search и именем term . Именно поэтому после отправки формы в адресе появляется запись ?term=sql . Кроме того во всех формах почти всегда присутствует кнопка с типом submit , она отвечает за отправку данных. Имя кнопки задается через аттрибут value .
<input type="submit" value="Search">
Наличие кнопки отправки не обязательно. По умолчанию достаточно нажать Enter и браузер отправит форму на сервер.
К общим аттрибутам относится аттрибут required . Его наличие включает проверку обязательности заполнения на клиенте (в браузере). Попытка отправить форму с незаполненными элементами помеченными этим аттрибутом, приведет к показу сообщения о том что требуется заполнение. Не забывайте что клиентская проверка данных легко обходится посылкой данных в обход браузера (например через Curl). Поэтому проверка на клиенте не может быть основной, она лишь дублирует серверные проверки.
С точки зрения серверной части - никакой формы не существует. Выполняется обычный обработчик в который приходит типичный запрос с дополнительным набором параметров.
<?php
$app->get('/courses', function ($request, $response) {
$term = $request->getQueryParam('term', ''); // второй параметр - значение по-умолчанию
$courses = /* filter courses by term */;
$params = ['courses' => $courses];
return $this->renderer->render($response, "courses/index.phtml", $params);
});
Параметры хранятся в объекте запроса и могут быть извлечены либо все сразу getQueryParams либо по одиночке getQueryParam . Дальнейшая логика целиком и полностью зависит от программиста.
Последняя деталь в работе поисковых форм - подстановка текущих значений. Обычно форма поиска продолжает отображаться на странице результатов, причем ее поля заполнены значениями введенными пользователем. Для реализации этой возможности нужно выполнить два действия. Во-первых передать данные из объекта запроса в шаблон $params = ['term' => $term] . Во-вторых, подставить их в саму форму:
<form action="/courses" method="get">
<input type="search" name="term" value="<?= htmlspecialchars($term) ?>" />
<input type="submit" value="Search" />
</form>
Для подобного поля ввода нужно указать аттрибут value и подставить туда текущее значение не забыв его преобразовать в безопасную форму.
Веб-разработка на PHP → Персистентность
Среди сайтов выделяют такую категорию сайтов как “статические”. Их особенность в том что такие сайты, по сути, представляют собой готовый набор HTML страничек. Например так сделаны наши гайды http://guides.hexlet.io/. Удобно, быстро, дешево. Статическим сайтам не нужна возможность куда-то сохранять информацию, его данные хранятся прямо в HTML.
Для создания статических сайтов используют специальные генераторы сайтов https://jekyllrb.com/
Остальным сайтам повезло меньше. Все что создается пользователем, нужно куда-то сохранять. Самый простой способ сохранять - использовать файлы. Насколько он простой, настолько же нерабочий. Блокировки файловой системы не позволят работать с файлом в конкурентной среде, какой является веб, когда с сайтом могут одновременно работать сотни тысяч пользователей.
Здесь мы снова приходим к необходимости понимать устройство операционных систем. https://ru.hexlet.io/pages/recommended-books
Для постоянного (персистентного) хранения данных принято использовать специализированные программы - базы данных. Взаимодействие с ними строят двумя способами. Либо работая напрямую через библиотеку предназначенную для данной базы данных. Либо через ORM, которая в большинстве случаев прячет базу данных за горой абстракций.
<?php
// Doctrine ORM
$user = new User();
$user->setName($newUsername);
$entityManager->persist($user);
$entityManager->flush();
Тема хранения данных очень глубока и требует определенной подготовки, которая пока нами не рассматривалась. Это сделанно намеренно. Профессия построена так, чтобы мы как можно быстрее добрались до веба и научились с ним работать. Работа с базой данных рассматривается в следующих курсах. По этой причине в следующих уроках данные пользователя будут сохраняться в сессии (механизм работающий поверх Cookie), через предоставленную абстракцию.
<?php
# Хранилище объектов
$repo = new Repository();
// Сохранение
$repo->save($entity);
// Еще одно сохранение
$repo->save($entity2);
// Извлечение по идентификатору
$repo->find($entity['id']); // $entity
// Извлечение всех сущностей
$repo->all(); // [$entity, $entity2]
Веб-разработка на PHP → Модифицирующие формы
Формы изменяющие данные, устроены сложнее как с клиентской стороны, так и с серверной. Для уверенной работы с ними необходимо разбираться в следующих вопросах:
- Знание соответствующих HTML тегов.
