Для чего изучать MySQL
SQL представляет собой язык структурированных запросов, с помощью которого осуществляется манипулирование и управление реляционными базами данных. К этим данным могут относиться как простые email-ы и логины для авторизации, так и сложные высоконагруженные системы. Поэтому СУБД входит в арсенал основных инструментов веб-разработчика.
В процессе обучения MySQL с нуля вы узнаете, что включено в понятие реляционной базы данных, как правильно составлять запрос и прочие тонкости языка SQL.
Достаточный уровень владения языком SQL входит в перечень профессиональных требований со стороны большинства работодателей в области веб-разработки.
Эффективное использование MySQL требует владения его инструментарием, знаниями функциональных возможностей и особенностей. Курс MySQL охватывает ключевые аспекты языка. В учебную программу включены наиболее важные для веб-разработчиков темы.
Работа с MySQL
MySQL относится к числу баз данных, обеспечивающих наиболее простое администрирование на всех платформах. Кроме того, эта база данных не требовательна к ресурсам, поэтому может эксплуатироваться даже на персональных компьютерах с небольшим объемом оперативной памяти и жесткого диска. В связи с этим разработчики, использующие средства PHP, продолжительное время применяют MySQL для создания полной локальной среды разработки для веб на клиентских компьютерах всевозможных типов, даже на портативных.
Любой разработчик, работающий в среде PHP, способен самостоятельно администрировать базу данных MySQL, в отличие от некоторых других баз данных. Для того чтобы еще больше упростить задачу администрирования, можно воспользоваться многочисленными инструментальными средствами, которые не только предусмотрены в самой базе данных MySQL, но и могут быть получены от сторонних разработчиков.
Основными понятиями, с которыми следует ознакомиться на данном этапе, являются:
- база данных — контейнер для всей коллекции данных MySQL;
- таблица — вложенный в базу данных контейнер, в котором хранятся сами данные;
- строка — отдельная запись, в которой могут содержаться несколько полей;
- столбец — имя поля внутри строки.
Следует заметить, что я не пытаюсь воспроизвести точную терминологию, используемую в учебной литературе по реляционным базам данных, а хочу лишь дать простые, обычные определения, помогающие быстро усвоить основные понятия и приступить к работе с базой данных.
Доступ к MySQL из командной строки
Работать с MySQL можно тремя основными способами: используя командную строку, используя веб-интерфейс наподобие phpMyAdmin и используя такой язык программирования, как PHP. Третий из перечисленных способов будет рассмотрен в последующих статьях, а сейчас давайте рассмотрим первые два способа.
Если у вас в соответствии с инструкциями, изложенными в статье Установка и настройка OpenServer, установлен WAMP-сервер OpenServer, то доступ к исполняемой программе MySQL можно получить из следующего каталога:
C:\OSPanel\modules\database\MySQL-5.7-x64\bin
Вместо MySQL-5.7-x64 нужно подставить версию, указанную в настройках OpenServer во вкладке “Модули”.
Нужно открыть программу “Командная строка” и перейти в этот каталог. Делается это при помощи команды cd ПУТЬ_К_НУЖНОЙ_ПАПКЕ:
cd C:\OSPanel\modules\database\MySQL-5.7-x64\bin

После этого нужно запустить программу mysql.exe в этом каталоге, передав её специальный параметр. Для этого в командной строке теперь нужно выполнить команду:
.\mysql.exe -u root
В результате запустится MySQL-клиент. Он подключён к MySQL-серверу, который был запущен при старте OpenServer-a.

Если это не приведет к желаемому результату и будет выдано сообщение об ошибке подключения к серверу MySQL «Can’t connect to MySQL server on ‘localhost’», убедитесь, что OpenServer запущен и в модулях указан MySQL.
Параметр -u расшифровывается как user. То есть это флажок для указания пользователя, под которым нужно подключиться к серверу. root - это самый главный пользователь в MySQL. Он создаётся при установке сервера и по умолчанию у него нет пароля.
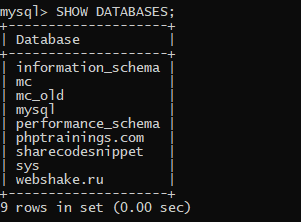
Но вернёмся к нашему терминалу. Через этот консольный клиент мы можем отправлять различные команды серверу. Давайте выполним команду, которая выводит все базы данных, созданные на этом сервере.
SHOW DATABASES;
В ответ мы получим красиво оформленный список баз. У вас их будет меньше, чем у меня, потому что я их уже добавлял.
Работа с MySQL через phpMyAdmin
Для управления базами данных и таблицами будет намного проще и быстрее использовать программу phpMyAdmin. Перед тем как вводить в адресную строку браузера следующую строку, нужно убедиться в том, что программа OpenServer уже запущена и, значит, база данных MySQL готова к работе:
http://127.0.0.1/openserver/phpmyadmin/index.php
Тут нас встретит вот такое красивое окошечко для входа в систему.
Также как и в случае с консольным приложением указываем пользователя root и оставляем пустым пароль. Жмём “войти”.
После этого вы попадёте в панель управления базами данных с довольно дружелюбным интерфейсом. Слева вы увидите всё тот же список баз данных, который вы получали в консольной версии. Можете по ним потыкать, посмотреть, что там внутри.
А сейчас давайте нажмём на вкладку SQL и перейдём в окно, где можно напрямую писать запросы к СУБД MySQL, как это было бы в консоли:

В открывшемся окне введите всё тот же запрос:
SHOW DATABASES;
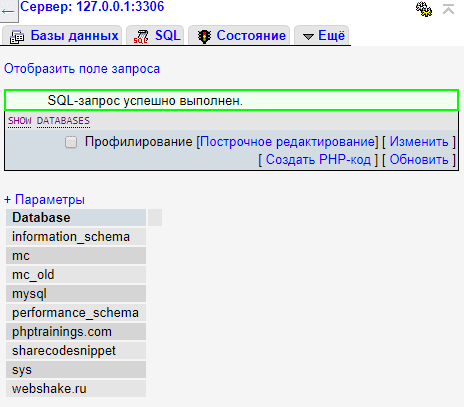
Нажимаем кнопку “вперёд” и видим тот же результат, что и в случае с консольным приложением.
Основные понятия языка SQL
По словам Эндрю Тейлора (Andrew Taylor), разработавшего язык SQL, название этого языка не является сокращением от Structured Query Language (или от чего-то подобного), хотя многие считают, что так оно и есть. Язык SQL лежит в основе более строгого и более общего метода хранения данных по сравнению с предыдущим стандартом организации баз данных в стиле DBM, который основан на использовании плоских файлов.
Язык SQL определен стандартами ANSI (American National Standards Institute) и ECMA (European Computer Manufacturer’s Association); обе эти организации по стандартизации являются международно признанными. Но следует учитывать, что в общих рекомендациях стандартов SQL наблюдаются заметные различия, касающиеся программных продуктов коммерческих компаний, с одной стороны, и организаций, занимающихся разработкой баз данных с открытым исходным кодом, с другой. Например, за последние несколько лет наблюдалось стремительное развитие так называемых объектно-реляционных баз данных, а также программных продуктов SQL, специально предназначенных для рынка веб. Перечень баз данных, которые могут применяться в сочетании с системой PHP, чрезвычайно велик, поэтому при выборе наиболее подходящей базы данных необходимо руководствоваться определенными принципами.
Основной принцип состоит в том, что нужно прежде всего учитывать собственные потребности разработки или по крайней мере твердо знать, какой цели требуется достичь. Пытаясь ознакомиться с другими рекомендациями, вы встретите массу весьма убедительных сообщении с такими доводами, что буквально “нельзя обойтись” без некоторых развитых средств базы данных (таких как триггеры или хранимые процедуры) и любой программный продукт с поддержкой SQL, в котором отсутствуют эти средства, вряд ли заслуживает права называться продуктом SQL. Воспринимайте эти суждения с большой долей сомнения. Гораздо лучше самому составить список требуемых характеристик в порядке значимости, а затем заняться поиском программного продукта, который в наибольшей степени соответствует вашим требованиям.
Но, несмотря на сказанное выше, значительная часть средств поддержки языка SQL действительно соответствует стандарту. Поэтому в программах, как правило, неоднократно используется лишь несколько операторов SQL, независимо от того, какой конкретный программный продукт был выбран для внедрения.
По существу, база данных SQL имеет очень простую логическую структуру. Каждая конкретная инсталляция программного обеспечения SQL обычно может состоять из нескольких баз данных. Например, одна БД может применяться для хранения данных о заказчиках, а другая — содержать данные о товарах. (Возникает определенная сложность, связанная с тем, что сам сервер SQL и коллекции поддерживаемых этим сервером таблиц обычно принято обозначать общим термином база данных.) Каждая база данных содержит несколько таблиц, каждая таблица состоит из тщательно определенных столбцов, а каждая позиция в таблице может рассматриваться как внесенная в таблицу запись, или строка.
Любой сервер SQL поддерживает четыре так называемых оператора манипулирования данными, и в целом эти операторы лежат в основе подавляющего большинства операций, выполняемых с реляционной базой данных. Этими четырьмя основными операторами базы данных являются SELECT, INSERT, UPDATE и DELETE. Операторы SQL, называемые также командами — очень удобны и позволяют выполнять практически все необходимые действия в базе данных.
Важной особенностью указанных четырех операторов SQL является то, что они позволяют манипулировать только значениями, хранящимися в базе данных, но не воздействуют на структуру самой базы данных. Иными словами, команды на основе этих операторов могут использоваться, например, для ввода данных, а не для создания базы данных; с помощью таких команд можно удалить из базы данных любой фрагмент данных, но сама “оболочка” останется нетронутой, поэтому, в частности, нельзя присвоить другой базе данных, работающей под управлением того же сервера, имя существующей базы данных. Для того чтобы добавить или удалить столбцы, уничтожить целую базу данных, не оставив и следа, или создать новую базу данных, необходимо применить другие команды, такие как DROP, ALTER и CREATE.
Все эти операторы мы подробно рассмотрим в следующей статье, посвященной командам MySQL.
Команды MySQL
В предыдущей статье мы ознакомились со способами доступа к MySQL и дали общее определение языка структурированных запросов SQL. В этой статье мы познакомимся с наиболее часто используемыми командами MySQL на примере простой базы данных.
Для манипулирования данными используются команды языка SQL. Этот язык проектировался с целью упростить описание взаимоотношений между таблицами и строками, поэтому базы данных используют его для модификации данных в таблицах. Перед тем, как изучать команды, следует запомнить два важных положения, касающихся команд MySQL:
- Команды и ключевые слова SQL нечувствительны к регистру. Все три команды — CREATE, create и CrEaTe — абсолютно идентичны по смыслу. Но чтобы было понятнее, для команд рекомендуется использовать буквы верхнего регистра.