- Понимание того как отправляются формы по HTTP.
- Обработка на стороне сервера.
- Валидация и вывод ошибок.
Начнем с того что за вывод формы и ее обработку должны отвечать два разных обработчика (а значит это разные маршруты). Ниже пример маршрутов для создания нового пользователя:
- GET
/users/new- страница с формой, которую заполняет пользователь. Эта форма отправляет POST запрос на адрес/usersуказанный в аттрибутеaction. - POST
/users- маршрут обрабатывающий данные формы
Я выбрал именно такие маршруты не случайно. Подобная схема именования рекомендуется и автоматически создается многими фреймворками, такими как Rails. Она хорошо ложится на REST архитектуру, о которой мы еще поговорим.
Форма
<!-- templates/users/new.phtml -->
<form action="/users" method="post">
<div>
<label>
Имя
<input type="text" name="user[name]">
</label>
</div>
<div>
<label>
Email
<input type="email" required name="user[email]">
</label>
</div>
<div>
<label>
Пароль
<input type="password" required name="user[password]">
</label>
</div>
<div>
<label>
Подтверждение пароля
<input type="password" required name="user[passwordConfirmation]">
</label>
</div>
<div>
<label>
Город
<select name="user[city]">
<option value="3">Москва</option>
<option value="13">Пенза</option>
<option value="399">Томск</option>
</select>
</label>
</div>
<input type="submit" value="Sign Up">
</form>
Интересный момент в форме выше, то как задаются имена. Каждое имя определяется как ключ в массиве user . Такой способ определения имен не является обязательным, но он очень удобен для массовой обработки значений формы. Их изоляция в одном массиве позволяет избежать потенциальных пересечений с другими данными. В поисковых форма эта схема тоже удобна если количество элементов больше одного.
Здесь стоит сказать, что с точки зрения HTTP не существует способа передавать массивы. Если не указано иного, то данные формы кодируются в теле запроса как application/x-www-form-urlencoded . Чисто технически это выглядит как query string, пары ключ-значения объединенные символом & .
POST /users HTTP/1.1
Host: example.com
Content-type: application/x-www-form-urlencoded
Content-length: 42
key=value&key2=value2&user%5Bname%5D%3Djon
В конце тела закодирован ключ user[name] . Превращение таких ключей в массив идет на уровне интерпретатора, в случае PHP, либо самого фреймворка в случае остальных языков.
Обработка данных
<?php
$repo = new Repository();
$app->post('/users', function ($request, $response) use ($repo) {
$validator = new Validator();
$user = $request->getParsedBodyParam('user');
$errors = $validator->validate($user);
if (count($errors) === 0) {
$repo->save($user);
return $response->withRedirect('/');
}
$params = [
'user' => $user,
'errors' => $errors
];
return $this->renderer->render($response, "users/new.phtml", $params);
});
Обработка данных формы начинается с извлечения данных из тела запроса. Для этого используется метод getParsedBodyParam , который позволяет достать значение по конкретному ключу. Если нужно получить сразу все, то подойдет метод getParsedBody .
<?php
$user = $request->getParsedBodyParam('user');
Далее нужно убедиться в том что данные введены верно. Процесс проверки корректности данных называется валидацией. Slim, как и большинство микрофреймворков не предоставляет никаких механизмов для валидации. Ее можно получить из сторонних библиотек. В простейшем случае валидация реализуется простой функцией, которая проверяет данные формы и формирует специальный массив $errors , в котором ключ это название поля, а значение это текст ошибки, который нужно вывести в форме.
<?php
$errors = validate($user);
// function validate($user)
// {
// $errors = [];
// if (empty($user['name'])) {
// $errors['name'] = "Can't be blank"
// }
//
// // ...
//
// return $errors;
// }
Если ошибок нет, то данные формы сохраняются, например, в базу данных. Об этом подробнее в следующем уроке. После сохранения выполняется перенаправление (HTTP redirect), как правило, на главную страницу. За перенаправление отвечает метод withRedirect объекта $response . Результат вызова withRedirect необходимо вернуть из обработчика, только тогда Slim поймет что нужно делать перенаправление.
<?php
if (count($errors) === 0) {
$repo->save($user);
return $response->withRedirect('/');
}
Если в процессе обработки возникли ошибки, выполняется рендеринг формы из того же шаблона что мы использовали для /users/new . В этот шаблон передаются как данные формы так и список ошибок. Редиректа не проиcходит, в адресной строке остается адрес /users . Если попробовать в этот момент нажать f5, то браузер выдаст предупреждение о том что вы пытаетесь повторно отправить данные. Это сообщение предупреждает о том что метод POST не идемпотентен, и повторная отправка формы может привести к повторному созданию пользователя.
<?php
$params = [
'user' => $user,
'errors' => $errors
];
return $this->renderer->render($response, "users/new.phtml", $params);
Теперь давайте вернемся к нашей форме и изменим ее так чтобы в нее подставлялись как возникающие ошибки, так и значения полей введеные пользователем.
<!-- templates/users/new.phtml -->
<form action="/users" method="post">
<div>
<label>
Имя
<input type="text" name="user[name]" value="<?= htmlspecialchars($user['name'] ?? '') ?>">
</label>
<?php if (isset($errors['name'])): ?>
<div><?= $errors['name'] ?></div>
<?php endif ?>
</div>
<div>
<label>
Email
<input type="email" required name="user[email]" value="<?= ? htmlspecialchars($user['email'] ?? '') ?>">
</label>
<?php if (isset($errors['email'])): ?>
<div><?= $errors['email'] ?></div>
<?php endif ?>
</div>
<div>
<label>
Пароль
<input type="password" required name="user[password]" value="<?= htmlspecialchars($user['password'] ?? '') ?>">
</label>
<?php if (isset($errors['password'])): ?>
<div><?= $errors['password'] ?></div>
<?php endif ?>
</div>
<div>
<label>
Подтверждение пароля
<input type="password" required name="user[passwordConfirmation]" value="<?= htmlspecialchars($user['passwordConfirmation'] ?? '') ?>">
</label>
</div>
<div>
<label>
Город
<select name="user[city]">
<option value="">Select</option>
<option <?= isset($user['city']) && $user['city'] === '3' ? 'selected' : '' ?> value="3">Москва</option>
<option <?= isset($user['city']) && $user['city'] === '13' ? 'selected' : '' ?> value="13">Пенза</option>
<option <?= isset($user['city']) && $user['city'] === '399' ? 'selected' : '' ?> value="399">Томск</option>
</select>
</label>
<?php if (isset($errors['city'])): ?>
<div><?= $errors['city'] ?></div>
<?php endif ?>
</div>
<input type="submit" value="Sign Up">
</form>
В свою очередь такое изменение формы требует изменения обработчика /users/new . Необходимо передать в шаблон пустые массивы $errors и $user во избежании ошибок.
<?php
$app->get('/users/new', function ($request, $response) {
$params = [
'user' => [],
'errors' => []
];
return $this->renderer->render($response, "users/new.phtml", $params);
}
Обратите внимание на то, как увеличилась в размерах форма. На практике она будет еще больше из-за дополнительного оформления, например, отступов и подсветки ошибок. Сделав десяток форм вы быстро поймете что так жить нельзя. Ради простейшей обработки придется писать много практического идентичного кода в HTML. Эта работа требует автоматизации и, к счастью, давно автоматизирована. Для генерации форм используются специальные билдеры. По традиции, микрофреймворки не имеют встроенных билдеров, поэтому придется искать их самостоятельно. Довольно популярны формы из фреймворка Symfony. В этом компоненте каждая форма представлена своим собственным классом. Компонент поддерживает валидацию имеет встроенные механизмы защиты от некоторых атак и многое другое.
Дополнительные материалы
Веб-разработка на PHP → Именованные маршруты
<form action="/users/<?= $user['id'] ?>" method="post">
<input type="hidden" name="_METHOD" value="DELETE">
<input type="submit" value="Remove">
</form>
В примере выше ссылка “зашита” прямо в шаблон. В принципе, ничего криминального, но дальше возможны осложнения. Что если маршрут изменится с /users/{id} на /u/{id} ? Придется пройтись по всем шаблонам и изменить все ссылки. А если этот маршрут удалить? Сайт продолжит работать (и не приемочные тесты тоже), хотя будет лучше если страницы с такими ссылками начнут выдавать ошибки. Тогда выявить подобные ссылки станет крайне просто особенно если есть тесты.