- Имена таблиц чувствительны к регистру в Linux и Mac OS X, но нечувствительны в Windows. Поэтому из соображений переносимости нужно всегда выбирать буквы одного из регистров и пользоваться только ими. Для имен таблиц рекомендуется использовать буквы нижнего регистра.
Создание баз данных и таблиц
Создание базы данных
Для создания новой базы данных вы можете использовать следующую команду:
CREATE DATABASE users;
При успешном выполнении команды будет выведено сообщение:

После создания базы данных с ней нужно будет работать, поэтому даем следующую команду:
USE users;
Если вы работаете в панели phpMyAdmin, то достаточно просто выбрать базу users в списке слева, а затем перейти во вкладку SQL. Теперь запросы будут выполняться непосредственно для это базы данных.
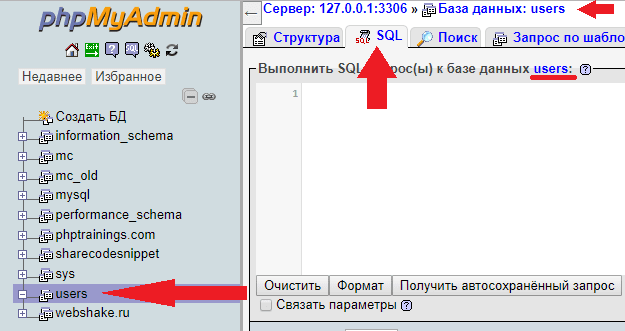
Теперь база данных будет готова к продолжению работы со следующими примерами.
Организация доступа пользователей
Важным фактором безопасной и эффективной эксплуатации MySQL является правильное применение системы прав доступа, предусмотренной в этой базе данных, и надлежащее использование инструментальных средств, предназначенных для управления правами доступа пользователей.
База данных MySQL позволяет чрезвычайно точно определять права доступа различных пользователей, которые подключаются к базе данных с помощью клиентских программ, находящихся в различных точках системы. Права доступа подразделяются на четыре нисходящих уровня: глобальные, базы данных, таблицы и столбцы. Поэтому теоретически предусмотрена возможность регламентировать доступ конкретного пользователя для записи данных только в указанные столбцы указанных таблиц указанных баз данных на указанном сервере MySQL. Столь же легко можно, не задумываясь, предоставить любому пользователю базы данных, подключающемуся откуда угодно, такие же права, как пользователю базы данных root (но такая организация защиты доступа категорически не рекомендуется).
Очевидно, что согласно требованиям защиты обычно следует руководствоваться хорошим эмпирическим правилом — предоставлять каждому пользователю только минимальные права доступа, без которых он вообще не мог бы выполнять свои функции.
Для добавления или редактирования прав доступа пользователей в базе данных MySQL могут применяться два разных способа (при условии, что модификацией прав доступа занимается пользователь базы данных root): непосредственное выполнение операторов SQL (например, ввод буквы Y вручную в каждое соответствующее поле каждой соответствующей таблицы прав доступа) или использование синтаксических конструкций GRANT и REVOKE. Последний способ является более легким и менее опасным, если допущена небольшая ошибка, поскольку в большинстве случаев попытка выполнения ошибочного запроса окончится неудачей с сообщением об ошибке SQL, но брешь в системе защиты при этом не возникнет.
Чтобы ввести информацию о новом пользователе MySQL, можно применить следующий оператор:
GRANT priv_type [(column1, column2, column3)]
ON database.[table]
TO 'user@host' IDENTIFIED BY 'new_password';
где данные о столбцах (column) и таблицах (table) являются необязательными, а с помощью списка, разделенного запятыми, могут быть заданы дополнительные сведения о типах прав доступа priv_types.
Если предоставлены права доступа ALL на уровне столбца, таблицы или базы данных, то пользователь получает возможность применять только тот набор прав доступа, который соответствует указанному уровню. Необходимо соблюдать исключительную осторожность при предоставлении пользователям следующих прав доступа, поскольку все эти права являются опасными: GRANT, ALTER, CREATE, DROP, FILE, SHUTDOWN, PROCESS. Такие права доступа не требуются ни одному обычному пользователю базы данных, особенно пользователю PHP.
Синтаксическая конструкция оператора отмены прав доступа весьма похожа на соответствующий оператор предоставления прав доступа, но проще него:
REVOKE priv_type [(column1, column2, column3)]
ON database.[table]
FROM user@host;
После предоставления или отмены прав доступа для любого пользователя необходимо вынудить базу данных выполнить перезагрузку в память новых данных о правах доступа. Для этого требуется ввести команду FLUSH PRIVILEGES . Можно также остановить и снова запустить сервер, но такое решение во многих обстоятельствах неприменимо на практике.
Безусловно, изложенные выше сведения вполне доступны для восприятия, но не дают ответа на такой вопрос: какие же права доступа должны быть фактически предоставлены действующим пользователям PHP? Рассмотрим некоторые случаи, которые часто встречаются на практике.
Локальный сервер, применяемый для разработки
Если доступ осуществляется исключительно локально, то применимы практически любые права доступа. Если в ходе разработки требуется проводить эксперименты со схемой базы данных, то наиболее подходящим является именно такая конфигурация, поэтому разработчику, кроме обычных прав доступа для выполнения операций SELECT, INSERT и UPDATE, могут быть предоставлены права доступа наподобие ALTER, CREATE, DELETE и DROP. При таких обстоятельствах многие администраторы считают приемлемым просто предоставить локальному пользователю права доступа ALL PRIVILEGES к определенной базе данных, как показано ниже (права этого пользователя мы будем использовать в последующих примерах):
GRANT ALL PRIVILEGES ON users.* TO superuser@localhost IDENTIFIED BY '12345';
Автономный веб-сайт
База данных, находящаяся на отдельном хосте, по-видимому, должна будет принимать запросы на установление соединений от многочисленных веб-серверов, находящихся в том же домене. На практике для всех серверных компьютеров должны предоставляться лишь права доступа SELECT, INSERT, UPDATE и, возможно, DELETE, хотя во многих системах удаление данных фактически не происходит, поэтому уровень безопасности немного повышается, если право доступа DELETE не предоставляется.
Кроме того, поскольку количество баз данных, подключающихся к производственной базе данных автономного веб-сайта, по-видимому, не слишком велико, то применение глобальных прав доступа приводит к ускорению работы и вместе с тем не создает более значительный реальный риск нарушения защиты. Поэтому допустимый оператор предоставления прав доступа может выглядеть следующим образом:
GRANT SELECT, INSERT, UPDATE ON *.* TO phpuser@%.example.com IDENTIFIED BY '12345';
Тем не менее в подобной ситуации чаще всего используется также репликация по принципу “ведущий-ведомый”. Часто подобные кластеры баз данных MySQL имеют такую конфигурацию, что все запросы на выполнение операций записи поступают в ведущую базу данных, но ведомые базы данных не выполняют никаких других действий, кроме очень быстрого обслуживания операций чтения. В таком случае в каждой ведомой базе данных предоставляются только права доступа SELECT, а в ведущей базе данных предоставляются только права INSERT И UPDATE; при этом, возможно, эти права назначаются двум разным пользователям базы данных.
Создание таблиц
Для определения структуры новой таблицы базы данных служит команда CREATE TABLE . Когда создается таблица базы данных, каждый столбец может содержать дополнительные параметры, помимо имени и типа данных. Если при добавлении новой записи в таблицу поле не должно оставаться пустым, в его определении указывается ключевое слово NOT NULL. Ключевое слово PRIMARY KEY определяет, какое поле будет использоваться в качестве первичного ключа. Автоматическое заполнение ключевого поля можно определить с помощью ключевого слова AUTO_INCREMENT. Например:
CREATE TABLE data (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR (32),
year CHAR(4),
PRIMARY KEY(id));
Для того чтобы проверить факт создания новой таблицы, наберите команду:
DESCRIBE data;
Если все в порядке, то вы увидите структуру новой таблицы:
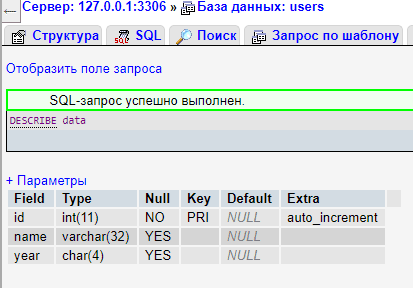
Команда DESCRIBE является неоценимым средством отладки, когда нужно убедиться в успешном создании таблицы MySQL. Этой командой можно воспользоваться также для того, чтобы просмотреть имена полей или столбцов таблицы и типы данных в каждом из них (это удобно при работе с консолью, при использовании phpMyAdmin успешные команды подсвечиваются зеленым цветом, а структуру таблицы можно посмотреть по ссылке главного меню “Структура”).
Типы данных MySQL
Типы данных MySQL подразделяются на три основные разновидности: числовые типы; типы, предназначенные для представления даты и времени; а также строковые (или символьные) типы. Применение этих типов данных в основном не связано с какими-либо сложностями, тем более, что для обычного пользователя сайта не имеет значения, например, какой тип данных применяется в сценариях для представления целочисленных данных, INT или MEDIUMINT. Однако программисты могут многое сделать, чтобы добиться создания наиболее компактных и быстродействующих баз данных.