Для решения этой задачи придумали именовать маршруты. Далеко не все микрофреймворки поддерживают именованные маршруты, но Slim здесь отличился в правильную сторону.
<?php
$app->get('/users', function ($request, $response) {
// ...
})->setName('users');
$app->get('/users/{id}', function ($request, $response) {
// ...
})->setName('user');
Метод setName задает имя маршрута. Построить маршрут по имени можно используя метод pathFor объекта Router .
<?php
$app->get('/', function ($request, $response) {
$this->router->pathFor('users'); // /users
$this->router->pathFor('user', ['id' => 4]); // /users/4
});
К сожалению, PHP-View, который мы используем, не прокидывает этот метод в шаблоны, в отличие от Twig-View. Мой совет: используйте в своих приложениях последний.
Веб-разработка на PHP → Стандарт PSR7
Объекты запроса и ответа во фреймворке Slim имеют интерфейс соответствующий стандарту PSR7. Пример на главной странице фреймворка как раз демонстрирует это.
<?php
use \Psr\Http\Message\ServerRequestInterface as Request;
use \Psr\Http\Message\ResponseInterface as Response;
require 'vendor/autoload.php';
$app = new \Slim\App();
$app->get('/hello/{name}', function (Request $request, Response $response, array $args) {
$name = $args['name'];
return $response->write("Hello, {$name}");
});
$app->run();
Цель PSR-7 предоставить общий набор интерфейсов для фреймворков, чтобы последние могли использовать одинаковые абстракции. Это позволит разработчикам писать переиспользуемый, независимый от фреймворка код. Сам стандарт довольно объемный и не имеет смысла его дублировать. Здесь мы поговорим только о ключевых особенностях.
Request и Response, с точки зрения стандарта, представляют собой абстракцию поверх механизмов встроенных в сам PHP. Например они полностью заменяют собой суперглобальные массивы, механизм загрузки файлов и многое другое.
<?php
// Возвращает значение заголовка Host
$request->getHeader('Host');
// Проверяет был ли указан заголовок
$request->hasHeader('Accept');
Эти методы работают не только для запроса, но и для ответа. Дело в том что оба эти интерфейса Request и Response , имеют общую часть, которая называется Message , другими словами, многие методы повторяются и одинаково работают в каждом из этих объектов.
Названия заголовков в PSR7, как и в самом HTML регистренизависмы. В тоже время, в самом PHP, заголовки всегда переводятся в верхний регистрир и хранятся в массиве $_SERVER префиксом HTTP_ .
<?php
// Возвращает массив заголовков, в котором значения заголовков разделены по элементам массива
foreach ($request->getHeaders() as $name => $values) {
echo $name . ': ' . implode(', ', $values);
}
Response
Ответ аккумулируют внутри себя то что отправится клиенту, но он изначально не пустой, а содержит некоторые разумные умолчания:
<?php
// Статус ответа. По умолчанию 200.
$status = $response->getStatusCode();
А вот с изменением все не так просто. Главная отличительная черта этого интерфейса в том, что он построен в иммутабельном (неизменяемом) стиле и реализует fluent interface. Запрос невозможно “изменить”. Вместо этого, всегда возвращается новый объект.
<?php
// response не меняется!
$newResponse = $response->withStatus(302);
$newResponse == $response; // false
По этой причине, во фреймворках поддерживающих стандарт PSR7, обработчик запроса всегда должен вернуть объект ответа, только в этом случае фреймворк узнает о том как надо ответить на запрос.
<?php
return $response->withStatus(500)
->withHeader('Content-Type', 'text/html')
->write('Something went wrong!');
Дополнительные материалы
Веб-разработка на PHP → Flash
Работая на Хекслете вы не раз видели сообщение о результатах выполнения любого действия — будь то аутентификация, регистрация или вступление в курс.

В веб-разработке такое сообщение называют Flash. Оно обычно используется после перенаправления для индикации успешности или неуспешности предыдущего действия. Flash сообщения используют механизм сессий, который мы пока не рассматривали. Этот механизм позволяет хранить информацию между разными запросами одного и того же пользователя. В свою очередь механизм сессий работает благодаря кукам и встроен в PHP. Подробнее о сессиях мы поговорим в соответствующем уроке, а пока используем его без погружения.
<?php
// Старт PHP сессии
session_start();
$app = new \Slim\App();
$container = $app->getContainer();
$container['flash'] = function () {
return new \Slim\Flash\Messages();
};
$app->get('/foo', function ($req, $res) {
// Добавление flash сообщения. Оно станет доступным на следующий HTTP запрос.
$this->flash->addMessage('Test', 'This is a message');
// Redirect
return $res->withStatus(302)->withHeader('Location', '/bar');
});
$app->get('/bar', function ($req, $res, $args) {
// Извлечение flash сообщений установленных на предыдущем запросе
$messages = $this->flash->getMessages();
print_r($messages);
});
$app->run();
Если используется шаблонизатор, то сообщения передаются в шаблон и там выводятся. После их извлечения хранилище обнуляется. При следующем запросе getMessages вернёт пустой массив.
Под капотом у флеш сообщений используются сессии, которые рассматриваются в курсе чуть позже. Благодаря этому механизму, сайт запоминает конкретного пользователя и его сообщение.
Веб-разработка на PHP → CRUD
Несмотря на огромное число разнообразных сайтов, практически всю веб разработку можно свести к CRUD операциям. CRUD широко распространенный термин, означающий 4 стандартные операции над любой сущностью (ресурсом): создание, чтение, обновление и удаление. Например в случае с пользователем можно составить такое соответствие:
Create
- Регистрация
Read
- Просмотр профиля пользователями сайта
- Просмотр пользователя в административном интерфейсе
Update
- Обновление личных данных
- Смена емейла
- Смена пароля
Delete
- Удаление
Точно так же можно расписать действия над любыми другими ресурсами, фотографиями пользователя, его друзьями, сообщениями и т.п.
Хозяйке на заметку. Иногда в качестве шутки веб-разработчиков называют крудошлепами, а фронтенд-разработчиков формошлепами 
Создание полного круда включает в себя следующие действия:
- Создание сущности в коде (как правило класса)
- Добавление таблицы в базу
- Написание тестов на обработчики
- Добавление обработчиков
- Добавление шаблонов
Новички тратят на создание такого круда не один день. У опытного разработчика, в прокаченном фреймворке, этот процесс занимает максимум часы. Slim, как и другие микрофреймворки, не предоставляет никаких средств автоматизации, поэтому придется многое делать руками. В целях обучения это оправданно, но в промышленной разработке, то что может быть автоматизировано, должно быть автоматизировано.
Ниже мы пройдемся по всему процессу создания круда пользователя за исключением работы с базой данных и тестов. Начнем с роутинга. Полный круд пользователя включает минимум 7 маршрутов. Их может быть больше, так как любое из действий может повторяться не один раз.
| Глагол | Маршрут | Шаблон | Описание |
|---|---|---|---|
| GET | /users | users/index.phtml | Список пользователей |
| GET | /users/{id} | users/show.phtml | Профиль пользователя |
| GET | /users/new | users/new.phtml | Форма создания нового пользователя |
| POST | /users | Создание нового пользователя | |
| GET | /users/{id}/edit | users/edit.phtml | Форма редактирования пользователя |
| PATCH/PUT | /users/{id} | Обновление пользователя | |
| DELETE | /users/{id} | Удаление пользователя |
Такое соглашение изначально появилось в Rails и затем было адаптировано во многих фреймворках на языках отличных от Ruby.
В этом уроке мы разберем первые два маршрута (просмотр списка и конкретного ресурса), а остальные в следующих уроках.
Список (index)
Вывод списка чего-нибудь мы уже делали не раз. Повторим для закрепления. Общий алгоритм действий такого обработчика всегда проходит по одному сценарию и не зависит от языка программирования:
- Извлекаем список из хранилища (базы данных). Обычно с учетом пейджинга.