В таблице ниже перечислены типы данных MySQL, предусмотренные в текущих версиях, и указаны их возможные значения:
Типы данных MySQL
| Обозначение | Занимаемый объем (байт) | Область применения |
|---|---|---|
| TINYINT, BOOL | 1 | При использовании в формате представления без знака позволяет хранить значения от 0 до 255; в противном случае — от -128 до 127. В будущем должен быть предусмотрен новый логический тип, но до сих пор для представления логических значений использовался тип данных TINYINT, т.е. BOOL синоним TINYINT(1) |
| SMALLINT | 2 | Целое число в диапазоне от -32768 до 32767 |
| MEDIUMINT | 3 | Целое число в диапазоне от -8388608 до 8388607 |
| INT, INTEGER | 4 | Целое число в диапазоне от -2e32 до 2e32 - 1 |
| BIGINT | 8 | Целое число в диапазоне от -2e64 до 2e64 - 1 |
| FLOAT | 4 | Число с плавающей точкой одинарной точности |
| DOUBLE | 8 | Число с плавающей точкой двойной точности |
| DECIMAL | Произвольное, в зависимости от точности | Распакованное число с плавающей точкой, которое хранится в таком же формате, как CHAR. Используется для представления небольших десятичных значений, таких как денежные суммы |
| DATE | 3 | Отображается в формате YYYY-MM-DD |
| DATETIME, TIMESTAMP | 8 | Отображается в формате YYYY-MM-DD HH:MM:SS |
| TIME | 3 | Отображается в формате HHH:MM:SS, где HHH — значение от -838 до 838. Это позволяет применять значения типа time для представления продолжительности времени между двумя событиями |
| YEAR | 1 | Отображается в формате YYYY, который представляет значения от 1901 до 2155 |
| CHAR | N байт | Строка постоянной длины. Строка, имеющая длину меньше объявленной, дополняется справа пробелами. Значение N должно быть меньше или равно 255 |
| VARCHAR | N байт | Строка переменной длины. Значение N должно быть меньше или равно 255 |
| BINARY | N байт | Сохраняет байтовые строки |
| TINYBLOB, TINYTEXT | до 255 | Сохраняет строки, операции сортировки и сравнения данных типа blob выполняются с учетом регистра; операции с данными типа text — без учета регистра |
| BLOB, TEXT | до 64 Кбайт | Длинные строки |
| MEDIUMBLOB, MEDIUMTEXT | до 16 Мбайт | Длинные строки |
| LONGBLOB, LONGTEXT | до 4 Гбайт | Длинные строки |
| ENUM(value1, …, valueN) | 1 или 2 | Коллекция значений (65536 возможных значений) |
| SET(value1, …, valueN) | до 8 | Коллекция значений (64 возможных значений) |
Тип данных AUTO_INCREMENT
Иногда нужно обеспечить уникальность каждой строки, имеющейся в базе данных. В вашей программе это можно сделать за счет тщательной проверки вводимых данных и обеспечения их различия хотя бы в одном из значений в любых двух строках. Но такой подход не гарантирует отсутствия ошибок и работает только в конкретных обстоятельствах. В общем виде эта проблема решается за счет специально выделенного для этой цели дополнительного столбца имеющего специальный тип AUTO_INCREMENT. В соответствии с названием столбца, которому назначен этот тип данных, его содержимому будет устанавливаться значение, на единицу большее, чем значение записи в этом же столбце в предыдущей вставленной строке.
Работа с таблицами
Добавление данных в таблицу
Для добавления данных предназначена команда INSERT. Используется она следующим образом:
INSERT INTO table COLUMNS ([столбцы]) VALUES ([значения]);
Здесь видно, что в команде необходимо указать, в какую таблицу будут добавляться данные, и определить список значений. Если перечень столбцов (COLUMNS) не указан, значения должны следовать в том же порядке, в каком определялись столбцы при создании таблицы (если вы не пропускаете какие-либо значения). Есть определенные правила, регламентирующие порядок заполнения базы данных с помощью команд SQL:
- числовые значения должны указываться без кавычек;
- строковые значения всегда должны быть в кавычках;
- значения даты и времени всегда должны быть в кавычках;
- функции должны указываться без кавычек;
- значение NULL никогда не должно заключаться в кавычки.
Наконец, если в строке отсутствует какое-либо значение, оно по умолчанию подразумевается равным значению NULL. Однако если поле не может иметь значение NULL (то есть когда оно было определено как NOT NULL), и вы не указали значение для этого поля, будет сгенерировано сообщение об ошибке.
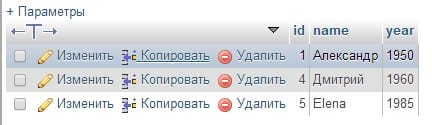
Давайте вставим в нашу таблицу data несколько пользователей:
INSERT INTO data VALUES(1, 'Александр', '1950');
INSERT INTO data VALUES(NULL, 'Дмитрий', '1960');
INSERT INTO data VALUES(NULL, 'Elena', '1985');
При добавлении данных вы должны указывать все столбцы, даже если для некоторых из них значения отсутствуют. Хотя мы и не задаем значение поля id, позволяя MySQL сделать это за нас, следует оставить на его месте метку-заполнитель.
В результате этих действий в таблице data появятся три записи. Теперь, когда вы знаете, как создать таблицу и записать в нее данные, нужно научиться извлекать эту информацию, но сначала затронем еще одну немаловажную особенность.
Кодировка таблицы
Если вы выполняли все приведенные выше примеры без внесения каких либо изменений, то при просмотре данных таблицы должны обратить внимание на одну неприятную особенность. Мы сохранили двух пользователей имеющих имя записанное русскоязычными символами. Если посмотреть данные в таблице, то можно увидеть что вместо символов вставились “кракозябры”:
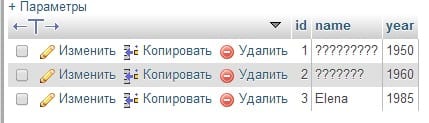
Как вы наверное догадались эта ошибка связана с неверной кодировкой таблицы. В моем случае по умолчанию стоит кодировка latin1, которая не позволяет отображать русскоязычные символы. Чтобы изменить кодировку таблицы на приемлемую (например UTF-8) нужно воспользоваться следующей конструкцией:
ALTER TABLE data CONVERT TO CHARACTER SET utf8;
Манипулирование определениями таблиц
Создав таблицу и начав заполнять ее информацией, вы можете обнаружить, что потребовалось изменить типы полей. Например, увеличить размер поля name, вмещающего 32 символа, до 100 символов. Можно было бы начать все с нуля, полностью переопределив таблицу, но при этом будут утеряны данные. К счастью, MySQL позволяет изменять типы полей без потери данных.
Переименование таблицы
Чтобы переименовать таблицу, следует использовать команду:
ALTER TABLE имя_таблицы RENAME новое_имя_таблицы
Следующая команда переименует таблицу data в users_data:
ALTER TABLE data RENAME users_data;
Изменение типа данных столбца
Чтобы изменить тип данных столбца, следует использовать команду:
ALTER TABLE имя_таблицы MODIFY имя_столбца тип_данных
Следующая команда изменит поле name таким образом, что оно будет вмещать до 100 символов:
ALTER TABLE users_data MODIFY name VARCHAR(100);
Кроме того, команда MODIFY может принимать два необязательных параметра, изменяющих порядок следования столбцов в таблице. С помощью ключевого слова FIRST можно сделать столбец первым в таблице, а с помощью ключевого слова AFTER имя_столбца – поместить столбец после указанного. Например, следующая команда разместит столбец name после столбца year:
ALTER TABLE users_data MODIFY name VARCHAR(32) AFTER year;
Добавление столбца
Добавить новый столбец позволяет команда:
ALTER TABLE имя_таблицы ADD имя_столбца тип_данных
Следующая команда добавит в таблицу users_data столбец типа DATETIME с именем regDate:
ALTER TABLE users_data ADD regDate DATETIME;
В этой команде, как и в конструкции ALTER TABLE MODIFY, можно определить позицию вставляемого столбца с помощью ключевых слов FIRST и AFTER имя_столбца.
Переименование столбца
Чтобы переименовать столбец, следует использовать команду:
ALTER TABLE имя_таблицы CHANGE старое_имя_столбца новое_имя_столбца
Ниже приводится пример переименования столбца regDate в regTime. При работе с этой командой вы можете одновременно изменять определение столбца. Однако даже если определение столбца не изменяется, вам все же придется указывать его полное определение:
ALTER TABLE users_data CHANGE regDate regTime DATETIME;
Удаление столбца
Если спустя некоторое время вы решите, что какой-то столбец вам больше не нужен, его можно просто удалить. Чтобы удалить столбец, следует использовать команду:
ALTER TABLE имя_таблицы DROP имя_столбца
Следующая команда удалит столбец regTime:
ALTER TABLE users_data DROP COLUMN regTime;
Удаление всей таблицы
Иногда требуется удалить и целую таблицу. Полное удаление таблицы со всеми данными выполняется с помощью команды DROP:
DROP TABLE table_name;
Будьте осторожны при удалении столбцов или таблиц. После выполнения операции данные будут безвозвратно утеряны, а отсутствие некоторых таблиц или столбцов может нарушить нормальную работу ваших программ.
В этом уроке мы разобрали команды для работы с таблицами и базой данных в целом. В следующем уроке мы научимся делать запросы к базе данных.
Выполнение запросов в MySQL
Бестолку хранить данные в таблицах, если у вас нет возможности просматривать их. Данные извлекают с помощью команды SELECT, которой передаются имя таблицы и условия для выборки строк.
Синтаксис команды SELECT:
SELECT столбцы FROM таблица
[WHERE условие отбора строк] [ORDER BY порядок сортировки];
Здесь столбцы – перечень имен полей, значения которых будут отбираться из таблиц. Необязательное ключевое слово WHERE задает ограничение на отбор строк, другими словами, ключевое слово WHERE ограничивает результаты, возвращаемые запросом. Например, строки могут быть отвергнуты запросом, если некоторое их поле не равно какому-либо значению, либо больше или меньше его. Ключевое слово ORDER BY позволяет определить требуемый порядок сортировки информации, возвращаемой запросом.
Самый простой запрос, позволяющий просмотреть содержимое таблицы, выглядит так:
SELECT * FROM users_data;
В нашем случае он выведет структуру и данные таблицы. Иногда в запросе вместо символа звездочки удобнее перечислить отбираемые столбцы:
SELECT name, year FROM users_data;
Ограничение результатов с помощью WHERE
Если вас интересует только какие-то определенные поля таблицы, вы можете ограничить набор возвращаемых данных с помощью ключевого слова WHERE, например:
SELECT * FROM users_data WHERE name="Александр";
Условные выражения должны следовать за ключевым словом WHERE. C помощью логических операторов AND и OR в конструкции WHERE можно определить сразу несколько условий. Порядок исполнения логических операторов изменяется с помощью круглых скобок ().
Определение порядка сортировки
Как уже говорилось, изменить порядок сортировки результирующего набора данных позволяет ключевое слово ORDER BY. По умолчанию ORDER BY задает сортировку в порядке возрастания, поэтому для сортировки пользователей в алфавитном порядке можно просто указать ORDER BY name. Чтобы назначить противоположный порядок сортировки, следует добавить ключевое слово DESC после имени поля name. Например, получить список пользователей, отсортированный в алфавитном порядке по убыванию, можно следующим запросом:
SELECT * FROM users_data ORDER BY name DESC;
Соединение таблиц
Инструкция SELECT позволяет выполнять запросы сразу к нескольким таблицам. В примере ниже создается таблица purchases (покупки), в которую добавляются несколько строк для примера. Затем формируется запрос для получения списка всех купленных товаров с указанием идентификатора покупателя:
-- Создать новую таблицу purchases
CREATE TABLE purchases (
purchaseId INT AUTO_INCREMENT,
user_name VARCHAR(32),
product VARCHAR(256),
date DATE,
PRIMARY KEY(purchaseId));
-- Поменять кодировку
ALTER TABLE purchases CONVERT TO CHARACTER SET utf8;
-- Наполнить данными
INSERT INTO purchases VALUES(1, 'Elena', 'Телефон Samsung Galaxy S3','2012-11-26 17:04:29' );
INSERT INTO purchases VALUES(NULL, 'Elena', 'Телефон Nokia Lumia','2013-04-05 12:06:55' );
-- Извлечь все заказы из таблицы purchases пользователя 'Elena' таблицы users_data
SELECT users_data.*, product FROM users_data, purchases WHERE users_data.name = purchases.user_name;
В результате вы получите:
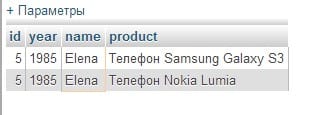
Часть запроса users_data. , product сообщает о необходимости выбрать все поля из таблицы users_data и единственное поле product из таблицы purchases. Часть связывает таблицы. Вы могли бы определить список отбираемых столбцов как ( ), тогда в результирующий набор попали бы все поля обеих таблиц.