- Передаем данные в шаблон
- Выводим данные в шаблоне используя цикл
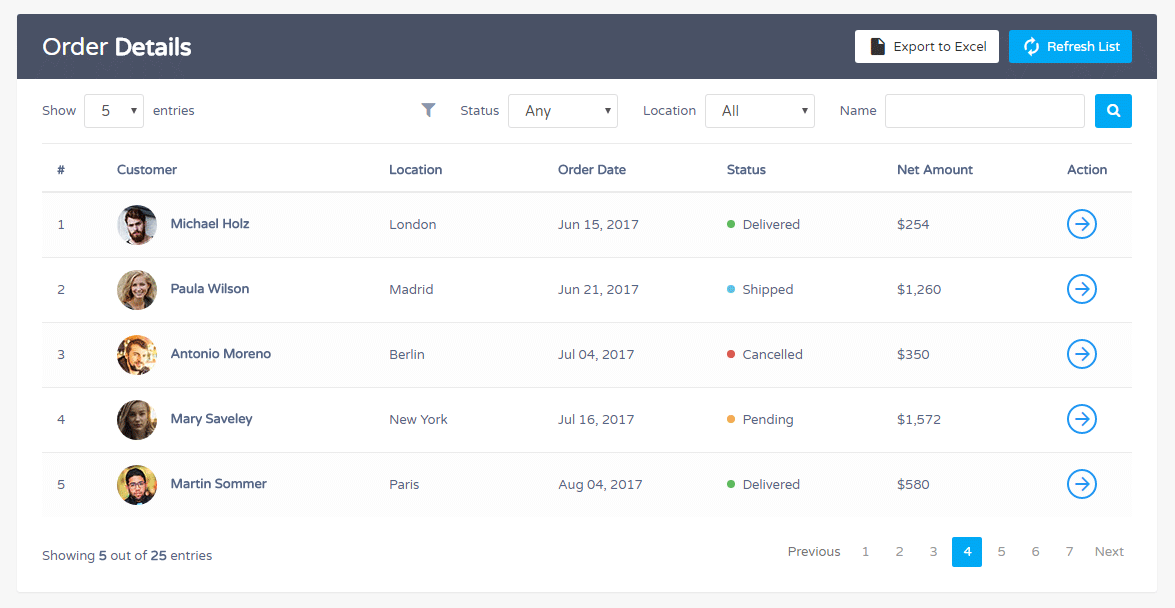
Обычно в этот список добавляют различные действия, которые можно выполнять над сущностями, например, редактирование, удаление или просмотр.
Обработчик
<?php
$app->get('/schools', function ($request, $response) {
$repository = new SchoolRepository();
$schools = $repository->all();
$params = ['schools' => $schools];
return $this->renderer->render($response, "schools/index.phtml", $params);
})->setName('schools');
Шаблон
<table>
<?php foreach ($schools as $school): ?>
<tr>
<td>
<?= $school['id'] ?>
</td>
<td>
<a href="/schools/<?= $school['id'] ?>"><?= $school['name'] ?></a>
</td>
</tr>
<?php endforeach ?>
</table>
Отображение (show)
Страница конкретной сущности. Например на Хекслете к таким страницам относятся: профиль пользователя, страница курса, страница профессии, страница урока и многие другие. Как и в случае со списком, порядок действий для отображения всегда один и тот же:
- Из адреса извлекается идентификатор сущности
- Выполняется поиск сущности в хранилище
- Она передается в шаблон
- В шаблоне рисуется красивый вывод
Обработчик
<?php
$app->get('/schools/{id}', function ($request, $response, array $args) {
$id = $args['id'];
$repository = new SchoolRepository();
$school = $repo->find($id);
$params = [
'school' => $school
];
return $this->renderer->render($response, "school/show.phtml", $params);
})->setName('school');
Шаблон
<?php foreach ($school as $key => $value): ?>
<div>
<?= $key ?>: <?= $value ?>
</div>
<?php endforeach ?>
А если сущность была удалена или ее вообще не существовало, как тогда должен вести себя сайт? С точки зрения HTTP такой адрес должен вернуть HTTP код 404. Сделать это можно явно, вернув соответствующий ответ.
<?php
$app->get('/schools/{id}', function ($request, $response, array $args) use ($repo) {
$id = $args['id'];
$school = $repo->find($id);
if (!$school) {
return $response->withStatus(404)->write('Page not found');
}
});
Но обычно механизм обработки таких ошибок построен через исключения. С ними мы познакомимся в следующих курсах.