Получить те же результаты, но меньше вводя с клавиатуры, позволяет ключевое слово NATURAL JOIN . При выполнении естественного соединения MySQL автоматически соединяет одноименные поля двух таблиц. В нашем случае мы не имеем одноименных полей, поэтому давайте это изменим и посмотрим на эту конструкцию в действии:
-- Переименуем столбец user_name таблицы purchases в name
ALTER TABLE purchases CHANGE user_name name VARCHAR(32);
-- Выполним естественное соединение
SELECT * FROM users_data NATURAL JOIN purchases;
Получим результат аналогичный предыдущему.
Конструкция JOIN ON похожа на инструкцию естественного соединения, но предоставляет возможность явно определить поля, по которым следует выполнять соединение, не полагаясь на автоматический выбор по их именам. Эта конструкция имеет следующий синтаксис:
SELECT столбцы FROM имя_таблицы JOIN таблицы ON (условия)
Псевдонимы
Перечисляя таблицы в запросе, используйте псевдонимы (aliases). Чтобы определить псевдоним таблицы, нужно после ее полного имени поставить ключевое слово AS и затем указать псевдоним. Например, присвоим в запросе таблице users_data псевдоним “u”, а таблице purchases псевдоним “p”:
SELECT * FROM users_data AS u, purchases AS p WHERE u.name = p.name;
Определив псевдоним таблицы, можно обращаться к ней по псевдониму в любом месте запроса. Псевдонимы удобны в качестве подмены длинных имен таблиц. Кроме того, они позволяют дважды включать в запрос одну и ту же таблицу и определять, в каком случае какой экземпляр таблицы следует использовать.
Модификация данных в базе данных
Если вы допустили ошибку при вводе данных, например указали неверное имя пользователя, ошибку можно исправить с помощью команды UPDATE. Для внесения изменений в таблицы есть много причин, например изменение пароля пользователя. В команде UPDATE используется то же ключевое слово WHERE, что и в инструкции SELECT, но в ней присутствует команда SET, с помощью которой определяется новое значение столбца. Если вы забудете включить ключевое слово WHERE в команду UPDATE, она изменит все записи в таблице.
Например, обновим таблицу user_data:
UPDATE users_data SET year = '1980' WHERE name = 'Александр';
Данный запрос изменит значение поля year для всех пользователей с именем ‘Александр’ в таблице users_data, установив его равным значению ‘1980’. Этот прием позволяет исправлять ошибочные данные и вносить изменения.
Удаление данных из базы
Команда DELETE удаляет строки или записи из таблицы. В команде DELETE используется то же ключевое слово WHERE, что и в инструкции UPDATE: удаляются все строки, соответствующие условию. В случае отсутствия ключевого слова WHERE будут удалены все записи в таблице.
Прежде чем воспользоваться командой DELETE, не забудьте создать резервные копии своих данных, в противном случае вы рискуете потерять все данные, нажив кучу неприятностей. В следующем примере из базы данных будет удален пользователь с id = 2:
DELETE FROM users_data WHERE id = 2;
Функции поиска
Как вы заметили в предыдущих примерах, MySQL обладает возможностью отыскивать конкретные данные. Однако мы пока еще не рассматривали синтаксис поиска. В MySQL роль шаблонного символа исполняет символ (%), используемый совместно с ключевым словом LIKE. То есть этим символом можно буквально представить все, что угодно. Это напоминает поиск файлов в проводнике Windows по строке *.doc – будут найдены все файлы документов, независимо от имен. По умолчанию поиск выполняется без учета регистра букв.
Например, выполнить общий поиск можно с помощью следующего синтаксиса:
SELECT * FROM users_data WHERE name LIKE "%р%";
Этот запрос нашел все записи, у которых в значении поля name есть символ (р). Заметим, что здесь мы использовали два символа (%), окружив ими символ (р) – (%р%). Это означает, что до и после искомого символа может быть что угодно. Если хотите, можете использовать только один шаблонный символ – жесткого правила на этот счет нет.
Символ (%), помещенный в любое место строки в инструкции LIKE, означает, что на этом месте в строке может быть что угодно. Еще один шаблонный символ – символ подчеркивания (_). Он соответствует любому единственному символу. С использованием этого шаблонного символа можно выполнить такой поиск:
SELECT * FROM users_data WHERE name LIKE "Elen_";
В результате будут получены все строки, где имя пользователя начинается с “Elen” и кончается любым символом.
К настоящему моменту получены все необходимые начальные сведения о командах MySQL. В следующей статье мы рассмотрим основные принципы оптимизации проектирования баз данных, способы резервного копирования и расширенные возможности языка SQL.
Проектирование базы данных MySQL
Тщательное проектирование базы данных чрезвычайно важно для безупречной работы приложения. Как установка принтера в дальнем конце офиса ведет к снижению производительности труда, размещение данных со слабыми взаимосвязями снижает эффективность и может вынудить сервер базы данных тратить значительное время на поиск требуемых данных. Разрабатывая структуру базы данных, задумайтесь о вопросах, возникающих при работе с ней. Например: «Какие дополнительные сведения имеются о продаваемом продукте?» Или: «Верны ли эти имя пользователя и пароль?»
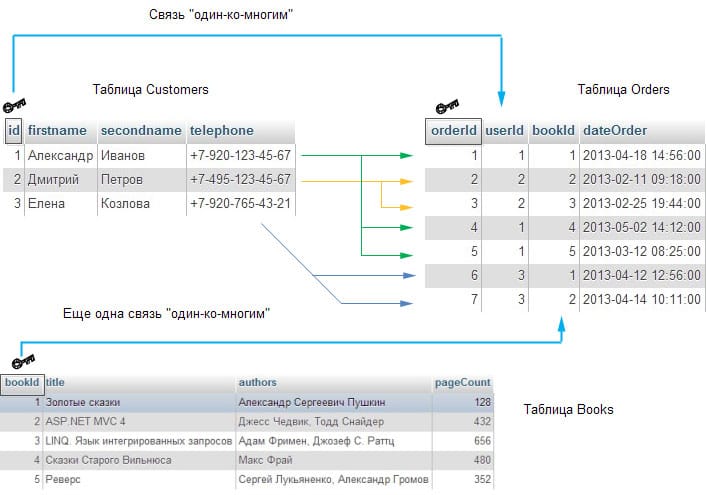
MySQL – это реляционная база данных . Важная особенность реляционных систем, их отличие от одноуровневых баз данных – возможность располагать данные в нескольких таблицах. Взаимосвязанные данные можно хранить в отдельных таблицах и объединять по ключу, общему для обеих таблиц. Ключ – это отношение (relation) между таблицами. Выбор первичного ключа (primary key) – наиболее важное решение, принимаемое при разработке новой базы данных. Самое главное, что следует понимать, – вы должны гарантировать уникальность выбранного ключа. Если есть вероятность того, что значение некоторого атрибута может совпасть у двух записей, то его нельзя использовать в качестве первичного ключа. Если таблица содержит ключевые поля из другой таблицы, то между ними образуется связь – взаимоотношением внешнего ключа (foreign key) , например «начальник-подчиненный» или «покупатель-покупка».
В качестве примера создадим таблицу в базе данных users (мы ее использовали в предыдущей статье) соответствующую, например, книжному интернет-магазину. Выполните следующий SQL-код для создания таблицы и вставки данных:
-- Создадим таблицу customers (покупатели)
CREATE TABLE customers (
id INT NOT NULL AUTO_INCREMENT,
firstname VARCHAR(32),
secondname VARCHAR(50),
address VARCHAR(256),
telephone VARCHAR(20),
bookTitle VARCHAR(256),
bookAuthor1 VARCHAR(64),
bookAuthor2 VARCHAR(64),
pageCount INT(4),
dateOrder DATETIME,
PRIMARY KEY(id)) CHARACTER SET utf8;
-- Наполнить таблицу какими-то данными
INSERT INTO customers VALUES
(1, 'Александр', 'Иванов', 'Ленинский проспект 68 - 34, Москва 119296', '+7-920-123-45-67', 'Золотые сказки', 'Александр Сергеевич Пушкин', '', 128, '2013-04-18 14:56:00'),
(NULL, 'Дмитрий', 'Петров', 'Хавская 3 - 128, Москва 115162', '+7-495-123-45-67', 'ASP.NET MVC 4', 'Джесс Чедвик', 'Тодд Снайдер', 432, '2013-02-11 09:18:00'),
(NULL, 'Дмитрий', 'Петров', 'Хавская 3 - 128, Москва 115162', '+7-495-123-45-67', 'LINQ. Язык интегрированных запросов', 'Адам Фримен', 'Джозеф С. Раттц', 656, '2013-02-25 19:44:00'),
(NULL, 'Александр', 'Иванов', 'Ленинский проспект 68 - 34, Москва 119296', '+7-920-123-45-67', 'Сказки Старого Вильнюса', 'Макс Фрай', '', 480, '2013-05-02 14:12:00'),
(NULL, 'Александр', 'Иванов', 'Ленинский проспект 68 - 34, Москва 119296', '+7-920-123-45-67', 'Реверс', 'Сергей Лукьяненко', 'Александр Громов', 352, '2013-03-12 08:25:00'),
(NULL, 'Елена', 'Козлова', 'Тамбовская - 47, Санкт-Петербург 192007', '+7-920-765-43-21', 'Золотые сказки', 'Александр Сергеевич Пушкин', '', 128, '2013-04-12 12:56:00'),
(NULL, 'Елена', 'Козлова', 'Тамбовская - 47, Санкт-Петербург 192007', '+7-920-765-43-21', 'ASP.NET MVC 4', 'Джесс Чедвик', 'Тодд Снайдер', 432, '2013-04-14 10:11:00');
Теперь, когда у нас есть отдельные таблицы для хранения взаимосвязанных данных, нужно подумать об элементах в каждой таблице, которые будут описывать связи с элементами в других таблицах.
Нормализация
Представление о взаимоотношениях данных и наиболее эффективном способе их организации называется нормализацией . Нормализация заключается в разделении данных на основе логических взаимоотношений с целью минимизировать дублирование данных. Повторяющиеся данные понапрасну расходуют дисковое пространство сервера и затрудняют их обслуживание. При внесении изменений в повторяющиеся данные есть риск пропустить какие-то из них, что может привести к возникновению несогласованностей в базе данных.
С другой стороны, лучшее – враг хорошего: когда данные хранятся по частям в отдельных таблицах, это может потребовать слишком больших накладных расходов на их извлечение, да и запросы могут получаться чересчур замысловатыми. Главная цель – найти золотую середину.
Продолжим пример с книжным интернет-магазином. Сайт магазина должен хранить данные о покупателях, включая имя и фамилию пользователя, адрес и номер телефона, а также информацию о книгах, включая название, автора, количество страниц и дату продажи каждой книги. Изначально мы разместили всю информацию в одной таблице:

Размещение всех данных в одной таблице может показаться заманчивым, однако такой способ приводит к напрасному расходованию пространства в базе данных и делает утомительной операцию обновления данных. С каждой новой покупкой все сведения о покупателе записываются повторно. Для каждой книги можно указать не больше двух авторов. Кроме того, если покупатель переедет и поменяет адрес, это потребует внести изменения в каждую запись, связанную с этим покупателем.
Формы нормализации
Чтобы нормализовать базу данных, начнем с самых главных правил и будем продвигаться вперед шаг за шагом. Процесс нормализации состоит из трех этапов, называемых формами . Первый этап, который называется приведением к первой нормальной форме, должен быть выполнен перед приведением базы данных ко второй нормальной форме. Аналогично, невозможно привести базу данных к третьей нормальной форме, минуя вторую. Процесс нормализации приводит структуру данных в соответствие с тремя нормальными формами.
Первая нормальная форма
Необходимо, чтобы приведенная к первой нормальной форме база данных соответствовала трем требованиям. Ни одна таблица не должна иметь повторяющихся столбцов, содержащих одинаковые по смыслу значения, и все столбцы должны содержать единственное значение. Обязательно должен быть определен первичный ключ, который уникальным образом описывал бы каждую строку. Это может быть один столбец или комбинация из нескольких столбцов, в зависимости от того, сколько потребуется столбцов для обеспечения уникальной идентификации строк.
В созданной нами таблице нарушено требование, предъявляемое к повторяющимся столбцам, потому что в столбцах “bookAuthor1” и “bookAuthor2” хранятся одинаковые по смыслу данные. Это несоответствие надо устранить, в противном случае вам может потребоваться добавить много полей для хранения имен авторов (например, если у книги три автора), что приведет к неоправданному расходу пространства, или может не хватить предусмотренного количества полей для хранения всех имен, если над книгой трудились много авторов. Решение заключается в том, чтобы переместить имена всех авторов в отдельную таблицу, которая будет связана с таблицей книг.
Вторая нормальная форма
Как уже отмечалось, первая нормальная форма снижает избыточность данных в строке. Вторая нормальная форма ликвидирует избыточность данных в столбцах. Нормальные формы получаются последовательно. Для приведения ко второй нормальной форме необходимо, чтобы таблицы уже соответствовали требованиям первой.
Чтобы привести таблицу базы данных ко второй нормальной форме, нужно определить, какие из ее столбцов содержат одни и те же данные для нескольких строк. Такие столбцы нужно поместить в отдельную таблицу, связав ее с первоначальной по ключу. Другими словами, нужно отыскать поля, не зависящие от первичного ключа. Поскольку имена авторов и такие сведения о книгах, как количество страниц, никак не связаны с первичным ключом, идентифицирующем покупателя, выделим эту информацию в отдельные таблицы (это действие будет включать в себя также нормализацию по первой форме, т.к. мы выделяем в отдельную таблицу имена авторов):
-- Создадим новую таблицу books
CREATE TABLE books (
bookId INT NOT NULL AUTO_INCREMENT,
title VARCHAR(500),
authors VARCHAR(1000),
pageCount INT(4),
PRIMARY KEY(bookId)) CHARACTER SET utf8;
-- Заполним таблицу books и столбец bookId таблицы customers
INSERT INTO books VALUES(1, 'Золотые сказки', 'Александр Сергеевич Пушкин', 128),
(NULL, 'ASP.NET MVC 4', 'Джесс Чедвик, Тодд Снайдер', 432),
(NULL, 'LINQ. Язык интегрированных запросов', 'Адам Фримен, Джозеф С. Раттц', 656),
(NULL, 'Сказки Старого Вильнюса', 'Макс Фрай', 480),
(NULL, 'Реверс', 'Сергей Лукьяненко, Александр Громов', 352);
-- Видоизменим таблицу customers удалив избыточные столбцы bookTitle, bookAuthor1, bookAuthor2, pageCount
-- и добавим столбец bookId
ALTER TABLE customers DROP bookTitle, DROP bookAuthor1, DROP bookAuthor2, DROP pageCount, ADD bookId INT(4);
UPDATE customers SET bookId = 1 WHERE id = 1;
UPDATE customers SET bookId = 2 WHERE id = 2;
UPDATE customers SET bookId = 3 WHERE id = 3;
UPDATE customers SET bookId = 4 WHERE id = 4;
UPDATE customers SET bookId = 5 WHERE id = 5;
UPDATE customers SET bookId = 1 WHERE id = 6;
UPDATE customers SET bookId = 2 WHERE id = 7;
Этот код позволяет создать дополнительную таблицу books хранящую данные о книгах. Однако мы еще не выполнили полную нормализацию по второй форме. Можно заметить, что в нескольких строках таблицы customers повторяется информация о пользователях, сделавших несколько заказов. Для приведения ко второй нормальной форме мы определим новую таблицу orders (Заказы):
-- Создадим новую таблицу orders (orderId - идентификатор заказа, userId - идентификатор пользователя, который сделал заказ)
CREATE TABLE orders (
orderId INT NOT NULL AUTO_INCREMENT,
userId INT,
bookId INT,
dateOrder DATETIME,
PRIMARY KEY(orderId)) CHARACTER SET utf8;
-- Видоизменим таблицу customers и добавим данные orders, обратите внимание
-- что проводить нормализацию заполненной базы данных является трудоемкой задачей,
-- поэтому ее нужно проводить на этапе проектирования базы данных
INSERT INTO orders (dateOrder, bookId) SELECT dateOrder, bookId FROM customers;
UPDATE orders SET userId = 1 WHERE orderId = 1;
UPDATE orders SET userId = 2 WHERE orderId = 2;
UPDATE orders SET userId = 2 WHERE orderId = 3;
UPDATE orders SET userId = 1 WHERE orderId = 4;
UPDATE orders SET userId = 1 WHERE orderId = 5;
UPDATE orders SET userId = 3 WHERE orderId = 6;
UPDATE orders SET userId = 3 WHERE orderId = 7;
ALTER TABLE customers DROP dateOrder;
--- Удалить дублирующие данные пользователей из таблицы customers
DELETE c1.* FROM customers AS c1 INNER JOIN customers AS c2 ON c1.telephone = c2.telephone WHERE c1.id > c2.id
--- Сделать id записей подряд идущими
UPDATE customers SET id = 3 WHERE id = 6;
--- Сбросить счётчик для поля id
ALTER TABLE customers AUTO_INCREMENT = 4;
--- Удалить поле bookId в таблице customers
ALTER TABLE customers DROP bookId;
Теперь данные оформлены безупречно. У нас появились отдельные таблицы со сведениями о покупателях (customers), книгах (books) и покупках (orders).
Третья нормальная форма
Если вы завершили приведение к первой и второй нормальным формам, возможно, вам не потребуется ничего больше делать с базой данных, чтобы привести ее к третьей нормальной форме. Для приведения к третьей нормальной форме нужно просмотреть таблицы и выделить данные, которые не зависят от первичного ключа, но зависят от других значений. Пока еще не совсем понятно, как применить это к нашим таблицам. В таблице customers компоненты адреса не имеют прямого отношения к покупателю. Название улицы и номер дома связаны с почтовым индексом, почтовый индекс – с городом и, наконец, сам город – с областью или краем. Третья нормальная форма требует, чтобы каждая такая часть данных была выделена в отдельную таблицу.
Ниже показано, как можно разделить информацию об адресе создав отдельную таблицу addresses:
-- Создадим новую таблицу addresses
CREATE TABLE addresses (
userId INT NOT NULL AUTO_INCREMENT,
city VARCHAR(30),
street VARCHAR(50),
postcode INT(6),
PRIMARY KEY(userId)) CHARACTER SET utf8;
-- Видоизменим таблицу customers и добавим данные в addresses
ALTER TABLE customers DROP address;
INSERT INTO addresses (city, street, postcode) VALUES ('Москва', 'Ленинский проспект 68 - 34', 119296),
('Москва', 'Хавская 3 - 128', 115162),
('Санкт-Петербург', 'Тамбовская - 47', 192007);
С практической точки зрения, вы можете обнаружить, что после приведения к третьей нормальной форме было создано больше таблиц, чем вам хотелось бы иметь в своей базе данных. Поэтому вы должны сами решать, когда остановить процесс нормализации. Хорошо, если ваши данные будут соответствовать, по крайней мере, второй нормальной форме. Цель – избежать избыточности данных, предотвратить их повреждение и минимизировать занимаемое данными пространство. Кроме того, нужно убедиться, что одни и те же значения не хранятся в нескольких местах. В противном случае, когда эти данные изменятся, вам придется обновлять их в нескольких местах, что может привести к повреждению базы данных.
Как вы могли заметить, третья нормальная форма еще сильнее снижает избыточность данных, но ценой простоты их представления и производительности. В нашем примере не приходится ожидать, что информация об адресах будет часто изменяться. Однако третья нормальная форма позволяет снизить риск появления орфографических ошибок в названиях городов и улиц. Поскольку это ваша база данных, вам и определять соотношение между нормализацией, простотой и производительностью.
Типы связей
Взаимоотношения или связи, в базах данных подразделяются на следующие категории:
- связи “один-к-одному”;
- связи “один-ко-многим”;
- связи “многие-ко-многим”.
Мы рассмотрим каждую из этих связей на примере созданной нами базы данных.