Дополнительные материалы
Веб-разработка на PHP → CRUD: Создание
Создание сущности, включает в себя два действия: отображение формы и обработка данных формы. За каждое из этих действий отвечает свой собственный маршрут. Вот несколько примеров:
Пользователь
- GET
/users/new - POST
/users
Курс
- GET
/courses/new - POST
/courses
Сотрудник компании (пример вложенного маршрута)
- GET
/companies/3/users/new - POST
/companies/3/users
Отображение формы
Обработчик
<?php
$app->get('/schools/new', function ($request, $response) {
$params = [
'schoolData' => [],
'errors' => []
];
return $this->renderer->render($response, 'schools/new.phtml', $params);
})->setName('newSchool');
Шаблон
<form action="/schools" method="post">
<div>
<label>
Название *
<input type="text" name="school[name]" value="<?= htmlspecialchars($schoolData['name']) ?? '') ?>">
</label>
<?php if (isset($errors['name'])): ?>
<div><?= $errors['name'] ?></div>
<?php endif ?>
</div>
</div>
<input type="submit" value="Create">
</form>
Содержимое обработчика очень сильно зависит от того, какой используется инструментарий. В тех местах где есть билдеры форм, в этом обработчике создается форма (как некоторый объект) и отправляется в шаблон. Билдер берет на себя огромное количество задач, он сам обрабатывает вывод ошибок, занимается валидацией и подготовкой данных. Особо умные билдеры знают про ту сущность с которой они рабоают и могут строить формы в полностью автоматическом режиме.
В нашем примере ничего такого нет, поэтому все действия делаются руками. Кроме непосредственно данных, в шаблон передается массив errors . Это нужно по той причине, что форма используется обоими обработчиками: одним только для отображения новой формы, другим для отображения формы в случае наличия ошибок.
Обработка данных формы
<?php
$app->post('/schools', function ($request, $response) {
$repo = new SchoolRepository();
// Извлекаем данные формы
$schoolData = $request->getParsedBodyParam('school');
$validator = new Validator();
// Проверяем корректность данных
$errors = $validator->validate($schoolData);
if (count($errors) === 0) {
// Если данные корректны, то сохраняем, добавляем флеш и выполняем редирект
$repo->save($schoolData);
$this->flash->addMessage('success', 'School has been created');
// Обратите внимание на использование именованного роутинга
return $response->withRedirect($this->router->pathFor('schools'));
}
$params = [
'schoolData' => $schoolData,
'errors' => $errors
];
// Если возникли ошибки, то устанавливаем код ответа в 422 и рендерим форму с указанием ошибок
$response = $response->withStatus(422);
return $this->renderer->render($response, 'schools/new.phtml', $params);
});
Своего шаблона у таких обработчиков не делают. Если данные оказались не валидны, то этот обработчик рисует форму обработчика new и отправляет ее вместе с кодом ответа 422 (Unprocessable Entity).
Веб-разработка на PHP → CRUD: Обновление
Обновление самое сложное действие из всех по объему действий. С точки зрения кода новое здесь только одно - заполнение сущности данными формы: $school['name'] = $data['name']; . Этот процесс сильно изменится при использовании ORM, а пока мы будем проставлять каждое значение руками.
Обработчик формы
<?php
$app->get('/schools/{id}/edit', function ($request, $response, array $args) {
$repo = new SchoolRepository();
$id = $args['id'];
$school = $repo->find($id);
$params = [
'school' => $school,
'errors' => []
];
return $this->renderer->render($response, 'schools/edit.phtml', $params);
});
Шаблон
<form action="/schools" method="post">
<input type="hidden" name="_METHOD" value="PATCH">
<div>
<label>
Название *
<input type="text" name="school[name]" value="<?= htmlspecialchars($schoolData['name']) ?? '') ?>">
</label>
<?php if (isset($errors['name'])): ?>
<div><?= $errors['name'] ?></div>
<?php endif ?>
</div>
</div>
<input type="submit" value="Create">
</form>
Обработчик действия
<?php
$app->patch('/schools/{id}', function ($request, $response, array $args) {
$repo = new SchoolRepository();
$id = $args['id'];
$school = $repo->find($id);
$data = $request->getParsedBodyParam('school');
// Ручное копирование данных из формы в нашу сущность
$school['name'] = $data['name'];
$validator = new Validator();
$errors = $validator->validate($school);
if (count($errors) === 0) {
$this->flash->addMessage('success', 'School has been updated');
$repo->save($school);
return $response->withRedirect($this->router->pathFor('editSchool', ['id' => $school['id']]));
}
$params = [
'school' => $school,
'errors' => $errors
];
$response = $response->withStatus(422);
return $this->renderer->render($response, 'schools/edit.phtml', $params);
});
Теоретически можно сделать и так $school = array_merge($user, $data) , но у этого подхода есть один фатальный недостаток. Такой способ абсолютно не безопасен, так как пользователь может послать данные в обход формы, например количество денег на счету и array_merge изменит их значение. Эту проблему решают те же пакеты, которые предоставляют Form Builder и, обычно, они сразу встроены во фреймворки.