Связи “один-к-одному”
При связи “один-к-одному” каждому элементу соответствует один и только один другой элемент. Например, в контексте книжного интернет-магазина связь “один-к-одному” существует между покупателем и адресом доставки. Каждый покупатель должен иметь единственный адрес доставки. Знак ключа рядом с каждой из таблиц на рисунке ниже указывает на поле, которое является ключом для этой таблицы:

Например, чтобы вывести адрес пользователя “Александр Иванов” можно воспользоваться следующей SQL-конструкцией:
SELECT * FROM customers JOIN addresses ON (customers.id = addresses.userid) WHERE customers.id = 1;

Связь “один-ко-многим”
В случае связи “один-ко-многим” каждый ключ из одной таблицы может встречаться несколько раз в другой таблице. Это наиболее распространенный тип связи. Например, у одного покупателя может быть несколько заказов, в то же время каждый заказ имеет свой уникальный идентификатор, но два покупателя могут заказать одну и ту же книгу:
Например, чтобы вывести все заказы пользователя “Александр Иванов” можно воспользоваться следующей SQL-конструкцией:
SELECT * FROM customers JOIN orders ON (customers.id = orders.userid) WHERE customers.id = 1;

Связь “многие-ко-многим”
Связь “многие-ко-многим” возникает между двумя таблицами, когда в каждой из них может присутствовать несколько ключей другой таблицы. Например, покупатель приобретает в интернет-магазине сразу несколько книг. Или одну и ту же книгу приобретают несколько покупателей. На рисунке ниже показана связь “многие-ко-многим” между покупателями и приобретенными книгами:

Чтобы данные со связью “многие-ко-многим” могли быть представлены в базе данных, этот тип связи преобразуется в две связи “один-ко-многим” с помощью таблицы отображения (mapping table). В нашем случае такой таблицей является orders.
Вот таким вот образом у нас и проектируется база данных.
Создание резервных копий и восстановление данных в MySQL
Даже при грамотном администрировании баз данных иногда возникают определенные проблемы. Аппаратный сбой может привести, в частности, к непредсказуемому поведению веб-страниц. Теперь, когда вы работаете с базой данных, простого резервного копирования файлов (HTML, PHP и изображений) на веб-сервере недостаточно. Нет ничего хуже, чем заставлять пользователей своего веб-сайта повторно вводить учетную информацию для регистрации. При наличии полной резервной копии вы сможете оценить разницу между восстановлением за час и повторным изобретением колеса. Мы рассмотрим несколько тактик резервного копирования баз данных.
Копирование файлов базы данных
Вы можете просто копировать файлы базы данных MySQL, как делаете это с файлами HTML и PHP. Если есть возможность создавать резервные копии обычных файлов, точно так же можно создавать резервные копии файлов базы данных MySQL.
Мы не рекомендуем использовать подобный подход при перемещении базы данных с одной машины на другую, поскольку в разных версиях MySQL файлы баз данных могут иметь разные форматы. MySQL сохраняет свои файлы с данными в специальном каталоге, который, как правило, размещается в C:\OSPanel\userdata\MySQL-5.7-x64[имя_базы_данных] в ОС Windows для OpenServer, и в /var/lib/mysql – в различных UNIX-системах, например Linux и Mac OS X. Перед копированием файлов базы данных необходимо остановить работу сервера MySQL, чтобы обеспечить неизменность всех файлов во время копирования.
При создании резервной копии простым копированием файлов базы данных восстанавливать их следует в том же каталоге, откуда они были скопированы. После этого нужно перезапустить базу данных.
Команда mysqldump
Гораздо лучше выполнять резервное копирование с помощью инструмента командной строки MySQL. Это инструмент, позволяющий создать резервную копию и восстановить данные, а также переместить базу данных с одного сервера на другой; утилита mysqldump создает текстовый файл с инструкциями SQL, необходимыми для создания объектов базы данных и вставки данных.
Утилита mysqldump запускается из командной строки и принимает параметры для создания резервной копии единственной таблицы, базы данных и т.п. Лежит эта утилита там же где и консольный клиент mysql и запускается через командную строку. Синтаксис команды:
mysqldump -u пользователь -p объекты_для_резервного_копирования
По умолчанию mysqldump создает и выводит резервную копию на стандартное устройство вывода (обычно это экран). Указанный пользователь должен иметь право на доступ к копируемым объектам. Перед копированием утилита предложит ввести пароль для данного пользователя. Чтобы выполнить копирование в файл, нужно добавить в конец команды символ (>) и указать имя файла.
Ниже мы привели примеры команд, выполняющих резервное копирование базы данных с именем users из командной строки:
mysqldump -u root -p users > my_backup.sql
Данная команда сообщает утилите mysqldump необходимость зарегистрироваться в базе данных с привилегиями пользователя root и создать резервную копию базы данных users. Перед копированием у вас будет запрошен пароль пользователя root, указанный в процессе установки. Результат работы утилиты сохраняется в файле с именем my_backup.sql с помощью оператора перенаправления – символа “больше чем” (>). Ниже показана начальная часть файла my_backup.sql, созданного утилитой mysqldump:
-- MySQL Dump
CREATE DATABASE IF NOT EXISTS users DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
-- ...
CREATE TABLE IF NOT EXISTS `adresses` (
`userId` int(11) NOT NULL AUTO_INCREMENT,
`city` varchar(30) DEFAULT NULL,
`street` varchar(50) DEFAULT NULL,
`postcode` int(6) DEFAULT NULL,
PRIMARY KEY (`userId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
--
-- Дамп данных таблицы `adresses`
--
INSERT INTO `adresses` (`userId`, `city`, `street`, `postcode`) VALUES
(1, 'Москва', 'Ленинский проспект 68 - 34', 119296),
(2, 'Москва', 'Хавская 3 - 128', 115162),
(3, 'Санкт-Петербург', 'Тамбовская - 47', 192007);
-- --------------------------------------------------------
--
-- Структура таблицы `books`
--
CREATE TABLE IF NOT EXISTS `books` (
`bookId` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(500) DEFAULT NULL,
`authors` varchar(1000) DEFAULT NULL,
`pageCount` int(4) DEFAULT NULL,
PRIMARY KEY (`bookId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=6 ;
--
-- Дамп данных таблицы `books`
--
INSERT INTO `books` (`bookId`, `title`, `authors`, `pageCount`) VALUES
(1, 'Золотые сказки', 'Александр Сергеевич Пушкин', 128),
(2, 'ASP.NET MVC 4', 'Джесс Чедвик, Тодд Снайдер', 432),
(3, 'LINQ. Язык интегрированных запросов', 'Адам Фримен, Джозеф С. Раттц', 656),
(4, 'Сказки Старого Вильнюса', 'Макс Фрай', 480),
(5, 'Реверс', 'Сергей Лукьяненко, Александр Громов', 352);
-- ...
В этом сгенерированном коде SQL происходит создание базы данных users (если ее не существует) и генерация таблиц. Пусть вас не смущают символы обратных апострофов (`), которыми окружены имена таблиц и столбцов в примере, использовать их необязательно.
Чтобы создать резервную копию единственной таблицы базы данных, достаточно просто добавить имя таблицы после имени базы данных. Например, следующая команда создает резервную копию таблицы customers:
mysqldump -u root -p users customers > my_backup_customers.sql
Но чаще всего вам понадобится создавать резервную копию всего содержимого базы данных. Это делается с помощью ключа командной строки --all-databases. Результирующий файл содержит команды, необходимые для создания баз данных и пользователей, представляя собой полный снимок базы данных, пригодный для восстановления:
mysqldump -u root -p --all-databases > my_backup.sql
Пустая копия базы данных (только структура) создается с помощью ключа --no-data. Ключ --no-create-info позволяет выполнить противоположную операцию – создать только резервную копию данных. Разумеется, в резервной копии мало проку, если не знаешь, как восстановить из нее базу данных.
Восстановление из резервной копии
Восстановить базу данных из файла, созданного с помощью утилиты mysqldump, достаточно просто. Файл резервной копии – это просто набор инструкций SQL, которые могут исполняться клиентом командной строки mysql и тем самым восстанавливать данные из резервной копии.
Если резервная копия базы данных в файле my_backup.sql создавалась с ключом --all-databases, то восстановить базу данных можно так:
mysql -u root -p < my_backup.sql
Бэкап и восстановление с помощью phpMyAdmin
Не стоит забывать также и о возможности создания резервных копий через phpMyAdmin. Для этого достаточно выбрать интересующую базу данных и перейти во вкладку “Экспорт”.

После того, как вы нажмете кнопку “Далее”, создастся дамп базы данных и скачается прямо через браузер.
Чтобы восстановиться из этой копии, достаточно перейти во вкладку “Импорт” и выбрать созданный при экспорте файл.
phpMyAdmin имеется на большинстве хостингов и его очень удобно использовать при выкладке сайта в Интернет, или при переезде с одного хостинга на другой.
Индексы в базе данных MySQL
В следующих трёх статьях мы познакомимся с концепциями, которые, строго говоря, не являются необходимыми для создания веб-сайтов, но могут помочь повысить производительность и придать запросам большую гибкость.
Индексы в базе данных играют ту же роль, что и алфавитный указатель в книге. Если вы попытаетесь найти в книге слова CREATE TABLE без алфавитного указателя, то сначала вам придется просмотреть значительное число страниц, чтобы обнаружить подходящий раздел. Затем необходимо просмотреть весь раздел. При таком способе очень неэффективно расходуется время – ваше или базы данных. Решение этой проблемы заключается в том, чтобы добавить индексы.
Данные в индексах отсортированы и организованы таким образом, что позволяют находить требуемое значение настолько быстро, насколько это возможно. Поскольку значения отсортированы, база данных может прекратить поиск, обнаружив значение, превышающее искомое.
Однако эта проблема имеет и обратную сторону. Если индексы так хороши, почему бы не индексировать все подряд? Есть несколько причин, которые можно привести против такого решения:
- пространство, выделяемое под индексы, ограничено;
- даже в обычных книгах создание и обслуживание гигантских всеобъемлющих алфавитных указателей очень неэффективно;
- слишком большой объем данных в индексах приводит к увеличению времени чтения индексов при выборке данных.
Таким образом, решение о полях, включаемых в индексы, должно быть обоснованным. При исполнении простейшей инструкции SELECT (без инструкции WHERE) индексы не задействуются. Индексы используются в трех основных ситуациях:
- Вместе с оператором WHERE - например, для выполнения запроса SELECT * FROM customers WHERE firstname = ‘Elena’; будет использован индекс по полю firstname (если он существует).
- Вместе с оператором ORDER BY - например, для выполнения запроса SELECT * FROM orders ORDER BY dateOrder; будет использован индекс по полю dateOrder (если он существует).
- Вместе с операторами MIN и MAX - например, для поля, передаваемого функции MIN или MAX, определен индекс.