Методы
Как вы уже знаете, HTML позволяет указывать только два метода внутри аттрибута method тега <form> . С точки зрения семантики HTTP это не совсем верно. POST предназначен для создания нового. Для изменения правильно использовать PATCH или PUT в зависимости от того как происходит обновление, а для удаления DELETE . Если посмотреть на определение обработчика выше, то там мы увидим использование PATCH . Но как это работает? Браузер все равно пошлет POST .
<?php
$app->patch('/schools/{id}', function ($request, $response, array $args) {
Большинство фреймворков использует один и тот же механизм для обхода этого ограничения. Он простой до безобразия. Если форма не поисковая, то данные в любом случае отправляются POST запросом, но в форму добавляется специальное скрытое поле с именем _METHOD , которое и говорит фреймворку, а какой метод мы бы хотели использовать:
<form action="/schools" method="post">
<input type="hidden" name="_METHOD" value="PATCH">
...
</form>
Веб-разработка на PHP → CRUD: Удаление
Удаление устроено даже проще чем вывод, но включает в себя много ньюансов. Вместо привычных GET и POST удаление делается запросом DELETE. По спецификации HTTP этот глагол идемпотентный. Это означает, что поведение, в случае наличия или отсутствия сущности, должно быть одинаковое, другими словами HTTP ответ этого обработчика не зависит от того удалена уже сущность или еще нет.
<?php
$app->delete('/schools/{id}', function ($request, $response, array $args) {
$repo = new SchoolRepository();
$id = $args['id'];
$repo->destroy($id);
$this->flash->addMessage('success', 'Repository has been deleted');
return $response->withRedirect($this->router->pathFor('schools'));
});
В процессе удаления есть и чисто интерфейсный момент, который начинающие разработчики упускают из виду. Кнопка удаления ни в коем случае не должна сразу удалять. Человеку свойственно ошибаться (а еще он любопытен) и вероятность что он нажмент на эту кнопку по ошибке, крайне высока. Правильный подход состоит в том чтобы спросить у пользователя, уверен ли он в том что хочет удалить. Если да, то только в этом случае удалять.
А что насчет безопасности? Удаление пользователя крайне опасная операция, которую нельзя выполнять всем подряд. Даже те кто могут это делать, должны проходить через процедуру подтверждения чтобы случайно не удалить пользователя. Имеет ли пользователь доступ к конкретным действиям определяется авторизацией.
Авториза́ция — предоставление определённому лицу или группе лиц прав на выполнение определённых действий; а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий. Авторизацию не следует путать с аутентификацией — процедурой проверки легальности пользователя или данных, например, проверки соответствия введённого пользователем пароля к учётной записи паролю Wiki.
То есть перед выполнением действия необходимо проверить авторизован ли пользователь на выполнение данного действия или нет. Авторизация, отдельная большая тема со своей теоретической базой. Как правило вопрос авторизации решается в каждом конкретном фреймворке самостоятельно, хотя на гитхабе можно найти обобщенные библиотеки.
И последний вопрос который осталось рассмотреть - отправка запроса на удаление. Как вы помните, HTML формы не поддерживают отправку методами отличными от GET и POST. Фреймворки выкручиваются из этой ситуации следующим образом. Если в форме задать скрытое поле с именем _METHOD и значением того глагола который нам нужен, то внутри фреймворка, до входа в обработчик, глагол будет заменен на то что был указан. Таким нехитрым способом фреймворки позволяют посылать любые запросы.
<form action="/users/<?= $user['id'] ?>" method="post">
<input type="hidden" name="_METHOD" value="DELETE">
<input type="submit" value="Remove">
</form>
Отдельно стоит сказать, что крайне важно соблюдать семантику HTTP. Ни в коем случае нельзя создавать HTML в котором удаление происходит GET запросом, например, по ссылке. Браузеры, их плагины и поисковые системы действуют в соответствии с семантикой HTTP. Если они видят обычную ссылку, то подразумевается что она не может выполнить деструктивных действий, а значит ее можно посетить. Даже если мы работаем в закрытой от поисковиков части сайта, в браузерах встроен механизм предзагрузки страниц, который с удовольствием вызовет все ссылки до которых сможет дотянуться на открытой странице. А плагины могут делать вообще все что угодно.