Просто запомните: индексы должны быть определены до того, как они будут использоваться. Можно определить индексы для базы данных в команде CREATE TABLE либо создать их позже, для уже существующих таблиц, с помощью специальных команд SQL. Если определение индекса является частью команды CREATE TABLE, оно указывается в конце блока кода, например так:
UNIQUE customers(firstname)
Команда UNIQUE создает индекс для поля с именем firstname. Тот же самый индекс можно создать с помощью специальной инструкции SQL, как показано ниже:
CREATE UNIQUE INDEX authind ON customers (firstname);
Попробуем получить описание таблицы customers:
DESCRIBE customers;
Результат:
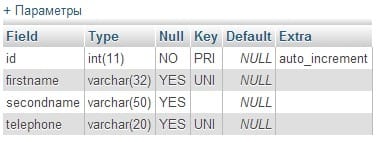
Обратите внимание на новое значение UNI в столбце key для поля firstname.
В MySQL можно создавать индексы, состоящие из нескольких столбцов (на приведенном выше рисунке уникальные индексы имеют столбцы firstname и telephone). Такие составные индексы позволяют обеспечить уникальную комбинацию двух или больше полей. Наилучшими кандидатами в индексы являются поля, которые с большой долей вероятности будут участвовать в конструкции WHERE. А если вы точно знаете, какие комбинации ключей будут использоваться, то они станут наилучшими кандидатами для построения индексов, состоящих из нескольких столбцов.
Первыми в определении индекса должны следовать поля, которые используются наиболее часто. MySQL задействует составные индексы даже в том случае, если в запросе указано только первое значение, входящее в состав индекса. Уникальные индексы сродни первичному ключу, который также является уникальным. Но для каждой таблицы может быть определен только один первичный ключ. А уникальных индексов вы можете завести столько, сколько пожелаете.
Расширенная выборка данных
Мы уже рассматривали способ соединения таблиц в инструкции SELECT с помощью инструкции WHERE, но есть и другой способ соединения таблиц. Если заменить ключевое слово WHERE словом LEFT JOIN ON, то будет выполнено левое, или внешнее соединение (outer join).
Левое соединение позволяет произвести запрос к двум таблицам, между которыми есть связь, но при этом для одной из таблиц возвращаются записи, даже если они не соответствуют записям в другой таблице. На примере наших таблиц можно было бы построить запрос, который возвращал бы список не только покупателей с их покупками, но и покупателей, которые не сделали ни одной покупки.
Синтаксис:
SELECT поля FROM левая_таблица
LEFT JOIN правая_таблица
ON левая_таблица.поле_связи = правая_таблица.поле_связи;
Выбранные из базы данных строки можно сгруппировать и выполнить над сгруппированными данными некоторые действия, например вычислить среднее значение или подсчитать сгруппированные строки. Столбец (или столбцы), по которому будет производиться группировка, определяется с помощью инструкции GROUP BY. Следующий запрос выведет число заказов для каждой книги:
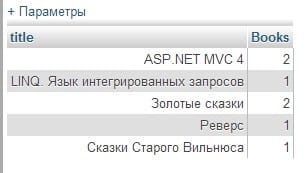
SELECT b.title, COUNT(orderId) "books" FROM books b, orders o WHERE b.bookId = o.bookId GROUP BY title;
Результат исполнения запроса:
В таблице ниже приведен перечень функций, используемых с инструкцией GROUP BY:
Функции для работы со сгруппированными данными
| Функция | Действие, выполняемое над сгруппированными данными |
|---|---|
| COUNT() | Подсчет количества строк |
| SUM() | Подсчет суммы значений |
| AVG() | Вычисление среднего значения |
| MIN() | Определение минимального значения |
| MAX() | Определение максимального значения |
Эти функции можно использовать в запросе и без инструкции GROUP BY. В этом случае все полученные данные рассматриваются как принадлежащие одной группе.
Функции базы данных MySQL
Как и в PHP-сценариях, в запросах к базе данных MySQL можно использовать функции. Мы рассмотрим несколько категорий, начиная с функций для работы со строками. Другие крупные категории, о которых вы узнаете, – это функции для работы с датой и временем.
Функции для работы со строками
Поскольку очень часто приходится работать со строками, MySQL предоставляет множество функций для решения разнообразных задач. Обычно строковые функции используются для работы с данными, возвращаемыми запросом. Но их можно задействовать, даже не ссылаясь на какие-либо таблицы.
В языке PHP объединение строк выполняется с помощью оператора точки (.); в MySQL есть аналогичная функция CONCAT, объединяющая строковые значения полей. Например, функция CONCAT позволяет вернуть единственное поле, соединяющее в себе имя покупателя и его номер телефона:
SELECT CONCAT ('Пользователь: ', firstname, ' ', secondname, ' , телефон: ', telephone) FROM customers;
Этот запрос вернет:
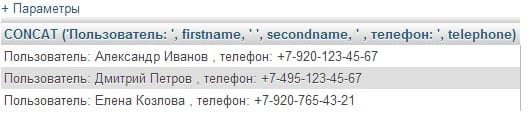
Результатом конкатенации будет строка, готовая к отображению прямо из запроса SQL.
Имя поля, указываемое в качестве параметра функции, не нужно заключать в одиночные или двойные кавычки. Иначе MySQL примет его за литеральное значение. Функция CONCAT объединит столько полей, сколько вы ей зададите.
Иногда соединяемые при конкатенации поля разделяют некоторым символом. Это может потребоваться, например, при экспортировании таблиц. В таком случае следует применять функцию CONCAT_WS . Например, следующий запрос позволяет получить значения всех полей таблицы customers, разделенные запятыми:
SELECT CONCAT_WS(',', *) FROM customers;
В качестве символа-разделителя можно использовать пробел, что удобно для объединения имени и фамилии в единую строку, готовую к отображению.
Функции для работы с датой и временем
В языке PHP есть функции для работы с датой и временем, но как быть, если понадобилось запросить список покупок за последние 30 дней? Было бы замечательно иметь возможность выполнять арифметические операции над датой и временем прямо в запросах. В MySQL есть функции для подобной работы, применяемые как к значениям из таблиц базы данных, так и без упоминания таблиц в запросах. Мы продемонстрируем оба способа в следующих примерах.
Дни, месяцы, годы и недели
Бывает трудно припомнить, глядя на дату, – вторник это был или четверг. В MySQL есть функции, позволяющие мгновенно ответить на подобные вопросы. Это очень удобно! Функции для подобных расчетов присутствуют и в PHP.
Функция WEEKDAY принимает дату в качестве аргумента и возвращает число. Это число означает день недели: понедельнику соответствует 0, вторнику – 1 и т.д. Есть и аналогичная функция DAYOFWEEK, которая, по смутным предположениям, должна делать то же самое, но нумерует дни недели иначе – начиная с воскресенья, которому соответствует число 1. В примере ниже показано, как с помощью функции WEEKDAY определяется день недели, соответствующий 12 апреля 1961 года:
SELECT WEEKDAY('1961-04-12');
Этот запрос вернет число 2, таким образом, 12 апреля 1961 года была среда. Число вместо дня недели может показаться несколько странным, но в MySQL есть и функция, которая возвращает название дня недели (на английском) - DAYNAME.
Есть еще функции DAYOFMONTH и DAYOFYEAR , аналогичные функции DAYOFWEEK. Они получают дату в качестве аргумента и возвращают число. Функция DAYOFMONTH возвращает число месяца, а функция DAYOFYEAR – количество дней, прошедших с начала календарного года. Есть функция MONTHNAME, аналогичная функции DAYNAME, которая возвращает название месяца.
Если вам потребуется отыскать номер недели в году для определенной даты, можно использовать функцию WEEK . Она принимает в качестве аргумента дату и возвращает номер недели в году.
Часы, минуты и секунды
При работе с такими типами данных, как datetime, timestamp или time, в поле сохраняется указанное время. В MySQL есть несколько функций для работы с этим временем. Их имена вполне логичны: HOUR , MINUTE и SECOND . Функция HOUR принимает в качестве аргумента время и возвращает число часов в диапазоне от 0 до 23. Функция MINUTE возвращает число минут в диапазоне от 0 до 59, аналогично, функция SECOND возвращает число секунд в том же диапазоне.
MySQL предоставляет функции DATE_ADD и DATE_SUB , позволяющие складывать и вычитать даты. Их синтаксис:
DATE_ADD(дата, INTERVAL выражение тип)
DATE_SUB(дата, INTERVAL выражение тип)
Например, если вы захотите найти дату, которая была 12 дней тому назад, можете воспользоваться запросом из примера:
SELECT DATE_SUB(NOW(), INTERVAL 12 day);
Дата, которую вернет этот запрос, зависит от того, когда вы его выполните. Начиная с версии 3.23, MySQL поддерживает синтаксис операторов (+) и (-) для работы с датами, как показано ниже:
-- Результат будет аналогичен предыдущему
SELECT NOW() - INTERVAL 12 day;
Функция NOW возвращает текущие дату и время согласно системным часам вашего компьютера (или сервера). Но если часы показывают неверную дату, то и функция NOW вернет ошибочную дату. В MySQL есть несколько функций, возвращающих текущую дату, время или текущую дату и время одновременно. Функции CURDATE и CURRENT_DATE возвращают текущую дату в формате ‘YYYY-MM-DD’. Функции CURTIME и CURRENT_TIME возвращают текущее время в формате ‘HH:MM:SS’.
Транзакции в MySQL
Транзакция – это механизм, который позволяет интерпретировать множественные изменения в базе данных как единую операцию. Либо будут приняты все изменения, либо все они будут отвергнуты. Ни из какого другого сеанса невозможно получить доступ к таблице, пока есть открытая транзакция, в рамках которой выполняются какие-либо изменения в этой таблице. Если вы в своем сеансе попробуете сделать выборку данных сразу же после их изменения, все выполненные изменения будут доступны.
Такой механизм базы данных с поддержкой транзакций, как InnoDB или BDB, начинает транзакцию по команде start transaction. Завершается транзакция при подтверждении или отмене изменений. Завершить транзакцию можно двумя командами. Команда commit сохраняет все изменения в базе данных. Команда rollback отменяет все изменения.
В примере ниже создается таблица с поддержкой транзакций, в нее вставляются данные, затем запускается транзакция, в рамках которой данные удаляются, и в заключение выполняется откат транзакции (отмена удаления):
CREATE TABLE sample_innodb (
id int(11) NOT NULL auto_increment,
name varchar(150) default NULL,
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO sample_innodb VALUES
(1, 'Александр'),
(2, 'Дмитрий');
start transaction;
DELETE FROM sample_innodb WHERE id = 1;
DELETE FROM sample_innodb WHERE id = 2;
rollback;
Поскольку произошел откат транзакции, данные из таблицы не были удалены.
А если бы вместо rollback мы написали commit, то обе строки были бы удалены.
Транзакции требуются тогда, когда нужно чтобы несколько запросов точно применились и выполнились “одновременно”, либо не выполнился ни один из них, если что-то пойдёт не так.
В качестве примера можно привести систему оплаты на каком-то сайте. В момент покупки заказ должен быть помечен как оплаченный, и вместе с этим, одновременно нужно списать деньги с баланса пользователя. Если что-то одно не выполнится - будет либо пользователь без купленного товара и без денег, либо магазин без товара и без денег. А с помощью транзакций мы можем такого запросто избежать.
Взаимодействие PHP и MySQL
После установки и настройки базы данных MySQL можно приступать к написанию сценариев PHP для взаимодействия с базой данных. В настоящей статье приведено описание всех основных функций, позволяющих передавать данные в прямом и обратном направлениях от веб-сайта к базе данных.
Неважно, насколько простые или сложные у вас сценарии, если они общаются с базой данных, они начинаются с одних и тех же нескольких действий:
- Подключение к установленной базе данных MySQL.
- Использование команды USE в отношении нужной базы данных MySQL.
- Отправка SQL базе данных.
- Получение результатов.
- Обработка результатов.
Действия 3, 4 и 5 будут изменяться в зависимости от характера выполняемой работы. Сценарий, создающий таблицы, немного отличается от сценария, который ведет поиск в существующих таблицах. Но первые два действия — подключение к MySQL и использование нужной базы данных — всегда одни и те же, независимо от предназначения сценария.
Подключение к базе данных MySQL
Сначала нужно сообщить вашему PHP-сценарию, как нужно подключиться к базе данных. Этот процесс, по сути, сообщает PHP, что нужно делать то же самое, что вы выполняли, начиная работу со своим клиентом командной строки MySQL. Чтобы подключиться к базе данных, PHP нужно будет передать следующую информацию: имя хоста вашей базы данных, имя пользователя, пароль и имя базы данных.
Для подключения к базе данных мы будем использовать PDO - PHP Data Objects. При его использовании можно не бояться SQL-инъекций, это возможно благодаря подготовленным параметрам, но об этом чуть позже.
Это важно! Если в интернете вы найдёте урок, где будет использоваться mysqli_connect или mysql_connect - смело закрывайте его, так писали 10 лет назад.
Для создания подключения нужно создать новый объект класса PDO. В качестве аргументов в конструктор нужно передать DSN - это строка с указанием драйвера (в нашем случае - mysql), хоста и именем базы данных. Второй аргумент - имя пользователя (в нашем случае - root). Третий - пароль (в наше случае пустой).
Перед уроком я создал базу users, а в ней табличку data со следующей структурой:
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,,
`name` varchar(32) DEFAULT NULL,
`year` char(4) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
$dbh = new \PDO(
'mysql:host=localhost;dbname=users;',
'root',
''
);
Первым делом после подключения стоит задать кодировку:
$dbh->exec("SET NAMES UTF8");
После этого мы можем выполнять запросы. Выглядит это так:
$stm = $dbh->prepare('INSERT INTO data (`name`, `year`) VALUES (:name, :year)');
$stm->bindValue('name', 'Имя');
$stm->bindValue('year', '1703');
$stm->execute();
Сначала мы создаём подготовленный запрос - он пока не выполняется. Заметьте, вместо значений мы указали :name и :year - это те параметры, в которые подставятся значения, заданные в следующих двух строках. В конце мы вызываем execute() - собственно, выполнить получившийся запрос.
Давайте выполним этот скрипт и посмотрим на то, что появилось в базе.
Давайте обновим скрипт ещё несколько раз и посмотрим в базу снова.
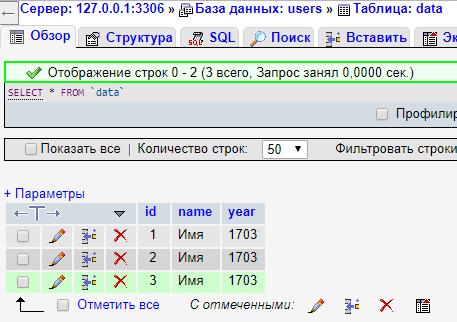
Как видим - данные в базе успешно добавились.
Выборка из базы с помощью PHP
Давайте теперь прочитаем данные, которые мы записали. Схема та же, только подготавливаем SELECT-запрос.
$stm = $dbh->prepare('SELECT * FROM `data`');
$stm->execute();
Запрос выполнился, но это ещё не всё. Теперь нужно получить результат. Это делается так:
$allUsers = $stm->fetchAll();
var_dump($allUsers);
В результате мы получим массив этих записей:

Давайте выведем их более красиво, добавим немножко HTML.
$stm = $dbh->prepare('SELECT * FROM `data`');
$stm->execute();
$allUsers = $stm->fetchAll();
?>
<table border="1">
<tr><td>id</td><td>Имя</td><td>Год</td></tr>
<?php foreach ($allUsers as $user): ?>
<tr>
<td><?= $user['id'] ?></td>
<td><?= $user['name'] ?></td>
<td><?= $user['year'] ?></td>
</tr>
<?php endforeach; ?>
</table>
Ну вот, совершенно другое дело!
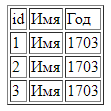
Если в SELECT-запросе нужно добавить какие-то параметры, то делается это аналогично:
$stm = $dbh->prepare('SELECT * FROM `data` WHERE id = :id');
$stm->bindValue('id', 1);
$stm->execute();
$users = $stm->fetchAll();
var_dump($users);
Теперь вернётся только один пользователь, подошедший под условия запроса.

Вот и всё. Главное - всегда используйте биндинг параметров. Не пихайте данные напрямую в запрос - это небезопасно. Если интересно, можете почитать про SQL-инъекции.
Базы данных и веб-формы
Возможности обработки форм относятся к числу наилучших средств языка PHP. В основе решения всевозможных задач лежит использование языка HTML для создания форм ввода данных, языка PHP — для обработки данных, а сервера базы данных — для хранения данных.
В статьях “GET-запросы в PHP” и “Обрабатываем POST-запросы в PHP” мы уже рассмотрели как передаются данные формы серверу (с помощью методов GET и POST) и создали пару простых сценариев обработки форм без использования баз данных. В этой статье мы усложним примеры и добавим работу с базами данных, при этом нужно учитывать следующие сведения при обработке веб-форм:
- Необходимо соблюдать исключительную осторожность при использовании любых данных, поступающих из веб-браузера посетителя. Может показаться, что такая рекомендация и без того очевидна, но на практике все еще встречается слишком много программ PHP, в которых не подвергаются проверке и очистке данные, поступающие из веб-форм или веб-браузеров (или тому подобных программных объектов). Никогда не используйте нефильтрованные данные в запросе к базе данных.
- Следует всегда использовать атрибут name каждого элемента ввода данных (<input>, <select>, <textarea> и т.д.). Такие атрибуты name становятся именами ассоциативного массива (например, $_POST). Это означает, что в программе нельзя будет получить доступ к требуемым значениям, если для каждого элемента, хранящего значение, не задан атрибут name.
- Атрибут name поля формы не обязательно должен совпадать с соответствующим именем поля базы данных.
- Если в форме требуется отобразить данные, то можно задать значение атрибута value.
- Помните, что от одной формы (или страницы) к другой можно передавать скрытые переменные с помощью элементов ввода данных hidden. Применение такого подхода оказывает отрицательное влияние на уровень защищенности данных, поэтому им нельзя руководствоваться при обработке конфиденциальных данных. Кроме того, следует всегда тщательно проверять данные, полученные в элементе hidden - не стоит рассчитывать на то, что полученные данные в любом случае будут полностью соответствовать ожиданиям.
Ввод данных в базу данных с помощью передачи простой формы
Задача ввода данных в базу данных путем передачи формы HTML решается просто, если форма и обработчик формы находятся на двух отдельных страницах. В примере ниже приведена несложная форма, содержащая только одно поле ввода:
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8">
<title>Основы PHP и MySQL</title>
<style>
* { font-family:Calibri }
</style>
</head>
<body>
<h1>Форма подписки на новости сайта</h1>
<p>Введите адрес электронной почты, и мы вышлем вам нашу еженедельную рассылку: </p>
<form action="handler.php" method="post">
<input type="text" name="email" placeholder="E-mail адрес">
<input type="submit" value="Отправить">
</form>
</body>
</html>
Вот такая у нас получилась форма.

Ввод данных в базу данных и подготовка сообщения с подтверждением приема выполняются в обработчике формы (form handler), приведенном ниже, которому присвоено имя handler.php (здесь предполагается наличие базы данных users, которую мы создавали в статье “Взаимодействие PHP и MySQL”):
CREATE TABLE newsletter (
id INT AUTO_INCREMENT,
email VARCHAR(128),
PRIMARY KEY(id));
Ну а теперь сам код обработчика:
<?php
$dbh = new \PDO(
'mysql:host=localhost;dbname=users;',
'root',
''
);
$dbh->exec("SET NAMES UTF8");
?>
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8">
<title>Основы PHP и MySQL</title>
<style>
* { font-family:Calibri }
</style>
</head>
<body>
<?php
// Фильтрация входных пользовательских данных обязательна!
$email = filter_input(INPUT_POST, 'email', FILTER_VALIDATE_EMAIL);
if ($email !== false) {
$stm = $dbh->prepare('INSERT INTO newsletter(email) VALUES (:email)');
$stm->bindValue('email', $email); // Параметризованные запросы - обязательны!
$result = $stm->execute(); // true/false, в зависимости от успешности запроса
if ($result)
echo '<h1>Спасибо за подписку</h1>';
else
echo '<p>Что-то пошло не так</p>';
}
?>
Вот и всё. Рекомендую теперь ознакомиться самостоятельно с функциями filter_input и filter_var и с понятиями фильтрация и санитация .
Что делать после изучения MySQL
В этой статье мы поговорим о том, что можно дальше делать специалисту, изучившему основы MySQL.
Вообще говоря, я вижу всего два пути:
- продолжать углублять свои знания в области баз данных и пробовать начать работать именно как специалист баз данных. Этот вариант подходит, если вам не интересно программировать, но интересно работать с данными, строить сложные отчеты и тому подобное.
- начать применять знания о MySQL для работы с базой, используя языки программирования. Этот вариант подойдёт тем, кто изучает MySQL чтобы использовать его в качестве хранилища при работе из PHP. Тогда вам стоит переходить к продвинутому курсу PHP, в котором мы изучаем ООП и учимся работать с базами данных в современном стиле.
Вот в общем-то и всё, что можно делать дальше. Я для себя выбрал второй вариант и считаю его более привлекательным